
Esta es una de las principales tendencias actuales en el pequeño mundo del SEO: el Data Science o la ciencia de datos. En esta presentación trataré de descifrar este nuevo camino de nuestra profesión, de darte algunas claves para que te subas al barco y para que quieras ir más allá en una disciplina que está resultando realmente imprescindible en el ámbito del posicionamiento orgánico.
La explosión cámbrica de la data
Los biólogos se refieren a la explosión Cámbrica como el periodo (corto en una escala geológica) de hace unos 540 millones de años en el que la vida en la Tierra se desarrolló considerablemente. Evolucionó desde organismos simples, a menudo unicelulares, hasta los primeros animales de tamaño métrico.
Un fenómeno muy similar se ha producido en los últimos años con el big data: la cantidad de datos generados no deja de aumentar. Por ejemplo, IBM estimó en 2013 que el 90% de los datos disponibles en el mundo se habían creado en los dos años anteriores. El ritmo no ha hecho más que acelerarse desde entonces.
Durante el período Cámbrico, podemos considerar que la naturaleza hizo pruebas: animales con 5 ojos, otros con una pinza colocada en el extremo de una trompa, espinas como extremidades inferiores… ¡Esto es muy similar al trabajo de un Data Scientist, cuyos experimentos no siempre tienen éxito!
Esta explosión puede atribuirse a varios factores. En primer lugar, el almacenamiento de estos datos es cada vez más barato, lo que fomenta el almacenamiento de cualquier cosa. Además, la potencia de cálculo ha aumentado considerablemente a lo largo de los años, lo que permite procesar conjuntos de datos de varios millones de líneas, incluso en una computadora personal. Por último, la moda del big data ha hecho que las herramientas y métodos de procesamiento de datos sean más populares y aplicables a una variedad cada vez mayor de temas.
Machine Learning, Data Science, NLP, inteligencia artificial: estos términos, que antes se consideraban buzzwords, constituyen ahora un campo de especialización reconocido, con aplicaciones reales… ¡y puestos de trabajo reales!
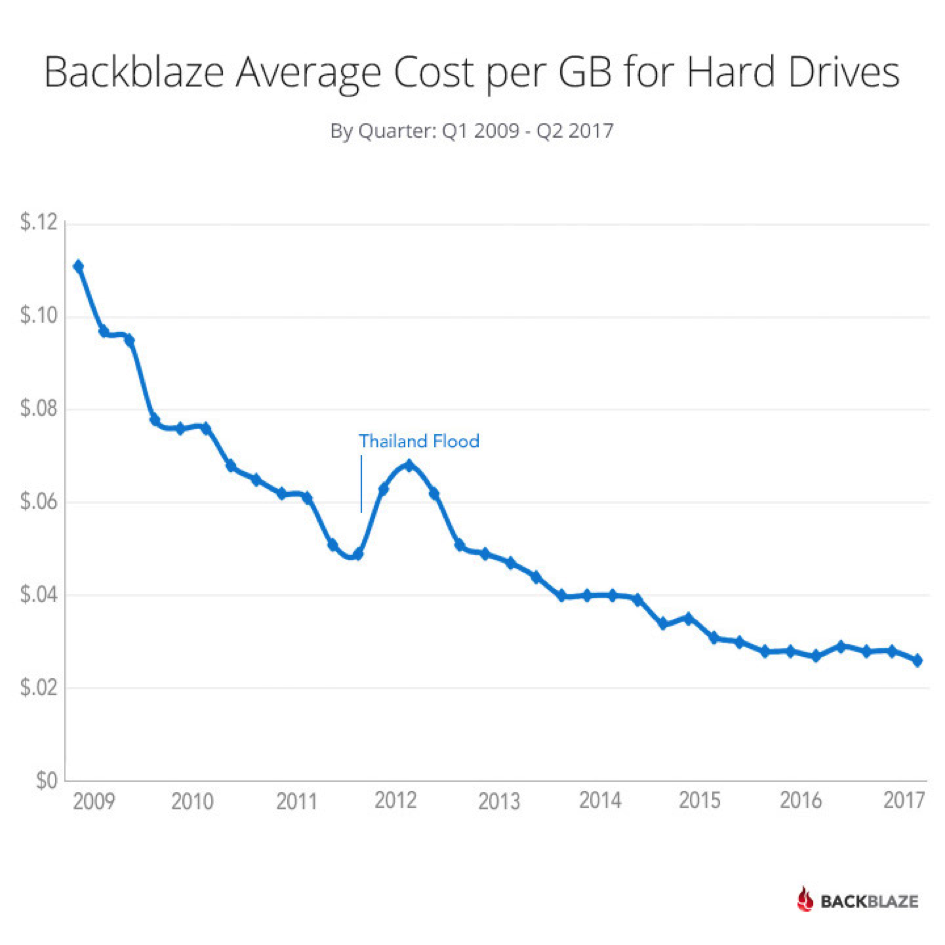
El pequeño mundo del SEO no se queda atrás: cada vez tenemos acceso a más datos: seguimiento de posiciones, tráfico, enlaces externos, crawl, logs del servidor, análisis semántico… Cada vez hay más herramientas que nos ofrecen más datos, y más análisis relevantes. Uno de los ejemplos más reveladores de este fenómeno es el aumento del número de búsquedas monitoreadas por las herramientas de seguimiento de visibilidad.
En paralelo a este aumento de la gama de herramientas, ha aparecido un nuevo término: La ciencia de datos SEO. ¿La idea? Aplicar las técnicas de la Data Science al campo del posicionamiento orgánico, y tomar decisiones racionales basadas en el análisis de datos.
¿Una extensión del SEO técnico?
