
Desde su nacimiento, la profesión de SEO ha estado ligada de manera indisociable a todo tipo de investigaciones, pruebas y estudios. Incluso podemos decir que cuestionar, probar, estudiar y romper las leyendas urbanas forma parte del ADN de cualquiera que se dedique al SEO. Sin embargo, debe hacerse con inteligencia y según las reglas del arte.
Les dejo la presentación y la grabación de mi charla en el Maratón SEO de SE Ranking sobre los Tests SEO: Tipología y metodología de implementación.
En esta primera parte de la presentación se discutirán diferentes aspectos de la investigación SEO, incluyendo los tipos de investigaciones, la correcta realización de los estudios, las metodologías, así como diversos sesgos que pueden arruinar fácilmente el trabajo y algunos aspectos éticos.
En la segunda parte, veremos cómo funcionan las acciones en la práctica en una selección de 5 pruebas, estudios reales y concretos.
Había una vez en 2016…
Para empezar, retrocedamos 5 años…
Así fue el 2016, un año lleno de eventos: Copa de Europa de fútbol en Francia, Donald Trump elegido presidente de los Estados Unidos… Pero una de las noticias que probablemente más marcó el mundo digital fue el lanzamiento de Google Assistant por parte del gigante de Mountain View.
La fiebre por estas nuevas tecnologías de voz fue impresionante: la gente aprendió a interactuar con las nuevas herramientas y dispositivos enviándoles órdenes y bombardeándolos con preguntas (obviamente inteligentes).
Y, naturalmente, nos preguntamos por el futuro de estos nuevos dispositivos y su futura influencia en nuestro comportamiento digital. Pero ni Google ni Amazon se apresuraron a compartir sus cifras y proyecciones.
Y llegó, el 25 de abril de 2016, la revista británica Campaignlive.co.uk publica el artículo “Just say it: The future of search is voice and personal digital assistants” en el que se citan los resultados de un estudio de una empresa estadounidense que anuncia que “en 2020 el 50% de las búsquedas se harán por voz”.

Fuente : Campaignlive.co.uk
Este artículo fue un gran éxito. Fue mencionado por Forbes, Inc, Entrepreneur, Deloitte, Search Engine Journal y muchos otros. Según los datos de MajesticSEO, la página del artículo recibió enlaces de más de 2,000 sitios de terceros, ¡y no se trata de cualquier sitio!
Estas cifras del “50% para 2020” se han convertido en una parte integral de cada conferencia, licitación, auditoría SEO, dondequiera que haya la más mínima mención a la búsqueda por voz.
Cuando llegamos en 2020, empezamos a hacer una pregunta más que lógica: ¿Y dónde estamos hoy con esta proyección?
Ante la falta de movimiento en este tema, el consultor SEO australiano Brody Clark planteó la pregunta directamente a Comscore y quedó más que sorprendido por la respuesta. La empresa contestó que el estudio no provenía de ellos, sino que probablemente se trataba de una entrevista concedida en 2014 por Andrew Ng, en aquel momento el Chief Data Scientist de Baidu.
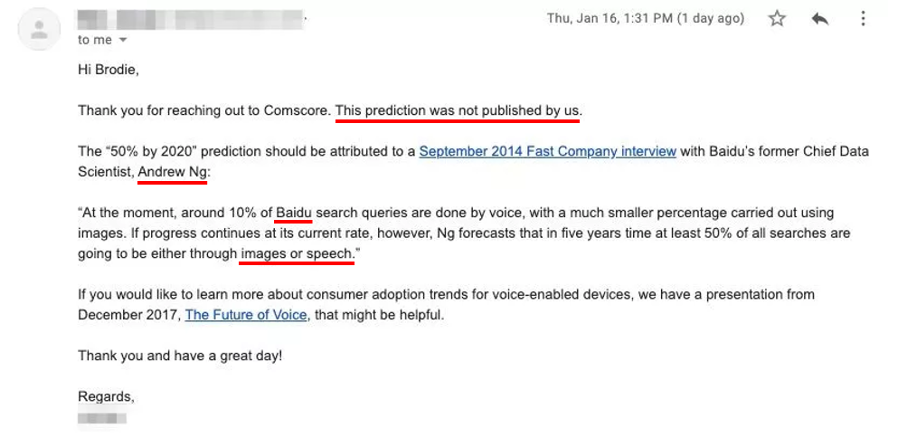
Fuente : brodieclark.com
Aparte de que no existía ningún estudio, al leer la entrevista en cuestión se descubre que la proyección del “50% hasta 2020” era para el motor de Baidu y no para todo el mundo, y contemplaba no sólo la búsqueda por voz sino también la de imágenes. En resumen, proyecciones en todos los aspectos.
Pero, ¿cómo es que el mundo entero lo creyó?
Para mi, hay algunas razones importantes:
- En primer lugar, era un tema de tendencia sobre el que la gente buscaba más información.
- En segundo lugar, había una extrema escasez de estadísticas de uso de la búsqueda por voz (que simplemente no existían en ese momento).
- Por último, una avalancha de backlinks desde fuentes de autoridad (es difícil resistirse a no compartir cuando todos los grandes actores digitales lo hacen).
Pero también hay una razón más profunda que consiste en que por defecto, tendemos a creer en los estudios.
Nos gusta el término “estudio”, nos gusta cuando los datos son objetivos, basados en data y números, incluso sin prestar atención a la metodología utilizada. Nos llamará mucho más la atención un titular como “El 50% de las búsquedas serán móviles en 2020” que “La mayoría de las búsquedas serán pronto móviles”.
¿Por qué hay que investigar en SEO?
La investigación y los estudios son una parte integral de cualquier negocio y el SEO no es una excepción.
De hecho, de todas las profesiones digitales, es la que probablemente más se enfrenta a todo tipo de incertidumbres, falta de información, leyendas urbanas por
- La caja negra del algoritmo de Google: si quieres trabajar eficazmente en el SEO, tienes que entender cómo funciona el algoritmo de Google, que se mantiene en el más absoluto secreto.
- El algoritmo que se vuelve más complejo cada año: aunque hayamos logrado comprender ciertas facetas del algoritmo de clasificación, éste puede y seguramente cambiará de un día para otro.
- La documentación es concisa y obedece a los intereses de Google: aunque muchos elementos sean descritos por los equipos de Google en la documentación, ésta no puede considerarse imparcial porque está determinada por lo que el motor quiere decir.
- La comunicación de Google no siempre es perfecta: el ejemplo más elocuente es la historia de los atributos “rel=prev” y “rel=next”, que durante una sesión de preguntas y respuestas con los portavoces de Google se mencionaron como técnicas que no han funcionado durante mucho tiempo, lo que no era el caso.
- La inestabilidad y la volatilidad de los resultados: las posiciones, los enlaces, las páginas indexadas, la intención de las palabras clave y las tendencias de búsqueda suben y bajan de forma constante.
Tipología de los estudios de SEO
Si analizamos los estudios de SEO realizados en los últimos años, surgen algunas tendencias en cuanto a los tipos de búsqueda más comunes.
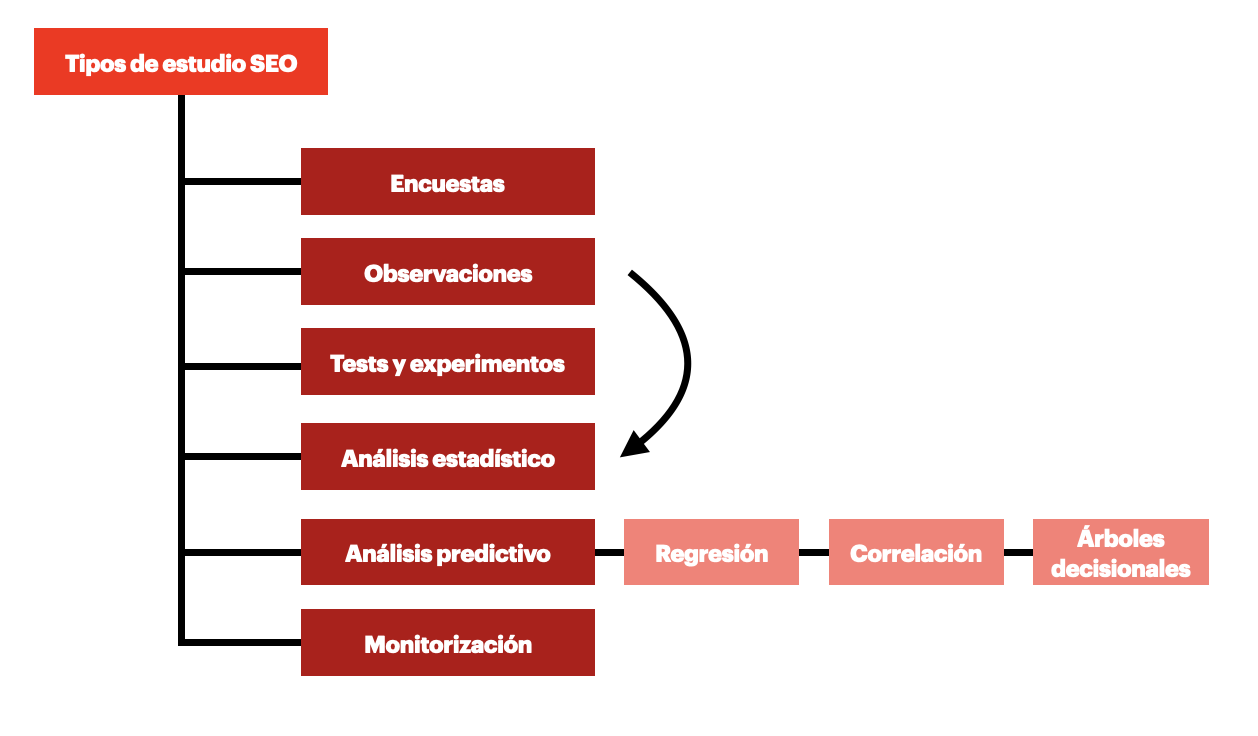
1. Encuestas
Una encuesta es un tipo de estudio bastante común en el mundo del SEO y se basa en el viejo principio “la multitud sabe más” o con una formulación más políticamente correcta “la mayoría no se equivoca”.
