
Fundamentos, hipótesis y diseño del estudio
¿Por qué hacer un estudio SEO basado en una gran muestra?
La mayoría de lo que se afirma en SEO está basado en observaciones parciales:
un caso de éxito, una cuenta de Search Console, una corazonada o una herramienta de terceros.
Pero cuando quieres entender qué está pasando realmente en el comportamiento de los usuarios o los resultados de Google, eso no basta.
Necesitas trabajar con una gran muestra de datos provenientes de muchos sitios web distintos.
¿Por qué?
Porque el SEO no es una ciencia exacta, pero se ve afectado por demasiadas variables: intención de búsqueda, tipo de dispositivo, branding, sector, tipo de contenido, ubicación, idioma, estacionalidad, y desde hace poco… el bloque de IA en la SERP.
Estudiar un solo dominio no te permite aislar esas variables.
Solo con una muestra suficientemente grande, diversa y bien segmentada puedes identificar patrones que no dependan de un caso específico.
El rol de la hipótesis: no se estudia todo, se estudia algo
El primer paso metodológico para hacer un estudio con sentido es definir una hipótesis clara, delimitada y verificable.
Ejemplo de hipótesis mal planteada:
“El SEO ya no funciona igual.”
Eso no se puede medir.
Ejemplo de hipótesis bien planteada:
“El CTR promedio de los resultados en posición 1 ha disminuido significativamente desde la activación de los AI Overviews de Google, en consultas informativas no relacionadas con marca, en mobile.”
¿Por qué esta hipótesis es útil?
- Porque define qué se mide (CTR en posición 1)
- Porque establece una condición temporal (antes y después de un cambio)
- Porque segmenta el tipo de búsqueda (informativa, sin marca)
- Porque especifica una plataforma (mobile)
Este tipo de hipótesis sirve como ejemplo para explicar todo el diseño de un estudio robusto.
Qué necesitas para hacer el estudio
Ahora entramos en el diseño: ¿qué recursos necesitas para hacer un estudio así?
a) Una gran muestra de sitios web
Esto no es optativo. Para que un estudio tenga valor estratégico (no anecdótico), necesitas:
- Acceso a al menos 50–100 sitios web distintos
- Con Google Search Console habilitado y activo
- De sectores variados, o bien muy controlados si es un estudio temático
⚠️ No se hace un estudio serio con un solo dominio, porque los datos están correlacionados y los sesgos no se pueden controlar.
b) Volumen de datos por sitio
Por sitio, necesitas que cumplan con:
- Miles de clics y consultas por mes
- Datos históricos de al menos 6 meses
- Métricas disponibles: impresiones, clics, CTR, posición promedio, query, página de destino, país, dispositivo
c) Formato estructurado
Todo debe estar exportado en una base estructurada, idealmente así:
| sitio | query | fecha | clics | impresiones | CTR | posición promedio | país | dispositivo |
Esta tabla será luego segmentada, normalizada y analizada por grupos.
¿Cómo se accede a esa información?
Existen tres rutas:
a) Propiedades propias o de clientes
La más directa si eres agencia: acceso a los GSC de sitios bajo tu administración.
b) Alianzas
Crear un consorcio de sitios que compartan datos anonimizados con fines de investigación. Necesitas una estructura clara de participación, anonimato y reciprocidad.
c) Bases de datos públicas o compradas
Algunos proyectos académicos o empresas liberan datasets de navegación, pero rara vez con clics reales. Sirven como apoyo, pero no como fuente principal.
Del diseño a la ejecución: lo que viene
Una vez que tienes:
- Una hipótesis bien formulada
- Una muestra grande y diversa
- Datos estandarizados por sitio y por consulta
Estás listo para pasar a la siguiente etapa:
👉 el tratamiento y segmentación de esos datos, para poder comparar entre grupos (por ejemplo, pre y post-AI Overviews), definir qué significa “posición 1” en la práctica, y limpiar sesgos.
Limpieza, agrupación y segmentación de datos SEO a escala
Una vez que tienes los datos en bruto, comienza la parte menos sexy (y más crítica) del estudio:
limpiar, organizar y segmentar para que los datos sirvan para algo.