Este deseo de mejorar y profundizar en el análisis no es nuevo para la mayoría de los SEO, sobre todo para los que trabajan en sitios con gran volumen de páginas o tráfico: los famosos “SEO técnicos”.
En la práctica, el uso de los métodos Data Science abre la puerta al análisis cruzado, lo que permite relacionar indicadores de diferentes fuentes a una escala mucho mayor que en el pasado.
Esto permite abarcar temas más alejados de los aspectos puramente técnicos del SEO, y de fijarse en los enlaces externos o en la calidad de los contenidos.
La combinación de estos diferentes indicadores ofrece la posibilidad de estimar los factores de clasificación utilizados por los motores de búsqueda, o incluso predecir el posicionamiento de una página. Concretamente, puedes calcular las correlaciones entre los KPIs que tienes para un conjunto de páginas y la posición que obtiene cada página para una búsqueda determinada, con el fin de determinar los criterios más importantes a trabajar según tu temática.
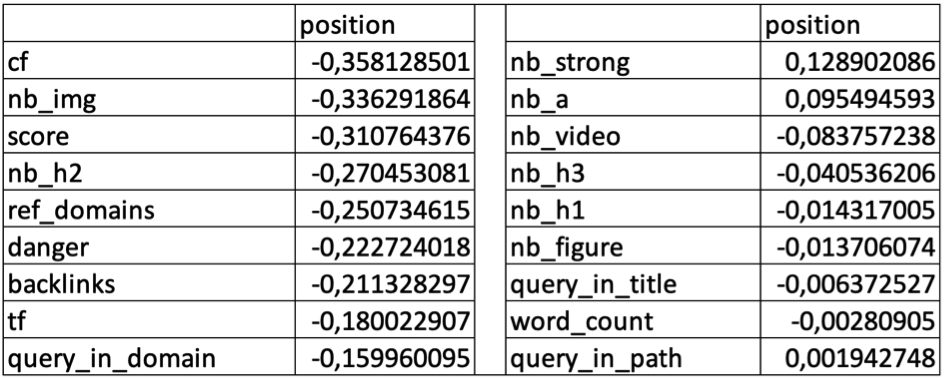
La Data Science también proporciona la capacidad de ir más allá del simple análisis. Por ejemplo, las soluciones de *Natural Language Processing* (NLP) o Procesamiento del Lenguaje Natural (PLN) pueden generar contenidos automáticamente.
Aunque la calidad de los resultados todavía no es muy satisfactoria, se trata de una rama del Machine Learning que está progresando muy rápidamente.
Como habrás comprendido, el Data SEO no se limita a los problemas técnicos del posicionamiento orgánico, sino que nos permite tratar temas mucho más variados.
Las ventajas de la ciencia de datos SEO
El enfoque de la ciencia de datos en SEO también tiene beneficios indirectos, que van más allá de la profesión de SEO.
El interés por los algoritmos de Machine Learning permite entender mejor el funcionamiento de los motores de búsqueda. Más allá del [PageRank] y sus derivados, los motores de búsqueda están llenos de Machine Learning e inteligencia artificial: conocer y entender los conceptos y procesos utilizados por Google y sus competidores te dará una ventaja sustancial para saber cómo conseguir mejores posiciones en las SERPs. Este es el verdadero reto del la ciencia de datos en SEO: mezclar la teoría y la práctica.
Además, los métodos utilizados por los motores de búsqueda son muy similares a los utilizados en otras situaciones. Por ejemplo, si se trata de mostrarte productos similares a los que has comprado como de elegir las próximas películas que te van a proponer, los algoritmos de Amazon y Netflix se basan en la misma lógica de recomendación.
Diseñar su propio sistema de recomendación resulta bastante accesible: encontrarás ejemplos bastante concretos en la web, que podrás adaptar a tus problemáticas.
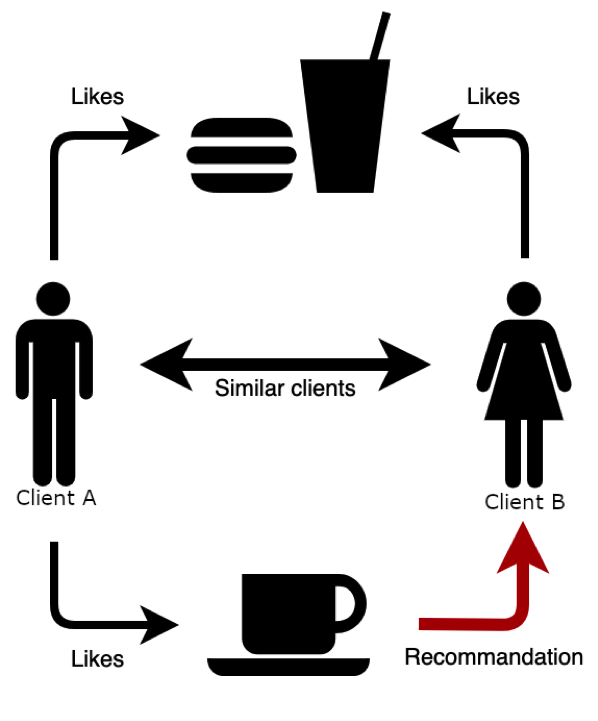
Si a los clientes A y B les gusta el mismo producto, cuando al cliente A le gusta un nuevo producto, podemos sugerírselo al cliente B.
Del mismo modo, nada te impide afinar tus habilidades de Data Scientist en problemáticas relacionadas al SEO, para luego aplicar tus conocimientos a diferentes trabajos: ya sea para identificar las páginas a optimizar en un sitio web o para elegir la próxima inversión financiera a realizar, un árbol de decisión siempre funciona de la misma manera.