Se trata de un tipo de investigación especial, ya que es 100% subjetiva y no representativa. Para contrarrestar este problema, los creadores de encuestas intentan seleccionar con cuidado a una serie de expertos para entrevistarlos, pero en todos los casos se trata de su opinión, su sentimiento, su intuición, su experiencia.
Algunos ejemplos de encuestas de SEO:
- 2020 Google Search Survey: How Much Do Users Trust Their Search Results ? (Moz)
- Search Engine Ranking Factors 2015 (Moz)
- What Matters Now in SEO & Where to Focus Next Survey Results (Search Engine Journal)
2. Observaciones
La observación es el tipo de investigación más sencillo y, al mismo tiempo, el menos fiable.
Por ejemplo, al añadir un vídeo en una página, se observa que la página aumenta en términos de posiciones en las palabras clave objetivo. ¿Significa que Google valora más las páginas con vídeos? Es posible, pero para confirmar esta observación tenemos que volver a verla en otros ejemplos con la misma metodología y el mismo entorno.
Las observaciones suelen ser las fuentes de las hipótesis y el origen de los estudios más profundos.
3. Tests y experimentos
Las pruebas y los experimentos son investigaciones empíricas destinadas a confirmar/infirmar/investigar un fenómeno específico.
La mayoría de las veces, su principio se resume en “acción – reacción”, es decir, creamos algo, aplicamos un cambio, esperamos y medimos la evolución del criterio elegido.
Las pruebas pueden realizarse en entornos cerrados (páginas, directorios, sitios conocidos sólo por la persona que realiza la prueba) así como abiertos (pruebas en páginas públicas). Detallaré estos puntos un poco más adelante.
4. Análisis estadístico
El análisis estadístico consiste en tomar una hipótesis u observación y recoger suficientes datos para validarla o no.
- Por ejemplo, si queremos confirmar el impacto positivo de añadir un vídeo a la página, repetiremos la prueba en una muestra de otras 10-20 páginas (en las mismas condiciones).
- O bien, si queremos comprobar la influencia del texto de la página en la visibilidad SEO de las imágenes de esa misma página, recuperaremos los 100 primeros resultados de búsqueda de Google Imágenes sobre 500-1000 palabras clave, mediremos el tamaño del texto en cada una de las páginas y agregaremos los datos recibidos en una gráfica:
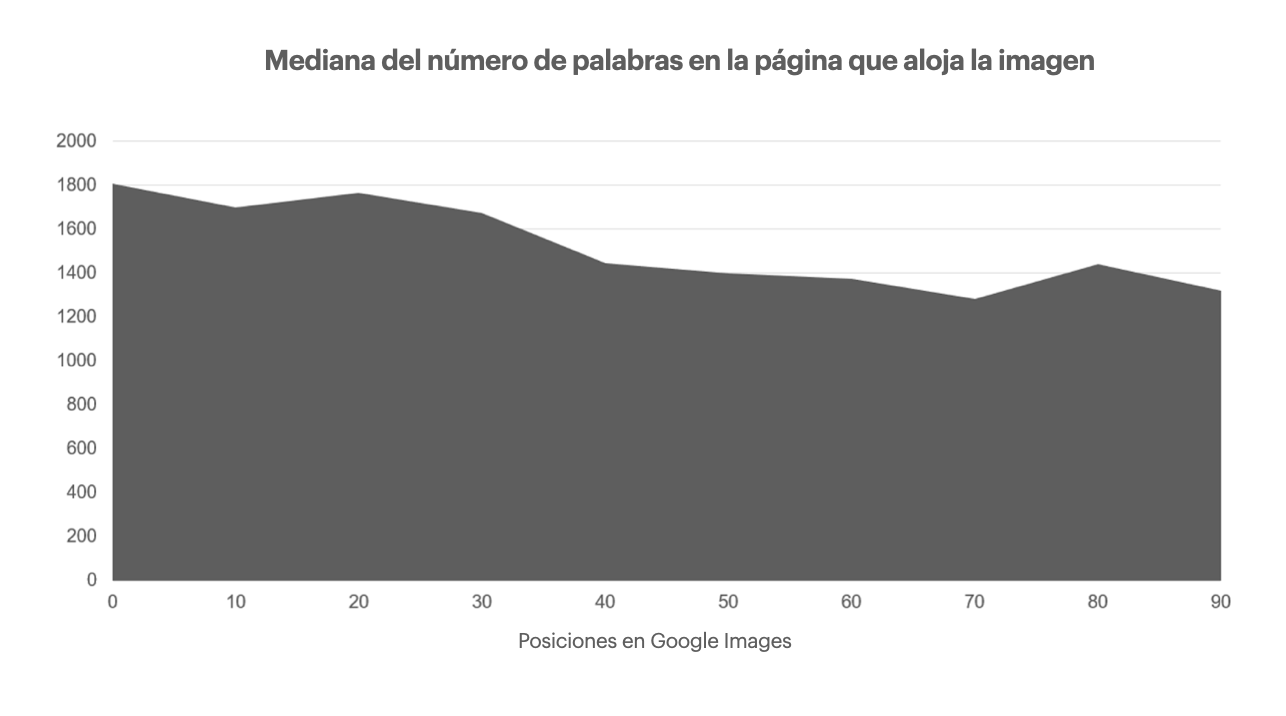
5. Análisis predictivo
En los últimos años, los estudios de predicción SEO han cobrado un nuevo impulso. Si antes se limitaban a predecir las tendencias de la audiencia, hoy se interesan cada vez más por los factores de clasificación.
Para esta tarea de predicción, existen diversos métodos y enfoques de ciencia de datos. Entre ellos se encuentran la regresión y las correlaciones para las tendencias lineales, y los modelos de machine learning basados en árboles decisionales para las tendencias más complejas y no lineales.
Ejemplos de estudios de predicción:
- Searchmetrics 2018 Ranking Factors (algoritmo utilizado: Correlación de Spearman)
- Moz Ranking Correlation Study 2015 (algoritmo utilizado: Correlación de Spearman)
- SEMRush Ranking Factors 2017 (algoritmo utilizado: Random Forest)
6. Monitorización
El último tipo de investigación es el seguimiento. Consiste en identificar los criterios de medición previos y seguir su evolución en el tiempo.
Puede tratarse de la monitorización del índice de aparición de determinados tipos de resultados en Google (pack local, featured snippets, etc.), de la monitorización de las páginas lentas frente a las rápidas, de las páginas con contenido correcto pero rellenas de palabras clave (keyword stuffing), etc.
La monitorización permite añadir claridad sobre los cambios en Google.
Acá vemos un ejemplo de seguimiento de la longitud de los títulos en los resultados de Google mediante la herramienta Rank Ranger. Esta es una de las herramientas que fue de las primeras en detectar la actualización relacionada con la reescritura de títulos de Google):
¿Qué datos utilizar para la investigación?
Para todos los tipos de investigación -excepto las encuestas- necesitamos datos, porque una de las cosas que hace valiosa a la investigación es su naturaleza factual, objetiva y data-driven (basada en datos).
En general, hoy en día no tenemos ninguna dificultad para encontrar datos: cada vez hay más herramientas que nos proporcionan multitud de datos continuamente. Sin embargo, no todos los datos tienen el mismo nivel de precisión y fiabilidad.
En primer lugar, lo que nos interesa es su procedencia. ¿Viene directamente de Google o lo proporcionan herramientas de terceros? Los datos procedentes de Google son muy valiosos, porque son los más precisos y cercanos al motor en el que intentamos posicionarnos.
Pero Google sólo nos proporciona una cantidad muy limitada de datos y tenemos que utilizar otras herramientas especializadas. Esto no significa que sean malos, simplemente hay que tener en cuenta que Google no tiene nada que ver con ellos.
En segundo lugar, es importante saber si se trata de datos brutos o datos procesados.
Los datos en bruto nos los sirven en su estado inicial, necesitando ser reelaborados para hacerlos hablar (ejemplo: logs del servidor, exportaciones de backlinks, datos de rastreo, SERPs de Google, etc.).
Los datos procesados han sido pasados por el tamiz de las herramientas que los han premasticado, filtrado, popularizado, agrupado, etc. Son fáciles de manipular y comparar, pero en la búsqueda de la simplificación se puede perder precisión.
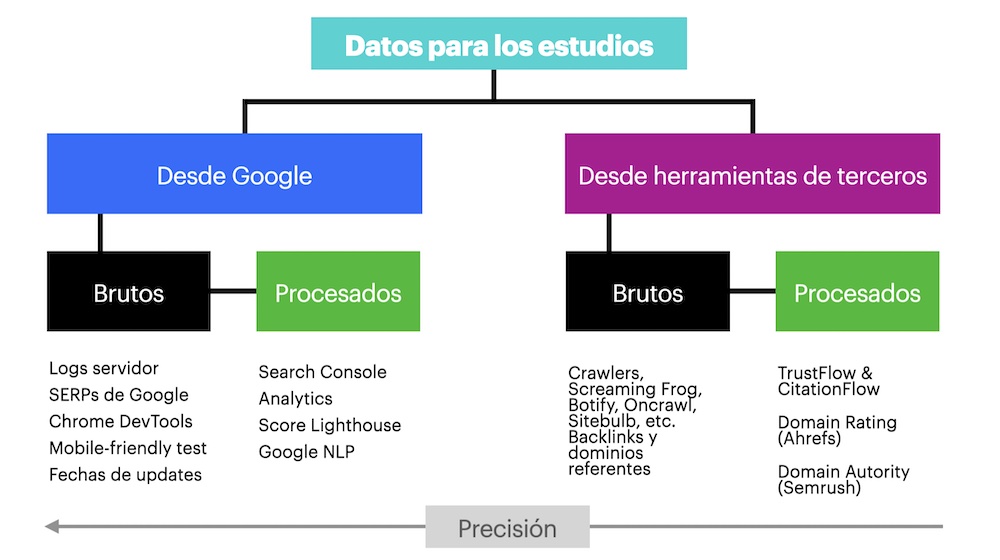
Entornos de prueba
Dependiendo del objeto de la investigación, los estudios y las pruebas pueden realizarse en entornos laboratorio o de campo.