Hasta ahora tienes:
- Una hipótesis clara
- Una muestra de decenas (o cientos) de sitios con acceso a GSC
- Un histórico con miles de consultas por sitio
- Una tabla inmensa con millones de líneas como esta:
| sitio | query | fecha | clics | impresiones | CTR | posición promedio | país | dispositivo |
Pero eso, en su estado original, no se puede analizar directamente.
Es como querer entender la economía de un país con el estado de cuenta de cada ciudadano por separado.
Lo que necesitas ahora es convertir este ruido masivo en patrones legibles.
Estabilizar las posiciones: el problema del promedio en GSC
Google Search Console no da posiciones exactas.
Da un promedio de la posición en la que apareció un resultado para una query determinada durante un periodo.
Ejemplo:
- Si apareciste 80% del tiempo en posición 1 y 20% en posición 2, GSC te dará una posición promedio de 1.2
El problema: una posición promedio de 1.6 no significa que estuviste en la posición 1.
Solución: crear buckets de posición
En lugar de trabajar con decimales, agrupas los datos en rangos controlados. Por ejemplo:
| Rango | Bucket | Descripción |
|---|---|---|
| 1.0–1.2 | Bucket 1 | Alta confianza de que fue posición 1 |
| 1.3–2.2 | Bucket 2 | Mezcla entre posición 1 y 2 |
| 2.3–3.2 | Bucket 3 | Mezcla entre 2 y 3 |
| … | … | … |
Este sistema permite trabajar con grados de certidumbre y estabilizar las métricas.
En el estudio del CTR, por ejemplo, solo usas el Bucket 1 para definir la posición 1 real, y reduces así el riesgo de atribuirle variaciones a posiciones inestables.
Eliminar consultas de marca y outliers
Tu objetivo no es saber si “decathlon cancún” sigue generando clics.
Eso no refleja comportamiento genérico, sino conexión con marca.
Qué debes filtrar:
a) Queries con nombres de marca
- Casi siempre tienen CTR anormalmente alto
- No reflejan competencia real en la SERP
- Distorsionan los promedios
Puedes filtrarlas con un diccionario de marcas y expresiones navegacionales (“.com”, “inicio”, “oficial”, etc.), o usar modelos de detección automática.
b) Queries con muy pocas impresiones
- Una query con 1 clic y 2 impresiones tiene un 50% de CTR… pero no sirve para un estudio.
- Aplica un umbral mínimo de impresiones (por ejemplo, 100) para que los datos sean estadísticamente significativos.
📌 Esto no es censurar la muestra, es evitar que los extremos definan el promedio.
Segmentar por intención de búsqueda
No puedes mezclar “comprar zapatos negros mujer” con “qué es la creatina”.
Ni “chatgpt login” con “cómo hacer una estrategia SEO”.
El comportamiento del usuario, la forma en que interactúa con la SERP, y por lo tanto el CTR, varía enormemente según intención.
Segmentos mínimos recomendados:
| Tipo de búsqueda | Características comunes |
|---|---|
| Navegacional | Marca presente, intención de entrada directa |
| Informativa | Búsquedas de definición, explicación, guía |
| Transaccional | Intención de acción o compra |
Puedes clasificar las queries por patrones léxicos (regex), listas predefinidas de verbos y sustantivos, o usar modelos NLP ligeros (con spaCy o GPT).
Esta segmentación es clave para responder preguntas como:
¿El CTR en posición 1 bajó en general?
o más precisamente:
¿El CTR en posición 1 bajó en búsquedas informativas con IA Overviews?
Dividir por dispositivo y geografía
No todos los usuarios ven la misma SERP.
Y lo que aparece en mobile no se parece a desktop.
Además, el rollout de features como AI Overviews ha sido gradual según país.
Así que segmenta también por:
- Dispositivo: mobile / desktop (dato que viene de GSC)
- Ubicación: país (o región si es posible)
- Idioma de la consulta (si trabajas en mercados mixtos)
Esto te permitirá aislar efectos:
por ejemplo, que el CTR haya caído solo en mobile en EE. UU. después de mayo 2024.
Crear ventanas temporales comparables
Si estás estudiando el impacto de un cambio (como los AI Overviews), necesitas definir periodos comparables:
| Periodo | Descripción |
|---|---|
| Pre-evento | Enero 2024 – Abril 2024 |
| Post-evento | Junio 2025 (evita mayo por ruido) |
Ambos periodos deben:
- Tener duración similar
- Incluir misma cantidad de sitios
- Estar expuestos a condiciones similares (sin otras actualizaciones mayores)
Análisis estadístico, visualización e interpretación de resultados
Después de agrupar, filtrar y segmentar, ya no tienes un millón de líneas sin forma.