Por último, aunque las herramientas del mercado son cada vez más accesibles y fáciles de usar, a menudo es necesario meter manos en el código para personalizar los análisis. Esto puede parecer desalentador, pero ser autónomo en un lenguaje de programación es una verdadera ventaja, sea cual sea tu profesión.
En efecto, ya sea en R, Python o cualquier otro lenguaje, aprender a desarrollar te da la posibilidad de automatizar tareas repetitivas.
Para ir más allá…
Si este alegato a favor de la ciencia de datos en SEO te ha dado ganas de ir más allá, hay muchos recursos disponibles. En la red abundan los libros, los blogs y los cursos generalistas en línea sobre la ciencia de los datos.
Del mismo modo, hay un número creciente de recursos específicos para SEO.
Esta abundancia de posibilidades garantiza que encontrarás el enfoque adecuado para ti, tanto si te interesa principalmente la teoría como la práctica.
Sin embargo, hay algunos puntos clave que conviene destacar:
- Empieza por dedicar algo de tiempo a la teoría, lo que te ahorrará muchos problemas más adelante. En particular, algunos algoritmos requieren una cantidad suficiente de datos para dar resultados representativos: saber identificarlos.
- Como se ha mencionado anteriormente, aprender un lenguaje de programación: esto será una verdadera ventaja en un enfoque de SEO de datos. Aunque Python y R son los más utilizados entre los SEO, muchos otros lenguajes ofrecen un ecosistema adecuado para la Ciencia de Datos.
- Por último, trabajar en DataViz también es esencial: ejercemos una profesión en la que la comunicación suele ser clave, por lo que es importante encontrar las formas adecuadas de representar los datos, para que el mensaje que se quiere transmitir sea entendido con la mayor naturalidad posible por tus interlocutores. Existen muchos libros sobre el tema, y también puedes consultar los ejemplos propuestos en Python Graph Gallery, R Graph Gallery o incluso los de the D3js library.
La ciencia de datos para SEO no es una simple moda, es una verdadera y nueva forma de entender el SEO. Este enfoque no cuestiona los métodos más tradicionales, pero permite actuar con serenidad.
Debe verse como una oportunidad para mejorar tus procedimientos y ampliar el alcance de los temas que puedes tratar.
Por último, a medida que los motores de búsqueda se vuelven más y más complejos, es probable que pronto sea esencial practicar la ciencia de datos en SEO para seguir siendo competitivo en las SERP. Debemos investigar estas nuevas vías lo antes posible…
Las herramientas para hacer ciencia de datos en SEO
El campo de ciencia de datos puede parecer complejo a veces, pero nos permite automatizar acciones o analizar grandes cantidades de datos. En esta guía, intentaré explorar el mundo de la Ciencia de Datos aplicada al SEO. En esta primera parte, hablaremos de qué herramientas utilizar, en función del presupuesto que tienes disponible.
El data SEO es un enfoque científico del SEO que se basa en el análisis de datos y el uso de la ciencia de datos para tomar decisiones.
Hay tres categorías principales de proyectos en data SEO:
- Predicción: predicción de factores de clasificación, tráfico futuro y generación de texto.
- Clasificación: asignación de una clase/categoría a cada URL y texto.
- Comprensión de datos: explorar y evaluar la calidad de los datos de tus sitios o de los de la competencia.
Mitos del Data SEO
Muchos expertos en SEO han probado e innovado y han nacido proyectos muy ambiciosos. Además, desde hace dos años, el tema se discute con regularidad en conferencias sobre SEO en México y a nivel internacional.
Por otro lado, hay muchos mitos sobre el tema, así como sobre la temática de la inteligencia artificial en su sentido más amplio.
Primer mito: “El Data SEO es para sitios grandes”
Uno de los objetivos del Data SEO es la automatización, e de manera independiente al tamaño del sitio, seguro que hay cosas que automatizar. Incluso sin entrar en grandes temas como la generación de contenidos, hay muchas técnicas de ciencia de datos como la detección de anomalías que pueden detectar variaciones sensibles o fuertes en tus datos de Google Analytics, Google Search Console, Crawl y Logs. Esto permite aplicar parches muy rápidamente (las últimas técnicas permiten hacerlo automáticamente vía una CDN). En segundo lugar, las auditorías SEO pueden ser muy automatizadas, especialmente en la investigación de palabras clave, lo que ahorra mucho tiempo (hasta varios días de ahorro).
Segundo mito: “El Data SEO es caro”
El Data SEO puede hacerse en modo “low cost” y si utilizas software de código abierto (open source) como Jupyter Notebook (con Python) o RStudio (con R), no te costará ni un centavo. Lo único que puede resultar caro es simplemente el acceso a las API de los diferentes software del mercado. Más adelante volveremos al famoso dilema “Make or Buy”: ¿debes comprar o crear tus herramientas?
Tercer mito: “El Data SEO es complicado”
En varias formaciones que he podido participar, a menudo he visto a alumnos sin conocimientos científicos, e incluso sin conocimientos de programación, hacer progresos muy significativos en sólo dos días, para acabar dominando todos los conceptos básicos. Además, ahora hay muchísimos cursos online *vía* cursos largos como Coursera.org o Datacamp.com.
Creo que a menudo confundimos a los que utilizan la ciencia de datos con una buena base y a los que crean algoritmos de ciencia de datos para trabajos de investigación. Tomemos el ejemplo del GPS: muchas personas utilizan un GPS cada día introduciendo un punto de partida y un destino. Y sin embargo, muy pocos sabrían dar las ecuaciones matemáticas y detallar el funcionamiento de los satélites que orbitan la Tierra.