Un entorno de laboratorio suele consistir en la creación de páginas, sitios que sólo conoce el organizador de la prueba. Ocultas al público, estas secciones no reciben tráfico y las otras personas no pueden perturbar de forma voluntaria o involuntaria los resultados.
Estableceremos un entorno de laboratorio cuando necesitemos garantizar la máxima limpieza de las pruebas, sin influencias indeseadas de factores externos.
Para probar los factores de clasificación, intentamos posicionar estas páginas en palabras clave reales o inventadas (sin competencia).
Por último, la principal ventaja de los entornos de laboratorio es su capacidad de control al 100%.
Veamos un ejemplo de prueba en un entorno cerrado: imaginemos que queremos comprobar si Googlebot sigue los enlaces nofollow. Crearemos una página con un enlace nofollow a otra página a la que sólo se puede acceder a través de este enlace. A continuación, comprobaremos regularmente los logs del servidor para ver si nuestra página de destino es rastreada por Google. En este tipo de pruebas, tenemos que estar absolutamente seguros de que la página secreta sólo es accesible a través de nuestro enlace nofollow, por eso es necesario tener un entorno oculto.
Algunas pruebas no pueden llevarse a cabo eficazmente en el entorno del laboratorio y necesitaremos un entorno de campo. Se trata de la realización de pruebas en páginas reales que se posicionan y reciben tráfico.
Para un ejemplo de prueba de campo, recordemos una vieja prueba de Rand Fishkin: en 2014, Rand Fishkin, fundador de Moz, realizó un estudio de caso con sus seguidores de Twitter:
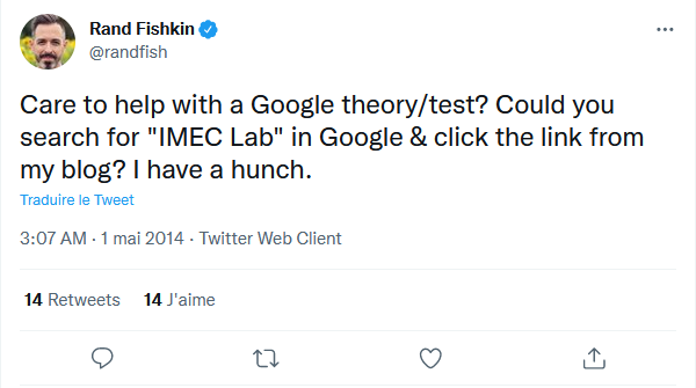
Source : Twitter
A las 18.03 horas, su sitio web ocupaba el séptimo lugar en una consulta especifica. Publicó un tuit en su cuenta de Twitter en el que pedía a sus seguidores que buscaran la palabra clave y que hicieran clic en su sitio web. A las 21:01, su sitio web estaba en el puesto número uno.
Esta prueba no podía llevarse a cabo en un entorno cerrado, ya que requería acciones por parte del público.
Protocolo de prueba/estudio
Una de las principales cualidades de la investigación que valoramos es su metodología y el rigor con el que se controla. Se espera que estos dos factores conduzcan a resultados objetivos, factuales e imparciales.
Para garantizar la correcta realización de un estudio, es necesario elaborar un protocolo de estudio.
El protocolo es una descripción rigurosa del proceso de estudio: desde el objetivo hasta la medición de los resultados. En su forma más simple incluye:
- Objetivo del estudio : una hipótesis formulada que se desea confirmar, refutar o investigar.
- Metodología: descripción paso a paso de cómo se llevará a cabo el estudio.
- Entorno del estudio: ¿es necesario que el estudio se realice en un laboratorio o en un entorno de campo?
- Criterio de medición y herramienta(s): ¿cuál es el indicador más relevante a medir y con qué herramientas?
- Reservas: conjunto de cláusulas vinculadas a los datos utilizados, las herramientas, el entorno, etc., cuyos defectos pueden influir en los resultados. Por ejemplo, al analizar los porcentajes de clics, se supone que los datos proporcionados por Search Console son correctos y precisos.
Esta descripción de un estudio no sólo es una señal de respeto hacia el público con el que se va a compartir, sino que también es una forma eficaz de encontrar lagunas e incoherencias en nuestro razonamiento.
La metodología es tan importante como los resultados
El núcleo de cualquier estudio es su metodología, que a menudo se ignora al centrarse exclusivamente en los resultados. Pero la metodología es tan importante como los resultados.
Veamos dos ejemplos.
Cuando trabajé en un estudio sobre la tasa de clics en 2018, descubrí que había al menos 3 métodos para calcular las tasas de clics y cada uno tenía su propio propósito:
- Para cada posición redondeada, se puede dividir la suma de clics por la suma de impresiones de todas las palabras clave y multiplicar por 100%.
- Para cada posición, se toma el promedio de los valores de CTR proporcionados por Search Console.
- Para cada posición, se toma la mediana de los valores de CTR proporcionados por Search Console.
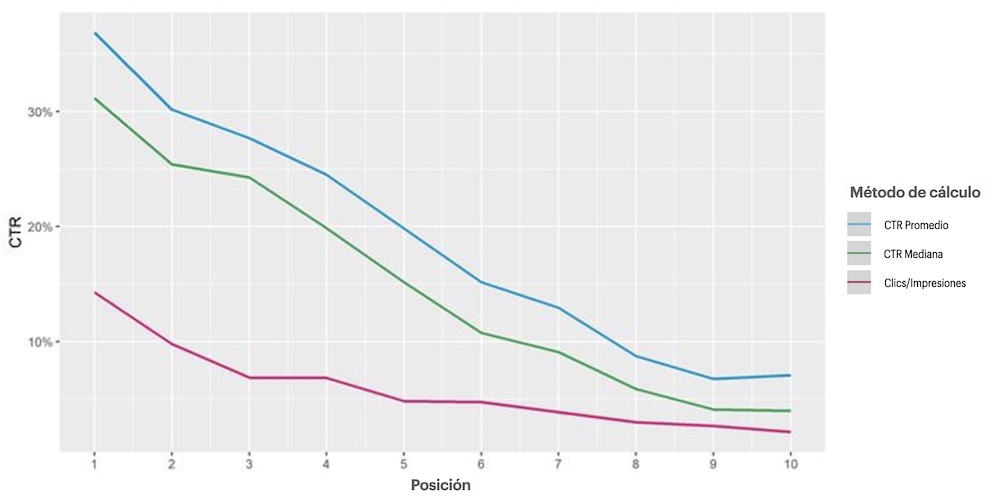
El primer método será el más realista, pero está muy sesgado hacia las palabras clave muy populares, y las palabras clave más pequeñas se verán ahogadas (pero pueden tener sus propias características de clics).
El segundo y el tercer método conceden a todas las palabras clave los mismos derechos y valoran su diversidad. La única diferencia es que en el segundo caso, el promedio será más sensible a los valores atípicos que puedan tener algunas consultas.
Para las cuestiones del estudio de la tasa de clics global, utilizamos el tercer método -la mediana del CTR- que es compatible con todos los grupos de consultas y es bastante estable a los valores atípicos.
Las elecciones metodológicas son la razón más común por la que los estudios llegan a veces a resultados muy diferentes, aunque correctos.
Nuestras elecciones de métodos también se enfrentan a múltiples sesgos denominados metodológicos – errores en el método científico, incumplimiento de las normas de protocolo que conducen a resultados erróneos: sesgo de supervivencia, sesgo de selección, sesgo de medición, sesgo de confusión, etc.
Los estudios de cualquier tipo exigen rigor en el desarrollo de una metodología adecuada y en el seguimiento de todo el proceso. Pero por muy avanzadas que sean nuestras habilidades científicas, lo que probablemente sea aún más importante son nuestras cualidades humanas, psicológicas: ser imparciales, estar abiertos a cualquier resultado, no dejarse influir por las primeras impresiones o por las verdades de los demás.
Hay una multitud de sesgos cognitivos con los que nos vemos obligados a lidiar.
Les invito a escuchar el Podcast del Placer del SEO donde explico Los 7 sesgos cognitivos a combatir para ser más eficaz en SEO.
Y por supuesto, una vez realizado el estudio, publicarlo es también una cuestión de ética y responsabilidad. Como hemos visto al principio de la presentación, la gente se creerá sin duda sus resultados. Estos resultados pueden influir en su forma de trabajar, en la toma de decisiones, en las elecciones empresariales, etc.