Tienes algo como esto:
| bucket | tipo búsqueda | dispositivo | país | CTR antes | CTR después | diferencia |
|---|---|---|---|---|---|---|
| 1 | informativa | mobile | US | 27.4% | 18.6% | -8.8 pts |
| 1 | transaccional | desktop | MX | 32.3% | 30.9% | -1.4 pts |
Esto ya puede analizarse, visualizarse… y empezar a contar algo útil.
A primera vista parece claro: el CTR en posición 1 bajó más en búsquedas informativas y en mobile.
Pero todavía no puedes sacar conclusiones.
Antes necesitas analizar estadísticamente si la diferencia es significativa, y luego interpretarla dentro del marco estratégico del SEO actual.
Tienes los datos. Ya no son una sopa de consultas, sino un conjunto limpio, estructurado y segmentado.
Pero ojo.
👉 Una diferencia en los datos no siempre implica una diferencia significativa.
Ahora viene lo que separa un estudio SEO serio de una tabla en Looker Studio:
el análisis estadístico y su interpretación.
¿Cómo sabes si la diferencia es “real”?
Cuando trabajas con grandes volúmenes de datos, todo parece tener diferencias.
Pero necesitas responder una pregunta crítica:
¿La diferencia observada en el CTR entre el periodo antes y después del evento (por ejemplo, AI Overviews) es estadísticamente significativa, o es ruido?
a) ¿Qué significa “significativa”?
Que la diferencia no se debe al azar.
Que, dadas las características de la muestra, hay una alta probabilidad de que el cambio sea estructural, no accidental.
Pruebas estadísticas que puedes aplicar
a) Prueba t de Student (dos muestras independientes)
Si comparas dos promedios (por ejemplo, CTR antes vs. después), esta es la opción estándar.
- H₀ (hipótesis nula): No hay diferencia en el CTR.
- H₁ (hipótesis alternativa): Sí hay diferencia.
Si el valor p < 0.05, puedes rechazar la hipótesis nula con un 95% de confianza.
✅ Ideal para comparar dos grupos con datos distribuidos normalmente.
b) ANOVA (análisis de varianza)
Si tienes más de dos grupos (ej. múltiples tipos de búsqueda, dispositivos, países), ANOVA permite evaluar si hay diferencias significativas entre ellos en una sola prueba.
Después puedes hacer un test post hoc (como Tukey) para ver entre qué pares hay diferencias.
c) Chi-cuadrado
Si tus datos son categóricos (ej. clic o no clic), puedes usar esta prueba para ver si hay dependencia entre variables (por ejemplo: ¿el dispositivo afecta la probabilidad de clic en posición 1 post-AI Overview?).
Visualizar los datos con intención
La visualización no es solo adorno. Es herramienta crítica para detectar patrones, comunicar hallazgos y validar hipótesis gráficamente.