Para el Data SEO, es exactamente lo mismo: desde hace 3 años, existen muchas herramientas que guían, ayudan y aconsejan en el uso e interpretación de los resultados.
Por lo tanto, en esta primera parte hablaremos de los 3 métodos principales para hacer Data SEO, pero sobre todo de las herramientas que son imprescindibles si tienes un gran presupuesto o si no lo tienes. De hecho, depende principalmente de dos factores: el presupuesto que puedes asignar y tu crecimiento.
Herramientas para grandes presupuestos
Volvamos a la terrible elección dedel Make or Buy: ¿debes crear tus propias herramientas o comprar las existentes?
Si inviertes tiempo en la creación de una herramienta, sea cual sea el tamaño de tu equipo, tendrás que garantizar el mantenimiento, las actualizaciones, la seguridad y la documentación, así como el desarrollo continuo. A menudo es un coste que se pasa por alto, pero lo más importante es que perderás un tiempo valioso en la implantación de la solución. ¿Puedes esperar varios meses sin estos valiosos datos? ¿No es mejor tomar una licencia de un software que funciona, en lugar de intentar recrear la rueda?
La elección será dictada por tu crecimiento y tu presupuesto, pero la peor solución es haber pasado 6 meses desarrollando un software que aún no funciona.
Si puedes comprar herramientas, aquí tienes una lista de las mejores hoy en día:
- Una plataforma de Ciencia de Datos: Las plataformas de Ciencia de Datos son relativamente útiles si tienes el presupuesto porque duplican o incluso triplican tu productividad gracias a todos los conectores Big Data que ofrecen, un sistema de colaboración y seguridad excepcional, así como una ejecución sostenible de las tareas con flujos de trabajo que te permiten optimizar e identificar los puntos débiles. Es posible tener todas las herramientas de ciencia de datos en un solo lugar servido con una interfaz gráfica y proyectos starters que permiten iniciar rápidamente cualquier nuevo proyecto. En definitiva, un must-have si dispones de un buen presupuesto. He aquí les dejo una lista no exhaustiva de soluciones: Dataiku Enterprise, Databricks;
- Dos Cloud Providers: para el procesamiento y almacenamiento de datos: ciertamente puedes alojar tus datos en tu datacenter, pero lo ideal es siempre utilizar uno o más Cloud Providers para garantizar el acceso a tus datos favoreciendo el rendimiento y la seguridad. Esta es una lista no exhaustiva de soluciones: Google Cloud, OVH Cloud, AWS, Microsoft Cloud;
- Un Customer Relationship Management: El CRM es un concepto muy importante para almacenar los datos relacionados con tus clientes. Los datos business son esenciales para estructurar tus servicios y para tener éxito en tus proyectos Data Science (detección de churn, clusterisación de clientes, automation, etc.). Si tienes un gran presupuesto: Microsoft Dynamics CRM, Sales Force, Zendesk;
- Una solución de Web Analytics: las soluciones de analítica gratuitas como Google Analytics tienden a enseñar sólo muestras de tus datos y a poner cuotas a los grandes volúmenes, tendrás que recurrir a productos más eficientes como: Google Analytics Premium y AT Internet;
- Una solución Dataviz: para visualizar los datos, puedes elegir entre programar cada vista o Drag and drop en soluciones ya preparadas, las mejores soluciones de pago hasta la fecha siguen siendo: Tableau Software, Power BI y Qlik View;
- Un Crawler y un Analizador de logs: es importante rastrear regularmente tus sitios, para hacer análisis cruzados con otras fuentes de datos (Logs, Google Search Console, Google Analytics), más adelante se mencionarán soluciones gratuitas pero en mi opinión los dos líderes siguen siendo: OnCrawl, Botify y Content King. Especialmente para sitios muy grandes, OnCrawl se ha especializado en el GigaCrawl: la capacidad de rastrear sitios con más de 250 millones de URLs y en Javascript;
- Dos keyword tools: en realidad hay tres escuelas aquí, los que sólo usan Search Console, los que sólo usan las herramientas de palabras clave y los que usan ambas. Realmente depende de tu sitio y de sus competidores. En Latino América, las herramientas más conocidas son : SEMRush, AHrefs, y SE Ranking.
Luego, entre todas estas herramientas, necesitarás acceder a sus diferentes APIs y desde ahí podrás automatizar todo si tienes conocimientos de programación o un desarrollador que te ayude. Dependiendo de la solución de software, las APIs pueden ser más o menos caras y puedes negociarlas en la fase de presupuesto. Lo más importante es saber, para cada uno de estos softwares, lo fácil que es sacar los datos en bruto para utilizarlos en tus proyectos de Data SEO.
Ahora bien, esta es la receta low-cost, obviamente habrá menos opciones y mucho más mantenimiento que gestionar.
Herramientas Data SEO “low-cost”
Volvamos a la terrible elección del Make or Buy. En este caso, la respuesta es sencilla: tendrás que crear tus propias herramientas o recurrir al open-source.
También tendrás que prescindir de todas las API y trabajar en su lugar con exportaciones de archivos CSV o Excel. Existen soluciones que permiten simular clics o pulsaciones de teclas y así automatizar la recuperación de archivos CSV, pero esto seguirá siendo un enfoque de bricolaje.