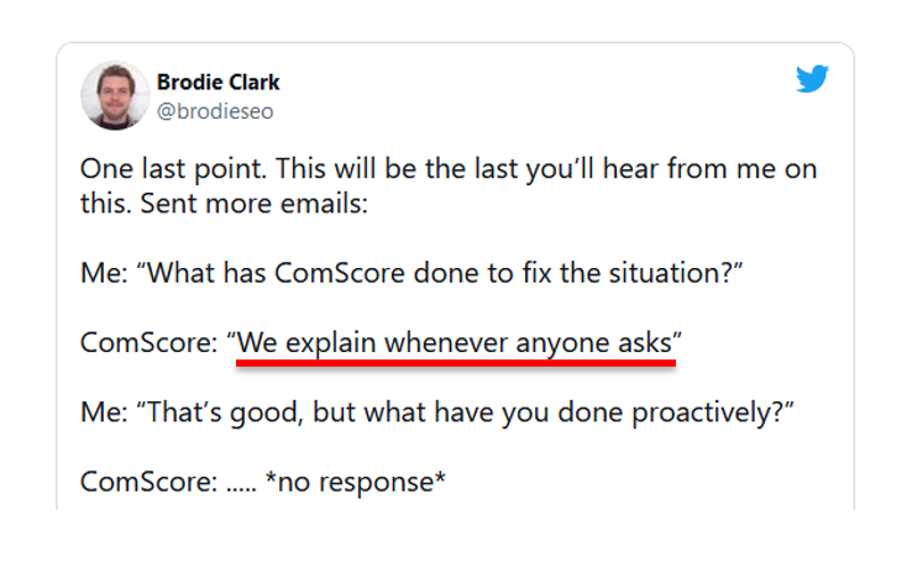
En el caso del inexistente estudio sobre la búsqueda por voz, Brodie Clark hizo una hermosa pregunta a la empresa americana: “¿Qué ha hecho Comscore para solucionar esta situación? Tuvo la respuesta :”Lo explicamos cada vez que alguien pregunta.” Y cuando preguntó por las medidas proactivas adoptadas, un ángel pasó en silencio…
Hemos establecido los fundamentos de la configuración de estas pruebas, ahora vamos a recorrer 5 ejemplos reales de investigaciones SEO con experimentos y todo el proceso necesario: desde la hipótesis, pasando por el protocolo de pruebas, la metodología, hasta la medición de resultados y la extracción de conclusiones para entender mejor la carga del archivo .htaccess, las etiquetas canónicas, Google News, la caché de Google y Discover
Las pruebas y la investigación son probablemente las formas más eficaces de aportar claridad a nuestros métodos de trabajo, de acabar con las incertidumbres generalizadas, de comprender mejor cómo funciona el motor de búsqueda y cómo influir en él.
En la primera parte, repasamos las bases teóricas para la correcta realización de estudios: tipología de las investigaciones a realizar y de los datos a utilizar. Discutimos los importantes conceptos de protocolo y metodología de las pruebas, sin olvidar los múltiples sesgos metodológicos y cognitivos que pueden arruinar todo el trabajo.
Ahora es el momento de pasar a la práctica y ver en ejemplos de pruebas y estudios la aplicación de los puntos que hemos tratado.
Test #1 : ¿Cuántas redirecciones se pueden poner en .htaccess?
Las migraciones y los rediseños son proyectos en los que muchos SEO son solicitados regularmente (felizmente). Y los planes de redirecciónes son una parte integral de esto.
En el caso de las grandes reestructuraciones, hay que aplicar los redireccionamientos página por página. Y una pregunta legítima que se plantea a menudo es: ¿hasta qué punto estos redireccionamientos -cuyo volumen puede calcularse fácilmente en miles- corren el riesgo de afectar al rendimiento del sitio?
Hipótesis: En esta primera prueba, formulamos la siguiente hipótesis: *¿Hay un límite en el volumen de líneas de redirección que se pueden añadir al archivo .htaccess, por encima del cual se degrada el tiempo de carga?*
Entorno:
- Servidor compartido en modo “barato”.
- Nuevo subdominio.
- Archivo html minimalista con sólo un párrafo de texto y sin archivos de estilo ni scripts conectados.
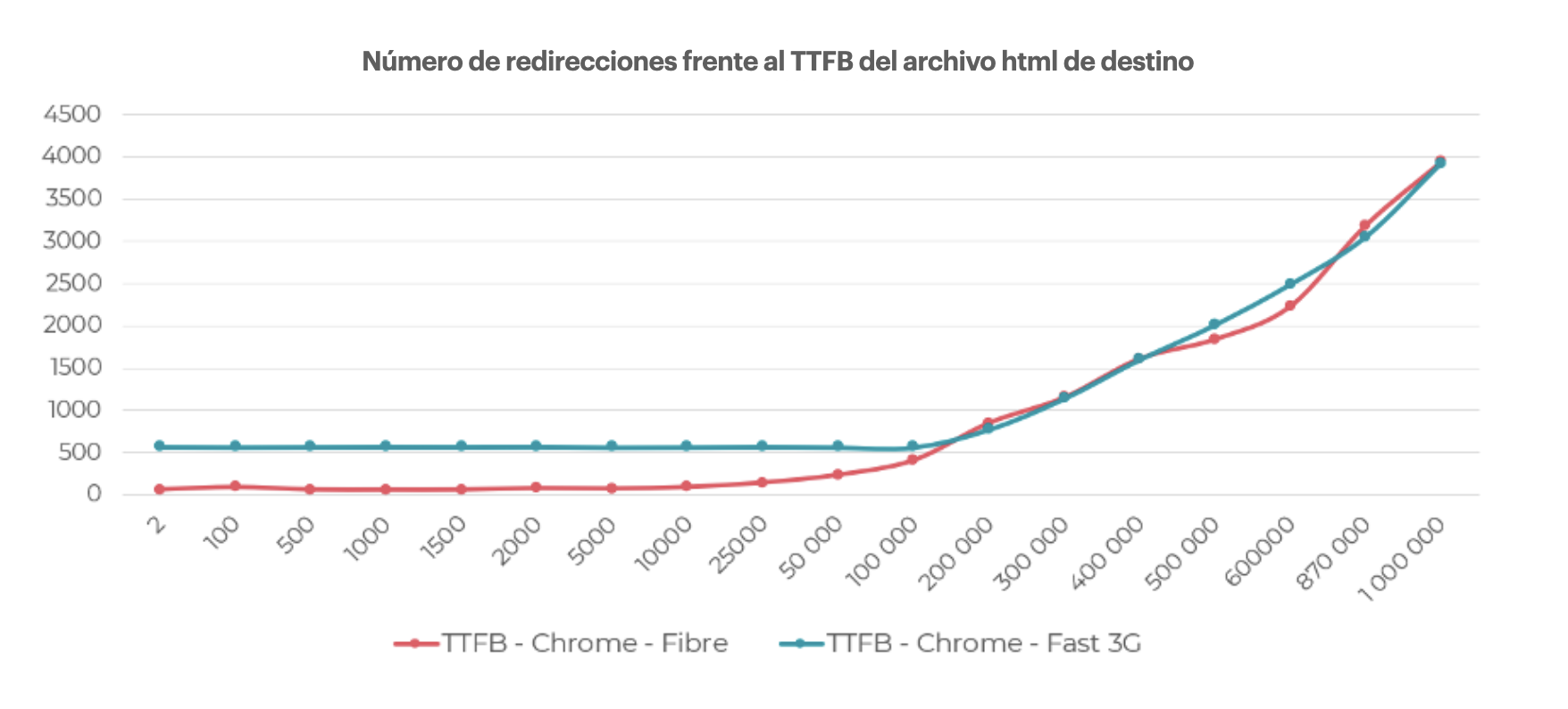
Medición: Según la documentación del servidor Apache, antes de acceder a una página web, el servidor comprobará el archivo .htaccess para ver si hay directivas que aplicar. Esto significa que el indicador que vamos a medir debe estar lo más cerca posible del inicio de la carga de la página. Entre todos los indicadores relacionados con webperfs, es el TTFB (Time to First Byte – tiempo que se tarda en acceder a la página mucho antes de que se cargue su contenido) el que lógicamente hemos seleccionado.
Para medirlo, utilizaremos la consola de Chrome para simular dos entornos de acceso a la página:
- Conexión de fibra optica;
- 3G.
Criterios: TTFB
Herramienta: Chrome DevTools (conexión de fibra óptica vs 3G).
Reservas: Los resultados pueden ser diferentes en servidores de mayor rendimiento.
Resultados: Incluso en un servidor barato, el volumen de redirecciones de hasta 10.000 no es un problema en términos de tiempo de acceso.
- A partir de 25.000 líneas de redireccionamiento, el acceso a la página se ralentiza en 0,14s.
- A partir de 50.000 líneas de redirección, la latencia ya está en el nivel de 0,23s.
- 1 millón de líneas de redirección retrasarán el acceso a la página de 4s.
Test #2: ¿La etiqueta canónica cross domain es una solución confiable?
A menudo, en busca de más audiencia, los editores de sitios recurren a la sindicación de sus contenidos en plataformas populares de terceros. El objetivo es pragmático: mejorar el alcance de sus contenidos beneficiándose de la audiencia que “habita” en las plataformas en cuestión.
Como podemos imaginar, el punto más delicado es la duplicación de contenidos: nuestro artículo se publicará tanto en nuestro sitio como en un sitio externo.
Así que, desde el punto de vista de la SEO, surge una pregunta legítima: ¿Cómo aprovechar la audiencia de la plataforma a distancia manteniendo sus activos SEO, especialmente sus posiciones?
Entre las soluciones propuestas por Google, encontramos la implementación de la etiqueta “canonica” que enlazará los dos artículos y asegurará nuestra originalidad. El problema es que esta etiqueta no es una directiva (como la etiqueta meta robots “noindex”), sino una sugerencia para Google, que puede respetarla o no.
En el canal de Youtube del Placer del SEO explico cuál es la diferencia entre directiva e indicación:
Hipótesis: En el caso de la distribución de nuestros contenidos en sitios de terceros, ¿es la etiqueta “canonical” una solución fiable para no degradar el rendimiento SEO?
Entorno: Campo (condiciones y páginas reales, posicionadas)
Metodología: Para estudiar este aspecto, necesitamos encontrar una plataforma que nos permita publicar nuestro contenido teniendo la posibilidad de indicar en la etiqueta “canonical” la página de origen en la que el contenido ya está publicado y, por tanto, se considera original. Entre los distintos agregadores de contenidos, seleccionamos Medium.com, que cumple los criterios requeridos.
- 150k artículos de Medium.com exportados en total.