Algunas formas útiles:
a) Gráfico de barras comparativas
Visualizar el CTR en posición 1 por tipo de búsqueda antes y después del cambio:
makefileCopiarEditarCTR posición 1 - Informativa (US, mobile):
Antes: ████████████████████ 27.4%
Después: ████████████ 18.6%
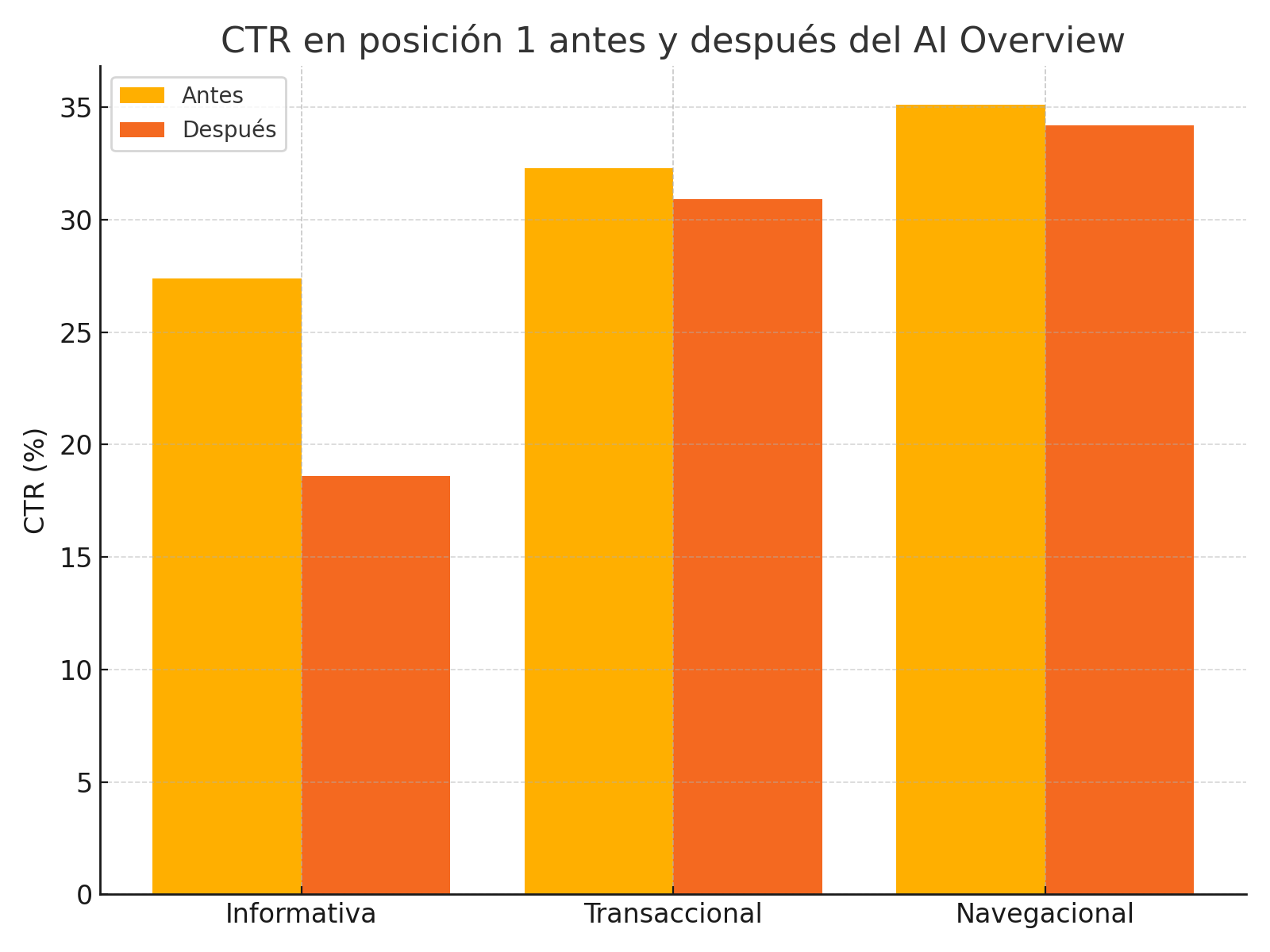
Este tipo de gráfico ayuda a ver el impacto directo por segmento.
b) Boxplots
Para mostrar la dispersión de los CTR por grupo y detectar outliers o sesgos.
- ¿Las diferencias son estables en todas las consultas?
- ¿O solo están infladas por algunos casos extremos?