Si no puedes permitirte comprar herramientas o si tu presupuesto se limita a 30 dólares mensual, aquí tienes la receta de las mejores herramientas Data SEO hoy en día:
- Una plataforma de Data Science: en el modo low cost, tendrás que renunciar a una plataforma de este tipo para lanzar proyectos de forma rápida y automática, pero eso no te impide probar Dataiku Community (acá la versión gratuita) y automatizar por tus propios medios mediante scripts de Python o R. En cualquier caso, la modalidad de low cost requerirá conocimientos de programación. De lo contrario, te aconsejo vivamente que utilices Google Colab, porque no hay que configurar nada y la herramienta te permite beneficiarte de un GPU gratuito durante 12 horas con la versión gratuita y 24 horas con la versión Pro (a 12€/mes);
- Sin Cloud Provider para el procesamiento y almacenamiento de datos: en este caso, puedes ejecutar scripts de R o Python desde tu computadora y almacenar todo en Google Drive ;
- Un CRM: No hay que descuidar el CRM, incluso sin presupuesto para facilitarte la vida en la gestión de tus clientes. Esta es mi selección: SugarCRM, una solución de código abierto. (Prever alojamiento por 10€/mes.);
- Una solución de Web Analytics: de nuevo, uno podría pensar que Google Analytics es suficiente, pero la solución Matomo Analytics está ganando terreno y ofrece opciones muy avanzadas: Mapas de calor, grabaciones de sesiones, pruebas A/B, Embudos, análisis de visitantes, funcionalidades SEO avanzadas, Tag Manager, GDPR Manager; etc.
- Varias soluciones de DataViz: todo el mundo se precipita hacia Google Data Studio, que se está convirtiendo en una referencia en el campo del SEO, pero con un poco de programación en R (con GGplot y Shiny) o Python (con Dash), el resultado puede ser sorprendente porque se apuesta por la personalización. Pero ten cuidado: tendrás que garantizar el mantenimiento, la estabilidad y la seguridad de la aplicación. Si no sabes programar, puedes probar la dataviz open-source metabase que es fácil de aprender;
- Un Crawler y Analizador de logs : la suite ELK (Elastic Search – Logstash – Kibana) es correcta para los logs, tendrás que crear todos los dashboards y para el crawl, softwares como Screaming Frog (si tienes menos de 500 urls es gratis: puedes hacer el trabajo de forma simplificada. Estas herramientas siguen siendo accesibles y eficaces para los sitios de tamaño medio;
– Una keyword tool: la Search Console, o bien tendrás que hacer malabares con los proxies, pero esto es algo que hay que evitar porque el coste de mantenimiento, proxies y almacenamiento suele ser mayor que las licencias de las herramientas del mercado.
En el sector del gratis, hay muchas comunidades de apoyo, la más conocida es, por supuesto, Stackoverflow donde siempre encontrarás una respuesta a tus problemas de programación. Luego, entre las redes, hay que fijarse en los desarrolladores o ponentes presentes en GitHub y Twitter. Estas dos redes siguen siendo las favoritas para encontrar una respuesta y el intercambio es bastante sorprendente.
El compromiso correcto entre estas diferentes herramientas
El modo híbrido te ofrece el mejor equilibrio desde el punto de vista de la calidad y precio. Permite configurar un SEO Datamart (forma sencilla de un almacén de datos que se centra en un único tema o línea de negocio, como ventas, finanzas o marketing) que puede ser utilizado directamente por los data scientists con las tecnologías más comunes.
- Una plataforma de ciencia de datos: En este modo, puedes considerar la versión Discover de Dataiku, que sigue siendo un buen punto de partida. Si tu equipo trabaja exclusivamente en R, un Rstudio Server Pro puede ser suficiente. De hecho, lo que realmente necesitas es una forma de ejecutar fácilmente los flujos de trabajo de Datos y/o Machine Learning;
- Un Cloud Provider para el procesamiento y almacenamiento de datos: Con un mínimo de presupuesto, puedes elegir al menos un cloud provider de la lista: OVH, Google, Microsoft, y descarto AWS que sigue siendo muy caro;
- Un CRM: el CRM no debe descuidarse incluso sin presupuesto para respetar ya las limitaciones del GDPR y sobre todo para facilitarte la vida en la gestión de tus clientes. Esta es mi lista: Close y Pipedrive por 15 €/mes;
- Una solución Web Analytics: Pequeña repetición, pero una vez más la solución Matomo Analytics gana terreno a Google Analytics y ofrece opciones muy avanzadas : Mapas de calor, grabaciones de sesiones, tests A/B, embudos, análisis de visitantes, funciones SEO mejoradas, Tag Manager, GDPR Manager ;
- Varias soluciones DataViz: puedes seguir con Google Data Studio, pero prueba el dataviz open-source Metabase que es fácil de aprender. Con un poco más de presupuesto, me inclinaría por el Power-BI que sigue siendo accesible con pocos usuarios;
- Un Crawler y un Analizador de logs: Estoy predicando al coro aquí, pero OnCrawl parece ofrecer la mejor relación calidad/funcionalidad;
– Un keyword tools: Search Console es útil. Entonces, mi segunda opción sería SE Ranking sigue siendo muy accesible comparado a otras soluciones mas conocidas.
Acabamos de ver herramientas para tener datos de calidad. Se trata de una base indispensable para hacer la Data Science y proyectos a gran escala, como la predicción de factores de clasificación. Sea cual sea tu presupuesto, es posible hacer Data Science y la tendencia es hacer cada vez más accesibles los conceptos que utilizan los Data Scientists.
Hablamos a menudo de la inteligencia artificial, pero el tema se malinterpreta en nuestro caso. Se trata de inteligencia aumentada… La data y la Data science permiten gestionar más proyectos y de forma más cualitativa.

Como habrás adivinado, el Data SEO no se limita a la Data science. Vamos a seguir, tratando aspectos desconocidos pero esenciales para facilitar y garantizar los resultados. De hecho, prefiero hablar de Data SEO y no de Data Science SEO, porque claramente hay 3 especialidades que hay que dominar de manera directa o indirecta además del SEO, como el Data Analyst o el Data Engineer.