- 2.876 artículos conservados con una etiqueta “canónica” a una fuente externa.
- Utilizamos los encabezados H1 como palabras clave y comprobamos las clasificaciones.
- Posiciones comparativas del artículo en Medium y en el sitio original.
Resultados:
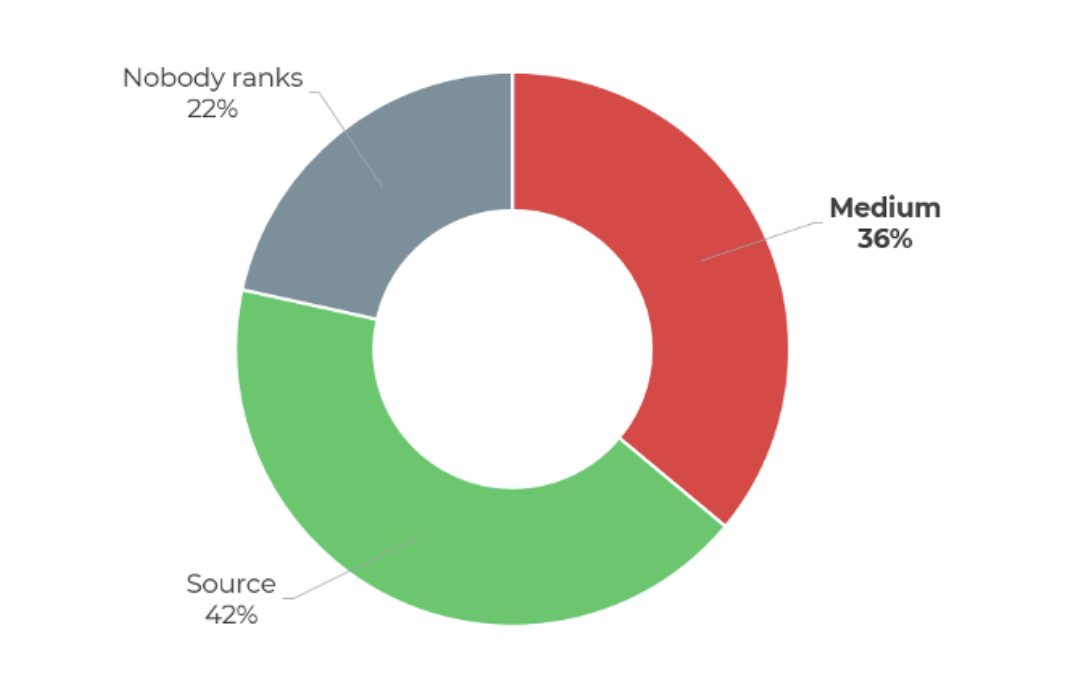
- En el 42% de los casos es la página original del artículo la que se posiciona en los resultados de Google (aquella a la que apunta la etiqueta “canónica”).
- En el 36% de los casos es el artículo en Medium.com el que se posiciona.
- En el 22% de los casos, ninguno de los sitios está clasificado.
¿Quién está mejor posicionado: Medium o la fuente?
Si nos detenemos en estos primeros resultados, estaríamos en pleno sesgo de representatividad o anclaje (cuando tomamos decisiones basadas en las primeras impresiones).
La pregunta correcta que hay que hacerse en esta fase es: En el caso de no posicionamiento de la página original, ¿el problema es realmente con la etiqueta canónica?
Para ir más allá, vamos a comprobar el estado técnico de las páginas a las que apunta la etiqueta “canónica”.
Entre los casos en los que se posiciona Medium, la mayoría de las páginas a las que apunta la etiqueta “canonical” no son indexables (responden en 404, contienen una directiva noindex).
Si ajustamos el ratio con los nuevos datos recibidos, obtenemos los siguientes resultados: la etiqueta “canonical” fue respetada por Google y en el 59% de los casos permitió posicionar la página de origen del artículo en los resultados de Google. El resultado es bastante satisfactorio y es un método bastante eficaz.
Indexibilidad de las páginas canónicas
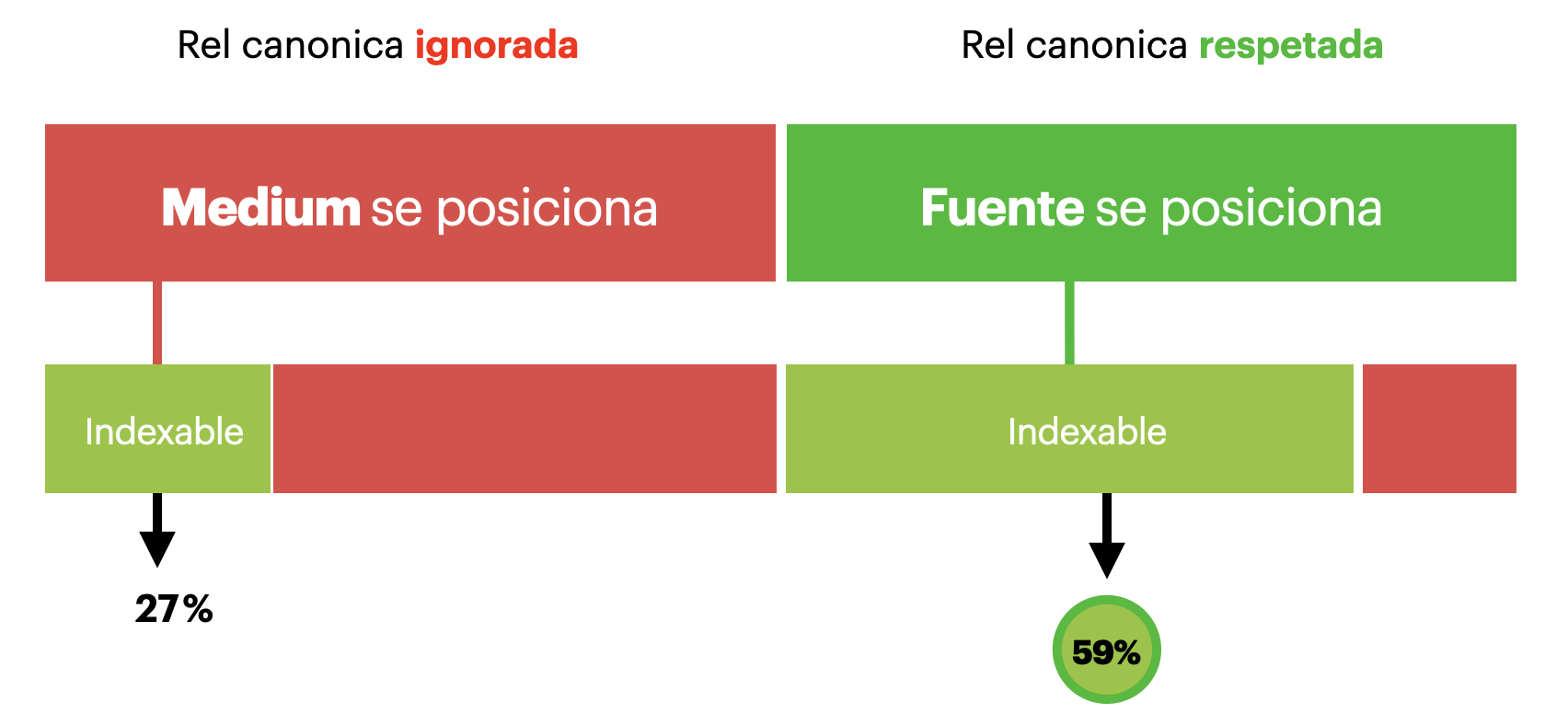
Rel canonica no es respetada en caso de problema técnicos en la página de destino.
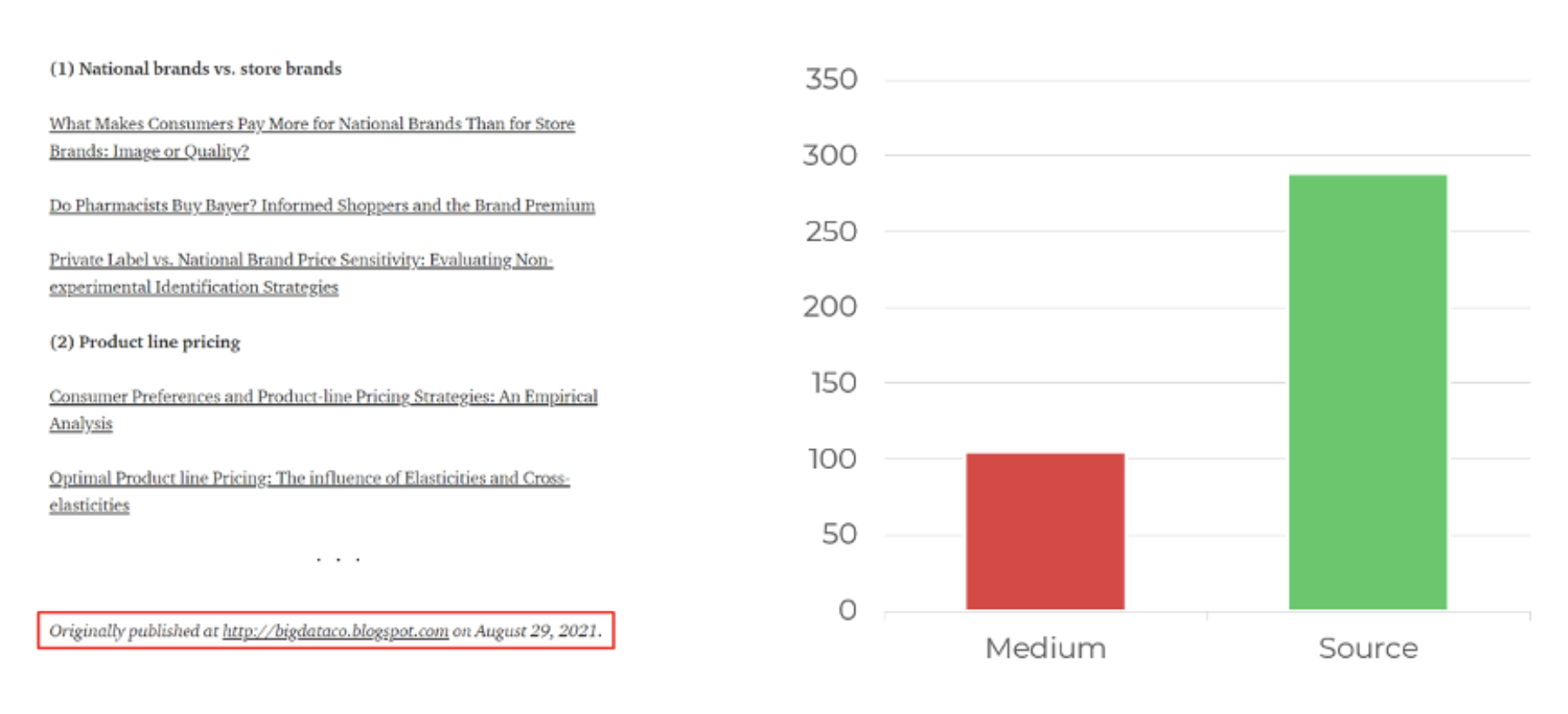
Es posible ir aún más lejos. Además de la etiqueta canónica, Medium también permite a los autores mostrar un enlace HTML a la página de origen al final de los artículos (“Publicado originalmente en …“).