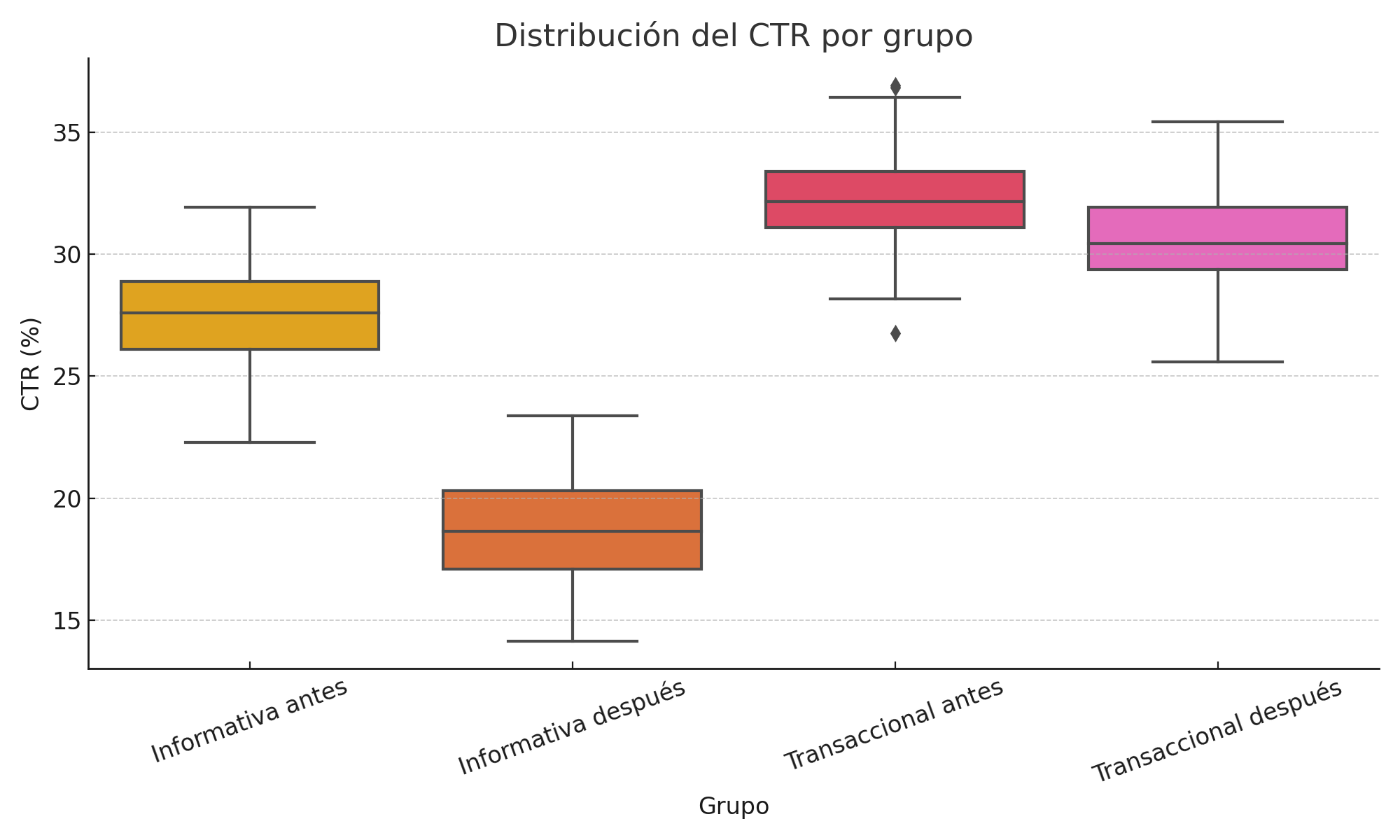
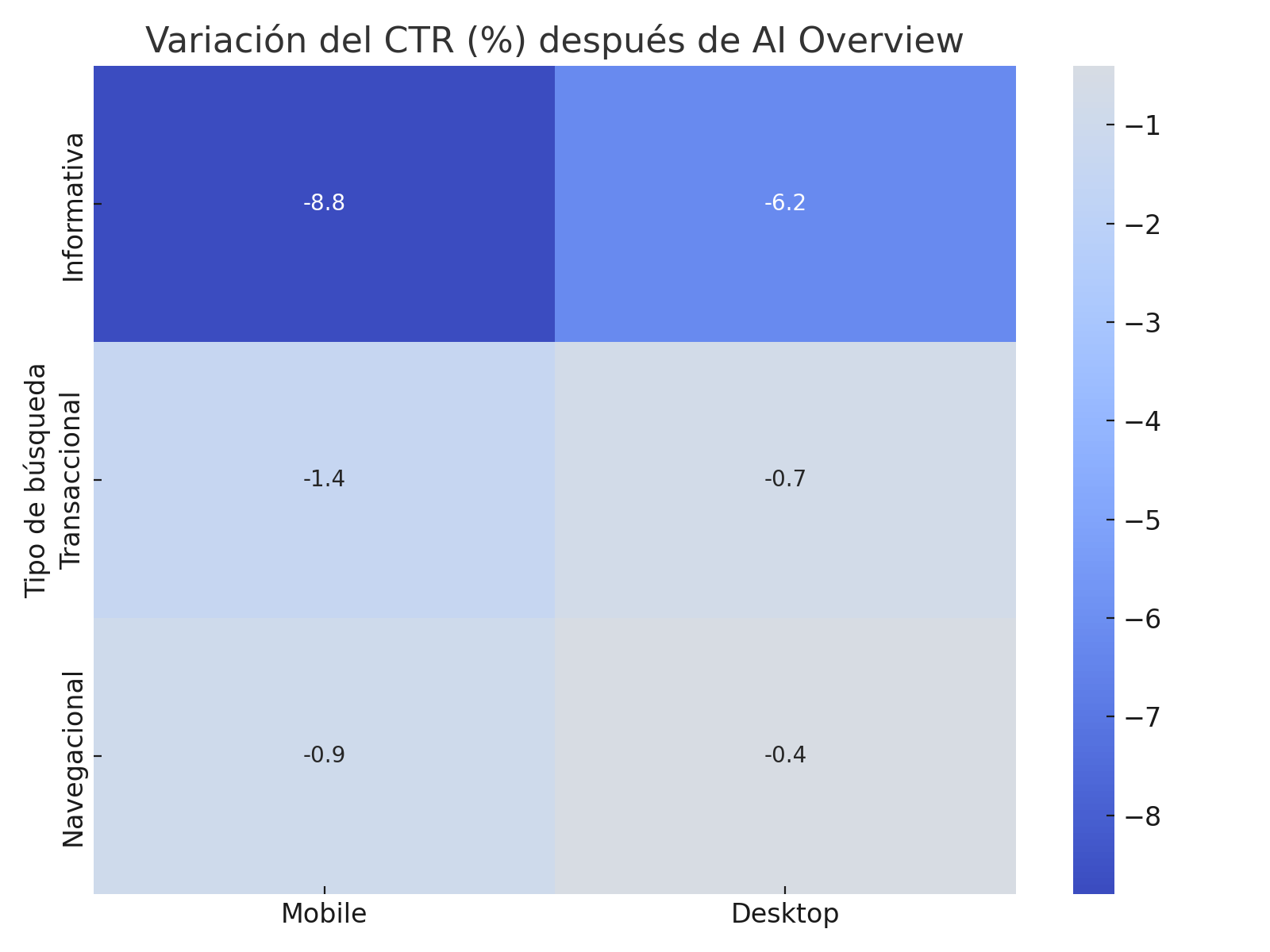
c) Heatmaps
Si tienes múltiples variables (tipo de búsqueda × país × dispositivo), puedes crear un mapa de calor para detectar dónde se concentran las caídas más significativas.
Interpretar sin sobreactuar
Una vez tienes la diferencia cuantificada y visualizada, toca lo más difícil: interpretarla estratégicamente.
Volvamos al ejemplo:
El CTR en posición 1 en mobile para búsquedas informativas en EE.UU. cayó de 27.4% a 18.6% tras el despliegue de AI Overviews (valor p = 0.002).
Esto implica:
- El cambio es significativo y consistente.
- No se limita a un sitio o sector.
- El impacto no es simétrico: transaccional y desktop se ven menos afectados.
- Es razonable inferir una correlación con la aparición del módulo IA, especialmente si el scraping visual confirma su presencia.
Pero:
- No puedes asegurar causalidad directa (podría haber otros factores: temporalidad, actualizaciones, cambios en ads).
- No puedes extrapolar a toda la web (tu muestra tiene límites).
- No puedes asumir que esto seguirá ocurriendo igual (la SERP cambia constantemente).
¿Qué hacer con estos hallazgos?
Aquí conectas la evidencia con su aplicación práctica:
a) Replantear la interpretación de “posición 1”
Ya no significa lo mismo en todos los contextos. Especialmente en mobile e informativo, puede ser un espejismo visual.
b) Incorporar contexto SERP en el reporting SEO
Ya no se reporta solo ranking, se reporta:
- Si hay IA
- Qué otros módulos aparecen
- En qué lugar de la pantalla está el resultado
c) Ajustar la estrategia de contenido
Si sabes que el CTR cae en ciertas queries, tienes dos caminos:
- Apostar a ser citado por la IA (estructura semántica + entidades)
- Apostar a queries con intención más activa o resistente al resumen automático
¿Qué no debes hacer?