Pero eso lo vamos a ver ahorita mismo…
Empleos en Data SEO
El campo del Data SEO puede parecer complejo a veces, pero nos permite automatizar acciones o analizar grandes cantidades de datos. En esta charla sobre el tema, intento explorar el mundo de la Data Science aplicada al SEO. Después de presentar las herramientas, aquí están los puestos de trabajo con una descripción del papel de los Data Scientists, Data Analysts y Data Engineers en una empresa.
El Data SEO es un enfoque científico del SEO que se basa en el análisis de datos y el uso de la ciencia de datos para tomar decisiones. Sin importar el presupuesto, es posible hacer data science y la tendencia es hacer que los conceptos utilizados por los Data Scientists sean cada vez más accesibles.
El Data SEO no se limita a la data science. De hecho, es preferible hablar de Data SEO y Data Science SEO porque claramente hay 3 especialidades que hay que dominar de manera directa o indirecta, además del SEO: son las profesiones de Data Scientist, Data Analyst o Data Engineer.
El Data Engineer
Los Data Engineers son los profesionales de los datos que preparan la infraestructura de Big Data que sirve de base a la empresa.
Suelen ser ingenieros de software que diseñan, construyen, integran datos de diversos recursos y gestionan cantidades muy grandes de datos.
El objetivo principal es optimizar el rendimiento del acceso a los datos de la empresa. En el caso de grandes empresas, trabajan con un responsable jurídico para el cumplimiento del RGPD y un responsable de seguridad.
A menudo utilizan ETLs (Extract, Transform and Load) y crean grandes almacenes de datos (Data WareHouse) que pueden utilizarse para la elaboración de informes o análisis.
Las principales competencias pueden resumirse en la siguiente lista: Hadoop, MapReduce, Hive, Pig, streaming de datos, NoSQL, SQL, Programmation.
¿Por qué deberías centralizar tus datos?
En primer lugar, tu tiempo no es extensible y es una pérdida de tiempo hacer malabares entre herramientas, pero también una pérdida de información al no poder cruzar datos de diferentes fuentes.
Por ejemplo, para que los datos de backlinks sean procesables, es necesario vincularlos a los resultados que un backlink puede proporcionar a un sitio web. En el mercado hispanohablante, SE Ranking es de las mejores herramientas para centralizar en un solo lugar el seguimiento de los rankings y la consulta de los backlinks de cualquier sitio presente en las palabras clave más interesantes. De este modo, dispondrás de una herramienta “llave en mano” que podrás accionar directamente.
Después, hay que cruzar estos datos con los datos de la industria (CRM), los datos business (Finanzas) y muchos otros datos que son siempre muy sensibles. Por lo tanto, es conveniente construir su SEO Datamart, es decir, un almacén de datos específico para el SEO, comprobando que tus herramientas SEO permiten exportar los datos correctamente.
El Data Engineer es la persona más competente para centralizar todos estos datos que pueden variar :
- Datos no estructurados: textos, comentarios ;
- Datos estructurados: base de datos, API.
Sin embargo, hay muchas dificultades. La primera es el volumen de información. Si tienes más de 100.000 páginas y mucho tráfico, los rastreos semanales y los logs diarios ocuparán rápidamente mucho espacio. Esto se vuelve aún más complejo si se añaden los datos de tu CRM y la información de la competencia.
A menudo, si el sistema no se basa en las tecnologías adecuadas como lo vimos anteriormente, puedes tener datos incompletos, faltantes o falsos.
Además del volumen de datos, hay muchas trampas, como los problemas de divisas si se trabaja a nivel internacional, donde habrá que lidiar con los tipos de cambio que emite el Banco nacional. Pero también con las diferencias horarias, si calculas una facturación por día y parte de la facturación se hace en Canadá, por ejemplo, tienes que lanzar el cálculo cuando es medianoche en Canadá y no medianoche en España. En resumen, esto es sólo un breve resumen de este negocio lleno de trampas.
En segundo lugar, hay que controlar con mucho cuidado la veracidad de los datos. De hecho, los datos pueden corromperse rápidamente:
- Un JavaScript para Google Analytics desaparece y tus datos de tráfico se vuelven erróneos;
- Una API cambia sus parámetros de retorno y varios campos dejan de tener valor;
- Una base de datos ya no se actualiza porque el disco duro está lleno.
- Etc.
En todos los casos, hay que detectar rápidamente este tipo de anomalías y corregirlas lo antes posible, ya que de lo contrario los dashboard producidos por estos datos serán erróneos y es muy tedioso lanzar scripts retroactivos para recalcular todo.
Si no tienes un Data Engineer en tu equipo, al menos deberías tener un responsable que compruebe la coherencia de los datos que se recuperan de las distintas herramientas SEO.
Las herramientas de SEO permiten ahora obtener fácilmente los siguientes datos y hay que vigilar las variaciones que van hacia arriba o hacia abajo:
- Datos Analytics: script perdido, error de tracking ;
- Datos de Crawl: Crawl demasiado largo, Crawl cancelado;
- Datos del Logs: periodos faltantes;
- Datos de las Keyword Tools: añadir nuevas palabras clave.
La comunicación es clave y con una buena gestión de incidencias, toda la cadena de datos se vuelve coherente para tu explotación por parte de los expertos en SEO y los Data Analysts.
El Data Scientist
El Data Scientist es un científico que enriquecerá los datos con modelos estadísticos, Machine Learing o acercamientos analíticos.
Su principal misión es ayudar a la empresa a transformar los datos proporcionados por los Data Engineers en información valiosa y explotable.