Y esta es una forma eficaz de indicar a Google que el artículo en cuestión es una reedición del artículo publicado en otro lugar.
¿Ayudará añadir un enlace a la fuente?
Test #3. Google News : cuando Google se niega a leer nuestros artículos…
Muy a menudo el origen de los tests SEO es la curiosidad, pero también hay casos en los que las investigaciones vienen impuestas por necesidades y problemas reales.
Hace unos años, comenzamos a trabajar con un gran medio de comunicación (por confidencialidad no puedo revelar cual es) para mejorar la visibilidad SEO de su sitio de medios. Una de las primeras cosas que reportamos al cliente fue la incertidumbre de que los artículos fueran correctamente visibles en los resultados de Google News. Curiosamente, algunos artículos no aparecían en Google News, otros tenían una visibilidad mucho menor en promedio.
Problema: Algunos artículos de no aparecían o eran poco visibles en Google News.
Investigar si hay problemas con la lectura de artículos por parte de Google y, si es así, cuál es la causa.
Metodología:
- Tomamos una muestra de 70 artículos de todos los temas y los pasamos por la herramienta de solución de problemas de artículos en https://partnerdash.google.com/. En la antigua versión del área de editores, esta herramienta se utilizaba para comprobar si Googlebot News era capaz de extraer correctamente el contenido de los artículos. (Lamentablemente después de la actualización en 2019 la herramienta de solución de problemas ya no existe 🙁 ).
- En las primeras comprobaciones constatamos que Google sólo consiguió extraer una parte del artículo. Después de cada envío, anotamos todos los casos en los que Google truncaba un artículo y el elemento que lo provocaba.
De los 70 artículos, 18 fueron extraídos en su totalidad, los 52 artículos restantes fueron truncados.
En nuestra muestra de artículos, hemos anotado todos los elementos observando cuándo el robot de Google News dejó de rastrearlo:
|
¿Ante qué elemento de la página se trunca el artículo? |
Número de casos |
| Leer Más |
32 |
| Post completo |
18 |
| Texto del tweet |
9 |
| Antes <iframe id=twitter-widget-0” |
7 |
| Youtube |
3 |
| Antes <iframe id=twitter-widget-1” |
1 |
En 32 de los 52 casos, Googlebot-News dejó de leer el artículo después de un “Leer Más” que sugería al lector un enlace a otro artículo.
Técnicamente, la inserción no era nada especial (una con un párrafo), pero como a menudo se integraba al principio del artículo, Google sólo tenía en cuenta uno o dos párrafos, lo que no permitía que los artículos subieran a Google News.
Una vez eliminados estos enlaces del cuerpo de los artículos (trasladados al final), las páginas recuperaron la visibilidad en Google News.
Lección aprendida de este estudio: intentar no integrar elementos heterogéneos en el cuerpo de los artículos, ya que el rastreador de Google News puede considerarlos como una señal de fin de artículo.
Test #4. ¿Por qué una página puede no tener una versión caché en Google?
Identificamos que uno de nuestros clientes tiene algunas de las páginas de su sitio con una versión caché en Google, mientras que otras no. Las páginas no tenían una directiva noarchive, que suele utilizarse para evitar que la página se guarde en la caché de Google.
Una razón más para hacer un estudio.
Parece que hay un indicador específico para todas las páginas que no tienen una versión en caché, diferente de las páginas que no tienen este problema. ¿Qué es este indicador y a qué valor prohíbe el almacenamiento en caché?
Metodología:
- Exportar desde los resultados de Google en igual cantidad las páginas con versión en caché y las que no.
- Rastrear con Screaming Frog todas estas páginas recuperando el mayor número posible de indicadores técnicos y editoriales.
- Comparar los indicadores de dos tipos de páginas e identificar el o los que marcan la diferencia.
Resultados:
Al final de este enfoque, se revisaron muchos indicadores y finalmente hubo uno que indiscutiblemente mostró la mayor correlación: el peso de la página.
Como recordatorio, el peso del HTML es el volumen del código fuente HTML calculado en bytes (1 carácter, número, letra o espacio es 1 byte).
La primera lista, tal y como la presentó el rastreador, parece un poco caótica y probablemente no diga mucho. Pero la magia de la clasificación en orden descendente pone de manifiesto su impacto en el almacenamiento del caché:
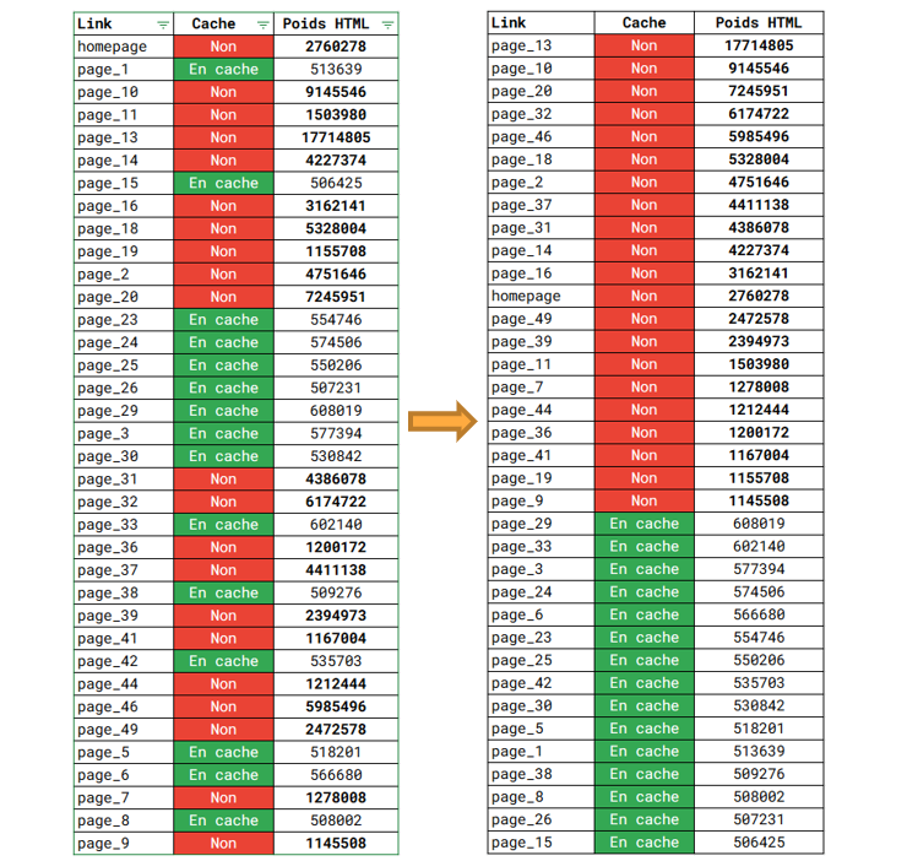
Google no conservará la versión de la página cuyo peso HTML supere 1 Mega (es decir, 1 millón de caracteres).
Los portavoces de Google han declarado repetidamente que la presencia o ausencia de la versión en caché no influye en la clasificación de la página. Al mismo tiempo, este estudio identificó el problema del peso de la página, que se debía a que el framework Angular no se había desplegado de forma óptima.
Test #5. Google Discover : Reducir el área de desconocimiento
Lanzado oficialmente en 2019, Google Discover ha llamado rápidamente la atención por los volúmenes de audiencia enviados a los sitios web.
Como recordatorio, Google Discover es un sistema de recomendación que ofrece selecciones de páginas basadas en los intereses de los usuarios de Android y las aplicaciones de Google.
Al tratarse de tráfico gratuito, además en un entorno de búsqueda de Google, normalmente cae dentro en el perímetro de trabajo de los SEO, o al menos de los que trabajan con sitios de medios de comunicación.
Google Discover es un entorno muy especial con muchas limitaciones:
- Resultados 100% seleccionados por inteligencia artificial.
- Ausencia de palabras clave clásicas sustituidas por centros de interés.
- Documentación mas que concisa (las recomendaciones de Google para aparecer en Discover se limitan a “crear artículos de tendencia con títulos relevantes (sin abusar) e grandes imágenes”.
- Como Discover existe dentro de las aplicaciones móviles, es imposible obtener grandes muestras de datos de diferentes sitios.
Pero Google ya lanzó la API de Discover y ahora es más facíl extraer los datos rápidamente
Sin embargo, con todas estas limitaciones, ¿podemos por fin aprender algo sobre el funcionamiento de Google Discover?