- No extrapoles conclusiones globales con una muestra limitada
- No ignores los segmentos donde el CTR no cayó (puede haber oportunidades allí)
- No conviertas el dato en dogma (“el SEO murió con la IA”)
- No escondas las limitaciones del estudio (las veremos en la próxima fase)
Ya analizaste los datos, visualizaste los resultados y validaste estadísticamente que sí hay una diferencia en el CTR en posición 1 post-AI Overviews, al menos en ciertos segmentos.
Pero ningún estudio está completo sin reconocer sus límites:
qué no se pudo medir, qué se asumió, qué sesgos pueden haberse colado.
Y sobre todo, cómo documentarlo con rigor para que otros puedan replicarlo o desafiarlo.
Reconocer límites, documentar bien y traducir en estrategia
Todo estudio, por riguroso que sea, tiene bordes borrosos.
Y reconocerlos no debilita tu análisis: lo fortalece.
Uno de los errores más comunes en los estudios SEO con “datos” es ocultar las limitaciones metodológicas, asumir relaciones causales sin validarlas, o inflar conclusiones para que parezcan más impactantes.
Eso no es análisis.
Es teatro.
Si queremos que el SEO se respete como disciplina estratégica, necesitamos hacer estudios que no pretendan ser más de lo que son, pero que aporten valor, claridad y decisión.
¿Qué limitaciones debes reconocer?
a) La presencia de AI Overviews no está en los datos de GSC (por el momento)
El gran ausente.
Google Search Console no indica si una query tuvo un AI Overview en la SERP.
Así que toda medición sobre su impacto parte de inferencias indirectas:
- Por fecha del rollout
- Por tipo de query
- Por scraping paralelo
- Por análisis visual
¿Consecuencia?
No puedes asegurar con certeza absoluta que todas las queries post-junio 2025 tenían IA activa. Solo puedes estimar una alta probabilidad en ciertos casos.
Y recuerda que ni siquiera aparece la data de la búsqueda por voz en la Search Console…
b) No todas las queries de un bucket son iguales
El bucket 1 (posición promedio entre 1.0 y 1.2) no garantiza visibilidad máxima.
El resultado puede estar:
- Debajo del bloque de IA
- Después de un Featured Snippet
- En el primer scroll en desktop, pero fuera de pantalla en mobile
¿Consecuencia?
Posición promedio y visibilidad real no son lo mismo.
El CTR está influido por lo que ocurre antes de que aparezca el resultado orgánico.
c) El CTR no depende solo de la interfaz
Aunque el diseño de la SERP tiene un impacto claro, el CTR también está determinado por:
- La marca (queries branded vs. no branded)
- El título y metadescripción
- El tipo de URL (homepage, artículo, categoría, producto, servicio, sucursales)
- La competencia
- La intención de búsqueda
¿Consecuencia?
No puedes aislar el CTR como métrica pura de posición.
Es un síntoma compuesto de muchos factores.
d) El tráfico no es lineal: puede haber efectos combinados
La caída del CTR en ciertos segmentos puede coincidir con:
- Cambios de algoritmo
- Eventos estacionales
- Cambios en los anuncios pagados
- Actualizaciones visuales no relacionadas con IA
¿Consecuencia?
Evita atribuir todo el efecto a un solo factor (la IA), incluso si la correlación es fuerte.
Documentar todo el proceso (para ti y para otros)
Un estudio SEO serio debe poder ser replicado, adaptado, o al menos auditado.
Eso implica dejar claro:
- Cómo se extrajeron los datos (GSC API, filtros aplicados)
- Qué criterios se usaron para definir buckets de posición
- Cómo se segmentaron las consultas (intención, marca, etc.)
- Qué herramientas estadísticas se aplicaron
- Cuál fue el volumen por segmento y grupo
- Qué se excluyó y por qué
Esto no es burocracia.
Es lo que separa un insight de un accidente.
Además, si tú mismo repites el estudio en 6 meses, agradecerás haber documentado tus decisiones de forma clara.
¿Se puede replicar el estudio?
Sí, si haces bien lo anterior.