En comparación con los Data Analysts, los Data Scientists necesitan grandes conocimientos de programación para diseñar nuevos algoritmos, así como buenos conocimientos sobre el negocio.
De hecho, deben ser capaces de explicar, justificar y comunicar los resultados a los no científicos.
¿Qué lenguajes deben utilizarse y qué metodología?
Las tecnologías más populares para la Data Science son, por orden: Java, Python, Scala, R y Julia.
Si no puedes decidir qué lenguajes de programación utilizar, puedo darte algunos consejos. En primer lugar, utiliza el lenguaje más popular en tu empresa. Si la mayoría de los desarrolladores están en Python, no hay necesidad de llegar con R, porque el mantenimiento será doble (y su integración puede sufrir). De este modo, demuestras tu capacidad de adaptación.
Te guiarás por las tecnologías sobre las que quieres desplegar tus aplicaciones. Por ejemplo, si tu equipo produce sus Dashboard con Shiny, entonces R se convertirá en su mejor aliado.
R y Python son lenguajes relativamente similares en comparación con C o Scala, por lo que es ideal para tu CV dominar ambos.
En cuanto a la metodología, predomina el método científico y no deja lugar al empirismo. Definir claramente el contexto y los objetivos, luego explicar los diferentes métodos identificados y presentar resultados reproducibles.
La Data Science evoluciona muy rápidamente y la obsolescencia es alta, por lo que es recomendable formarse regularmente.
Sin embargo, es muy posible que no tengas ni el tiempo ni la vocación de querer hacer de la Data Science. En este caso, recomiendo utilizar los servicios de empresas especializadas.
Cual sea la agencia, hay que definir correctamente los entregables y identificar los criterios de éxito para no tener ninguna sorpresa desagradable sobre la explotación de la solución.

El Data Analyst
Los Data Analyst son profesionales de los datos orientados al negocio que pueden interrogar y procesar datos, proporcionar informes, resumir y visualizar datos.
Saben cómo aprovechar las herramientas y métodos existentes para resolver un problema y ayudar a las personas de toda la empresa a entender las consultas específicas mediante informes y gráficos ad hoc.
Se basan en los almacenes de datos de los Data Engineers y en los resultados de los algoritmos de los Data Scientists.
Las competencias son muy variadas: estadística, exploración y visualización de datos.
¿Qué software debe utilizarse?
Data Studio es muy conocido en el campo del SEO, pero en el mundo corporativo, es una historia diferente.
El mercado está dominado por Tableau Software, SAP, Microsoft e IBM.
La adquisición de Looker por parte de Google les permitirá, sin duda, hacerse un hueco entre los líderes en los próximos años.
Por lo tanto, hay que tener mucho cuidado con la elección de la solución de visualización de datos.
Los Data Analysts se adaptan rápidamente a las herramientas, por lo que volvemos a esta famosa cuestión de Make or Buy. Si dispones de un buen presupuesto, las soluciones propietarias te ahorrarán mucho tiempo.
¿Cómo crear Dashboard perfectos?
Hay muchos métodos, pero el método S.M.A.R.T es fácil de recordar.
- Mantener una carta gráfica simple, demasiada información mata la información;
- Las ordenadas y las abscisas deben tener ejes medibles;
- Una gráfica debe centrarse en métricas alcanzables, no tiene sentido controlar métricas que no tendrán influencia en tu negocio. El clima es un excelente ejemplo: es crucial para algunos lugares e inútil para otros;
- Los dashboard deben tener siempre una síntesis para que puedan ser leídos y comprendidos rápidamente. Si se tarda más de tres segundos en entenderlos, se puede (y se debe) mejorar el resultado final. Al principio, los usuarios pueden estar satisfechos con una visión general, pero luego pueden necesitar una visión más granular de los datos haciendo malabares con los filtros;
- El dato más importante es el tiempo: hay que procurar hacer un seguimiento de los datos a lo largo del tiempo, comparando cada día, cada mes, cada año.
Por supuesto, hay que tener en cuenta que si los Data Analysts dominan SQL, pueden recurrir a soluciones open source como Metabase o Superset.
Por último, los analistas con conocimientos de programación optarán por Shiny para R o Dash para Python.
Los proyectos Data SEO
El mundo del Data SEO se ha vuelto seguramente menos oscuro. Como en cualquier proyecto, hay que rodearse de los talentos adecuados para tener éxito en los proyectos de Datos a gran escala o bien estar bien formado en las profesiones mencionadas (Data Engineer, Data Analyst, Data Scientist). Seguramente al escuchar mi charla habrás identificado los puntos débiles o fuertes de tu empresa, así que no dudes en trabajar en tus puntos débiles mediante la contratación, la subcontratación o la formación.
Así que hemos visto las herramientas y los puestos de trabajo. Ahora la clave del éxito está en la ejecución. En esta última parte, revelaré las organizaciones que mejor trabajan el Data SEO con los mejores proyectos de los últimos años.
Organizaciones y equipos
Continuamos nuestro acercamiento al mundo del Data SEO con esta tercera y última parte, en la que analizamos los diferentes tipos de organizaciones y equipos que se pueden crear. Después de las herramientas y las profesiones, ¡esta es la última parte de mi presentación sobre la Data Science y el SEO!
Ahora la clave del éxito está en la ejecución.
Como podemos adivinar, el equipo es el elemento más importante, ya que pueden surgir dificultades en la obtención y el mantenimiento de la consistencia de los datos, pero también en la elección de los modelos de Machine Learning y, finalmente, en el análisis asociado. Como lo vimos, será necesario hacer colaborar perfiles muy diferentes que trabajen juntos para resolver estas diferentes problemáticas.