La primera pregunta que se puede responder con certeza: ¿Es necesario ser referenciado en Google News para aparecer en Google Discover?
Varias observaciones dan una respuesta clara: ¡no!
- En primer lugar, si analizamos las páginas que aparecen en Discover, veremos que también aparecen en las otras palancas SEO: Google News y Google orgánico clásico. Es sólo una cuestión de trending topic.
- Otra prueba: los e-commerce pueden ver que sus listados de productos estrella aparecen regularmente en Google Discover. Lógicamente, no están referenciados en Google News.
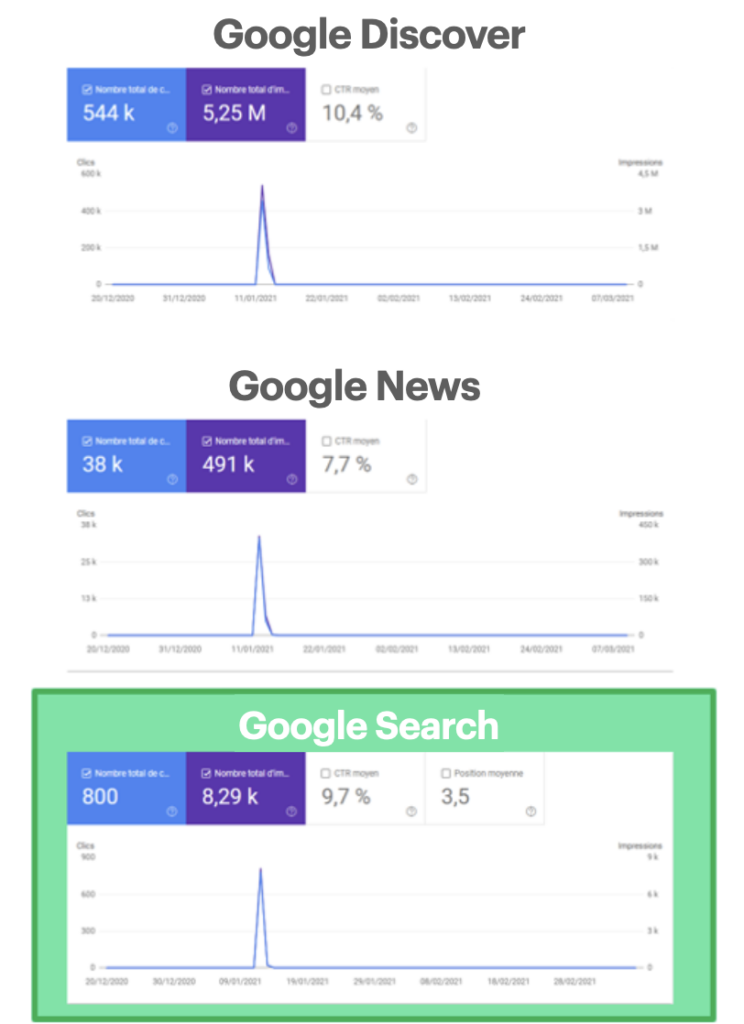
Google Discover es un buen ejemplo de cómo, reorganizando y enriqueciendo los informes básicos, podemos aportar más claridad al funcionamiento de la herramienta.
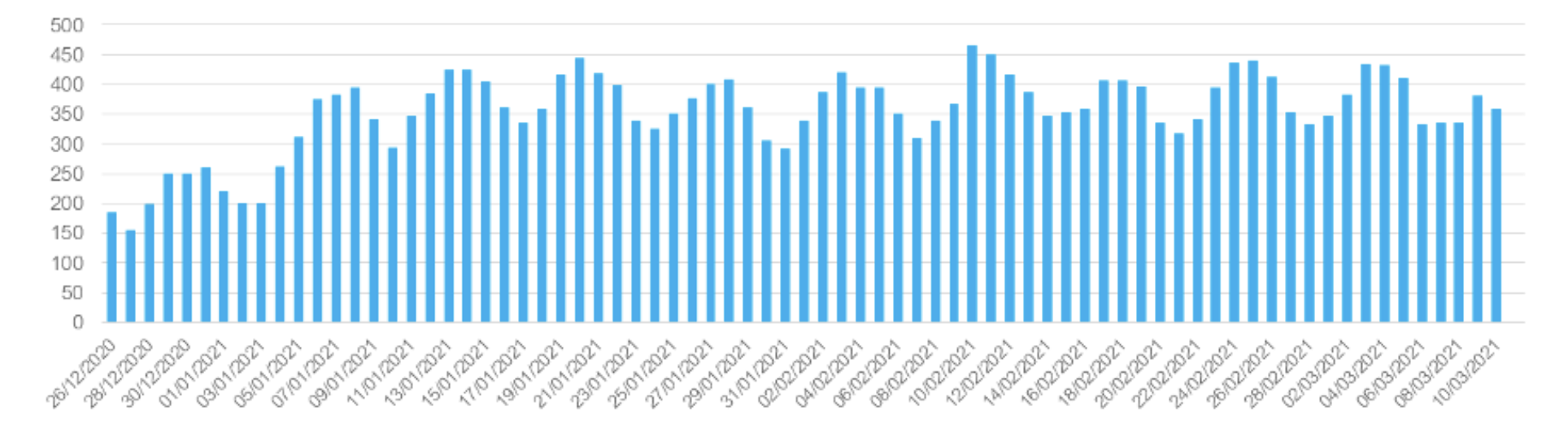
Por ejemplo, podemos asociar páginas con fechas de aparición en Google Discover y analizar la evolución del número de páginas que aparecen cada día en Discover.
Se trata de un análisis puramente estadístico. Esta vista es útil en caso de una caída repentina del tráfico desde Discover: para analizar si realmente aparecen menos artículos allí.
Cantidad de páginas apareciendo en Discover
Como tenemos los artículos fecha por fecha, podemos calcular la vida de las páginas en Google Discover.
Con toda la naturaleza efímera del tráfico de Discover, hay sin embargo páginas que aparecen durante 10-20 días. El análisis de estas páginas nos permite reorientar la campaña editorial hacia la creación de artículos potencialmente más eficaces en Google Discover :
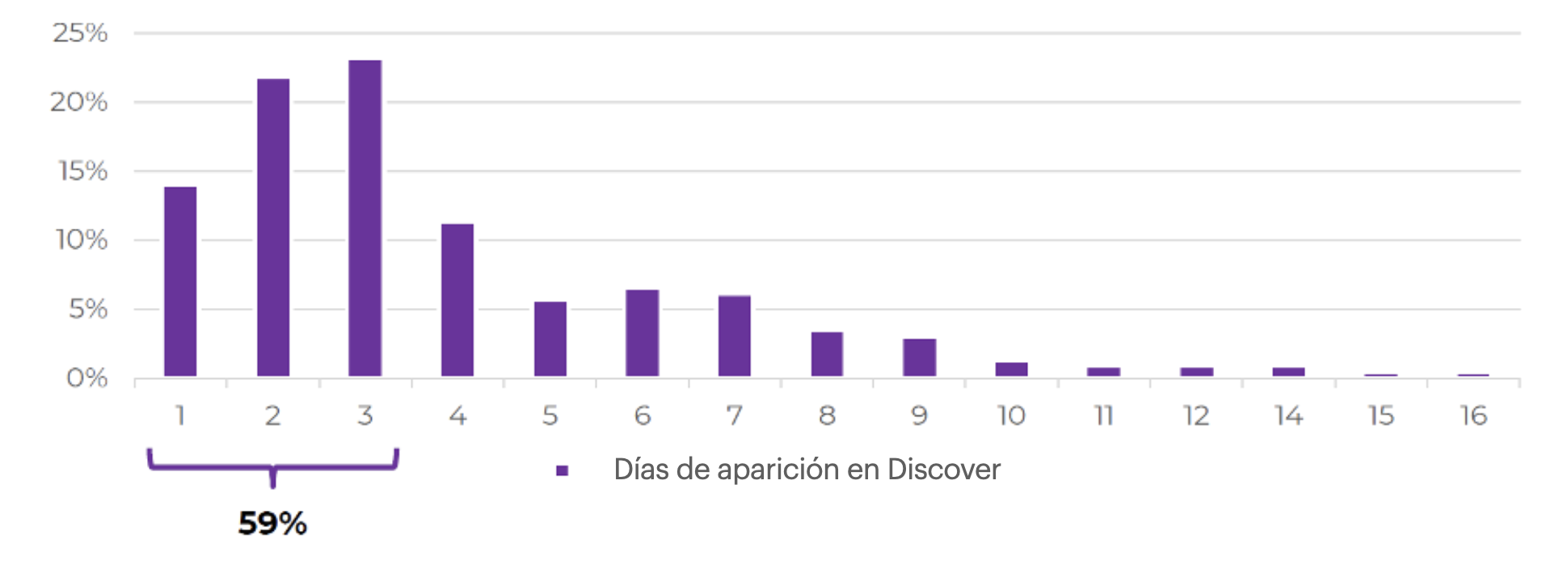
Répartition des pages d’un site média par nombre de jours d’apparition dans Google Discover.
Podemos ir más allá y enriquecer los datos proporcionados por Search Console. Por ejemplo, podemos rastrear las páginas que aparecen en Google Discover, extraer su fecha de publicación real y compararla con la fecha en que aparecen en Discover.
Este análisis nos permite ver muy claramente que las páginas que aparecen en Google Discover son en su mayoría recientes. En esta gráfica, podemos ver los resultados de un sitio de medios de comunicación:
- El 36% de los artículos que aparecen en Google Discover se publicaron el mismo día;
- El 88% de los artículos se publicaron como máximo hace 3 días.
Sin embargo, es útil analizar los patrones de los artículos antiguos que aparecen en Discover.