De hecho, la mejor forma de validar un estudio SEO es replicarlo con otra muestra:
- Otros sitios
- Otro país
- Otra industria
- Otro periodo post-rollout
Por ejemplo:
¿El CTR en posición 1 también cayó en búsquedas educativas en España tras el despliegue de IA?
¿En ecommerce hubo menos caída que en medios?
¿Hay sectores donde el CTR subió porque la IA deja espacio?
Eso se responde con replicación, no con intuición.
¿Y cómo se convierte esto en estrategia?
Aquí está el verdadero objetivo.
Este tipo de estudio no se hace para llenar un PDF.
Se hace para decidir mejor.
a) Replantear objetivos de posicionamiento
Si la posición 1 ya no garantiza atención, deja de obsesionarte con ella.
Posicionar en el bucket 2 con mejor visibilidad puede ser más rentable que estar enterrado detrás del módulo IA en el bucket 1.
b) Medir lo que realmente importa
Cambia tu métrica base:
- De “ranking promedio” → a “CTR ponderado por visibilidad”
- De “palabra en posición 1” → a “palabra con clic efectivo neto por grupo de features”
c) Diseñar contenido que sobreviva la IA
- Si el AI Overview cita fuentes: sé esa fuente
- Si resume tu contenido: estructura para ser resumible
- Si elimina la necesidad del clic: orienta tus esfuerzos a queries con intención activa
Este estudio no es importante por el CTR.
Es importante porque te enseña a pensar el SEO desde el dato estructurado y no desde la mitología.
No es para demostrar que Google nos odia.
Es para entender cómo se distribuye la atención hoy.
Y para que cada decisión de contenido, optimización y arquitectura esté respaldada por evidencia.
Después de recorrer el proceso completo (desde la hipótesis hasta la interpretación), podrías:
- Convertir este estudio en una plantilla replicable para otros clientes o sectores
- Publicar el artículo como referencia para otros SEOs o stakeholders
- Integrarlo como módulo de formación en consultoría o capacitaciones SEO
- Producir una visualización interactiva o dinámica a partir de los datos
Y sobre todo:
Hacer que tu equipo, tus clientes o tus alumnos dejen de preguntar
“¿Y si salimos en posición 1, ya con eso, no?”
y empiecen a preguntar
“¿Qué hace que una búsqueda realmente termine en nuestro sitio?”
No se trata del CTR, se trata de cómo medimos el SEO en serio
Cuando decimos que el SEO necesita madurar como disciplina, no estamos hablando de cambiar el tono de los reportes o usar sinónimos de “optimización” para sonar más consultivos.
Estamos hablando de cambiar la forma en que construimos conocimiento.
De dejar de depender de intuiciones, de “me pasó en mi sitio”, de herramientas que simulan ciencia con sliders interactivos…
y empezar a pensar en serio: ¿cómo sabemos lo que creemos saber?
Este estudio, centrado en el impacto de los AI Overviews sobre el CTR en posición 1, no es valioso por el resultado.
Es valioso porque muestra cómo se hace.
Cómo se trabaja con grandes muestras.
Cómo se define una hipótesis que no sea un tuit.
Cómo se limpia un dataset hasta que duela.
Cómo se visualiza sin vender humo.
Cómo se duda de las conclusiones, incluso cuando confirman lo que esperabas.
Y, sobre todo, cómo se traduce un hallazgo en una decisión estratégica:
replantear KPIs, redibujar prioridades, reeducar a los equipos y explicar al cliente que no basta con estar primero, si nadie te ve.
¿Por qué esto importa ahora?
Porque estamos entrando en una era donde la interfaz importa tanto como el contenido.
Donde el usuario ya no navega… conversa.
Y donde la visibilidad no se mide por posición, sino por contexto, percepción y utilidad.
Hacer estudios SEO con rigor, con escala y con cabeza, no es opcional.
Es la única forma de que esta disciplina no se convierta en un conjunto de automatizaciones y clichés sin capacidad crítica.
No es que el CTR haya caído.
Es que dejamos de medir con precisión en el momento en que Google empezó a cambiar las reglas del juego más rápido que nosotros los métodos para entenderlo.
Si no sabemos cómo medir, no sabremos qué defender.
Y si no defendemos nada, el SEO no es una estrategia: es una superstición con plan de contenidos.