Cantidad de páginas aparecidas en Google Discover & cantidad de días pasados desde la publicación
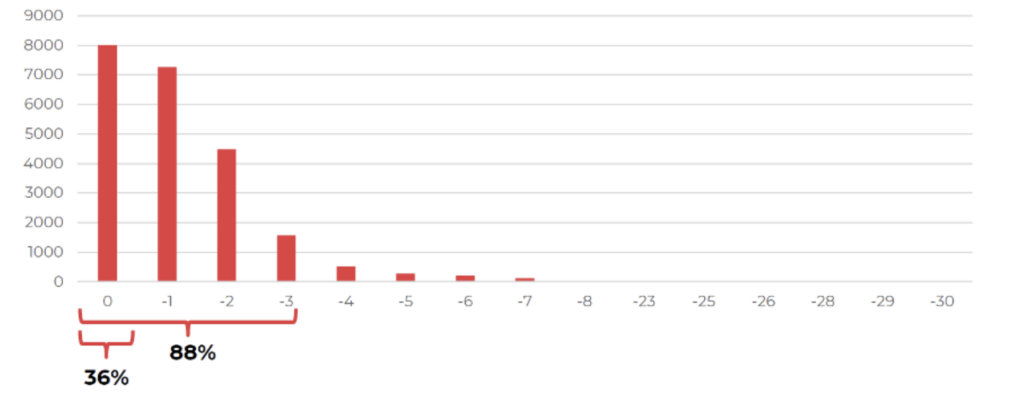
El 36% de los artículos que aparecen en Google Discover se publicaron el mismo día
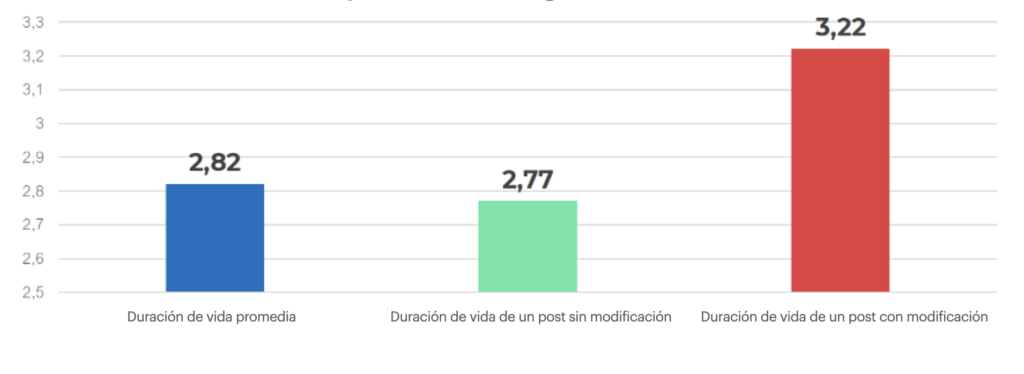
Los sitios de medios de comunicación suelen tener una fecha de modificación junto a la fecha de publicación, si el artículo ha cambiado desde su publicación. Al recuperar esto, podemos comparar el rendimiento de los artículos que han sido modificados y los que han permanecido sin cambios.
Los resultados obtenidos de un importante medio de comunicación mostraron que la modificación del artículo aumentaba el ciclo de vida en un 16% en promedio.
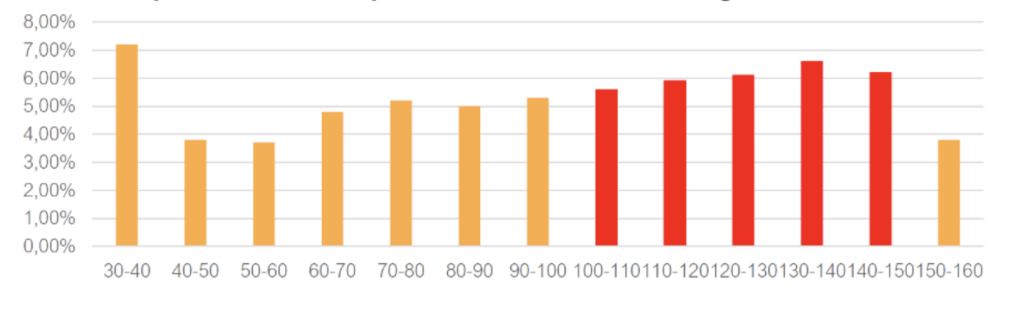
Al crawlear las páginas, también podemos recuperar sus títulos y cruzar su longitud con el CTR en Google Discover. Por ejemplo, para saber si los títulos cortos o largos atraen más la atención de los usuarios de Discover.
En cuanto a los resultados observados en varios sitios de medios de comunicación, por regla general, cuanto más largo es el titular, mejor es su porcentaje de clics en los resultados de Discover. La razón es probablemente sencilla: un titular más largo ocupa más superficie, lo que se nota mucho en las pantallas de los móviles.
Repartición de la longitud de los títulos por volumen de impresiones de artículos en Google Discover
Se puede ir aún más allá y analizar los títulos, no sólo cuantitativamente, sino también cualitativamente. En concreto, es posible realizar un análisis sentimental (debe ser mi lado francés) y estudiar qué titulares funcionan mejor: neutros o calurosos, subjetivos u objetivos.
Al analizar los títulos de varios medios de comunicación, se comprobó que los titulares que dan una opinión sobre un hecho generan muchas más impresiones en Discover que los titulares neutros.
En cuanto al sentimiento compartido por el titular, los resultados son menos concluyentes. Sin embargo, los titulares con un sentimiento positivo parecen funcionar mejor.
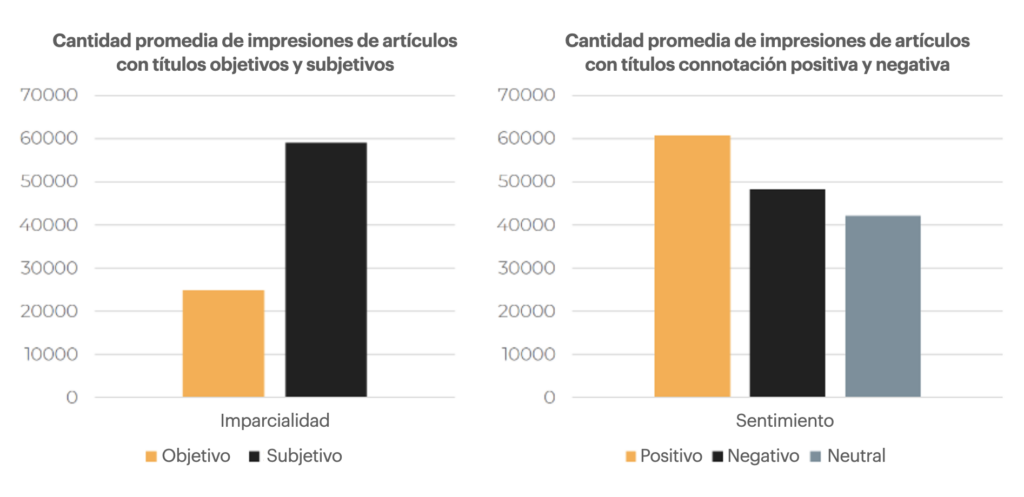
Les titres donnant une opinion, partageant une émotion positive génèrent plus d’impressions dans Google Discover.
¿Qué temas de artículos aparecen con más frecuencia en Discover? Como todos sabemos, Google Discover ofrece resultados basados en nuestros intereses. Estos intereses son numerosos, se cuentan por miles.
Obviamente, no podemos adaptarnos a todos los intereses, pero podemos identificar los temas comunes que mejor funcionan:
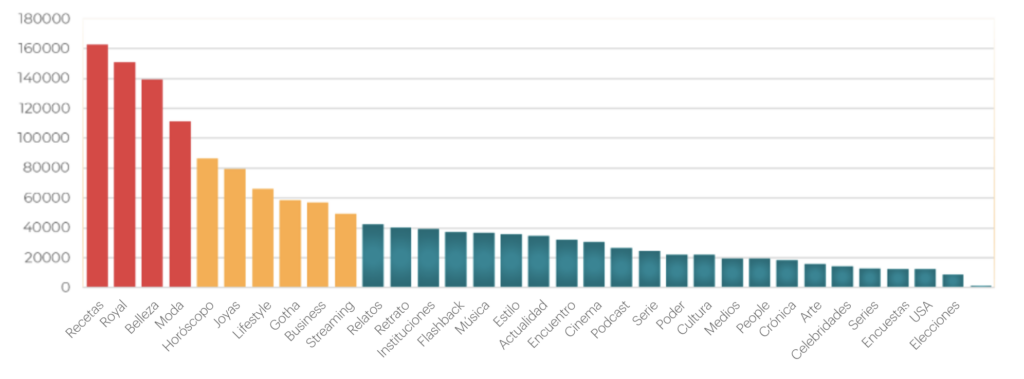
Potencial = promedio de impresiones de los artículos del tema
Hacer este tipo de investigación ayuda a comprender mejor qué temas se muestran con más frecuencia en Google Discover. Y si un medio de comunicación experimenta un desplome de las audiencias de las noticias tradicionales, podremos sugerir al equipo editorial que se centren en determinados temas que tienen más probabilidades de aparecer en Discover. Y las cifras de audiencia proporcionadas por Google Discover son muy interesantes.
Para concluir
Como hemos visto en los ejemplos anteriores, las pruebas y estudios SEO pueden adoptar diferentes formas y llevarse a cabo en diferentes contextos.
Pueden dar respuestas a preguntas frecuentes (redireccionamientos en .htaccess), confirmar o desmentir prácticas SEO (etiqueta canónica entre dominios), aclarar algunas de las particularidades del funcionamiento de Google para nuestros clientes (caché de Google) o quitar (un poco) el velo de desconocimiento sobre nuevas herramientas como Google Discover.
Espero que esta presentación les motivará a investigar por su cuenta.