¡Veamos los “equipos de una persona”!
El Solitario
El equipo “de una persona” es a menudo la realidad en las organizaciones pequeñas y grandes. Conozco a mucha gente muy versátil que maneja tanto la parte SEO como la de Datos con sus propios recursos.
De hecho, existen excelentes cursos de formación que permiten a un entusiasta del SEO aprender la data science, pero también a un data scientist aprender SEO. El único límite es la motivación para aprender cosas nuevas.
Pero como dice Al Pacino:
“O nos unimos como equipo o nos desmoronamos como individuos”.
Incluso si los proyectos se completan rápidamente, dados los medios, siguen siendo menos exitosos.
El solitario puede describirse generalmente como un experto SEO que ha decidido tomar cursos avanzados de programación para ser más técnico en SEO. Dominan al menos un lenguaje de programación (como R o Python) y utilizan algoritmos de Machine Learning. Siguen de cerca las actualizaciones de Google como Rankbrain, BERT y MUM últimamente, donde Google ha estado inyectando más y más Machine Learning en su algoritmo.
En los ejemplos concretos que quiero mencionar, pienso en particular en la automatización de los procesos SEO.
Luego, por supuesto, está el trabajo práctico, como el cálculo del CTR promedio de las 10 primeras posiciones de Google a partir de los datos de Search Console y la detección de las intenciones de búsqueda extrayendo los resultados de los motores de búsqueda.
Ahora, existe el laboratorio SEO de OnCrawl, dónde puedes encontrar muchos procesos SEO que pueden ser automatizados:
- Indexación automática de nuevas URLs;
- Creación de sitemaps de las nuevas URLs para Google;
- Generación de textos con GPT-2;
- Detección de anomalías en todos los informes SEO;
- Predicción del tráfico de cola larga.
Ahora, pasemos de los equipos solitarios a los equipos de 2 personas…
El MVT (Minimum Viable Team)
Supongo que ya hayas oído hablar del MVP (Producto Mínimo Viable). Este formato es muy utilizado en los cuadros de trabajo agiles, en los que el proyecto comienza con un prototipo que evoluciona en iteraciones de una a tres semanas.
El MVT es un equivalente para el equipo que permite minimizar los riesgos y los costes del proyecto. Consiste en crear un equipo con sólo 2 perfiles complementarios durante un periodo de tiempo limitado, a menudo 6 semanas.
Hay mucha literatura sobre el tema, pero cada empresa puede adaptarla a sus propios equipos.

Si entramos en más detalles, el MVT es un equipo de 2 personas: generalmente un experto SEO que entiende los planteamientos SEO y las mecánicas del Machine Learning, trabajando con un desarrollador que el, está probando ideas.
Este enfoque es ideal para construir una solución viable en poco tiempo. Si tomamos una categorización de contenidos, una persona probará un método y aplicará el más eficaz. Sin embargo, el mejor enfoque suele ser probar varios modelos a la vez, quedarse con la categorización que aparezca más veces y acoplarla a la categorización de la imagen para un sitio de comercio electrónico. Esto puede hacerse automáticamente con todas las matrices existentes. El estado del arte permite obtener un 95% de buenos resultados, y luego todo se reduce en la granularidad de los resultados.
Hay un gran sitio que da el estado del arte en cada campo (generación de texto, por ejemplo), pero sobre todo el código fuente. Si aún no lo conoces, aquí tienes el enlace: https://paperswithcode.com/
Hay proyectos en camino, como por ejemplo, un sistema de resumen automático de textos en el que se están probando numerosos enfoques. La idea es parafrasear textos con el modelo BART por ejemplo:
Ahora podemos ver el equipo de trabajo más caro de la historia pero tiene más posibilidades de lograr sus objetivos:
La Task force con la brigada A
Retrocedamos en el tiempo con un equipo de crack de la serie “The A Team” que marcó los años 80. Aquí, cada uno tenía un papel específico y cumplía todas sus misiones con gran éxito. Por supuesto, no hubo episodios sobre SEO 😉 .

Volviendo a las cosas serias, la task force está formado por un experto SEO que trabaja con un data scientist y un desarrollador que supervisarán todo, prepararán los datos y utilizarán los algoritmos de Machine Learning. El experto SEO suele actuar como gestor y/o jefe de proyecto y gestiona la comunicación con la dirección. En los grupos grandes, puede haber funciones específicas para el manager y el jefe de proyecto del equipo.
Veamos unos ejemplos concretos de implementación:
- Creación de un Entreprise Data Warehouse (almacén de datos listo para usar que hace que confluyan con datos Business, popularidad, técnicos y contenido);
- Identificación y tratamiento de las “Páginas Zombies”;
- Detección de nuevas consultas;
- Predicción de tráfico/revenue tras determinadas acciones.
Imagínate crear decenas de proyectos para controlar los cambios de posición en torno a las actualizaciones de Google y los pilares on-site y off-site de las páginas afectadas.
Tener comités de dirección SEO para presentar el clima SEO de los sitios con gráficas de Dataiku y tener datos consolidados automáticamente por las distintas herramientas. De este modo, el grupo de trabajo se concentra en las tareas de mayor valor añadido, ya que muchas tareas están completamente automatizadas.
Next steps
Por supuesto, si no tienes conocimientos en data science, hay cursos de formación básica y avanzada. Los cursos básicos no requieren ningún requisito previo, sino un buen conocimiento de SEO.
Por último, existe una noción de “Data-SEO compliant” para los software, y aquí creo que hay tres principios que hay que seguir de cerca para evitar el uso de herramientas black-box que te proporcionan resultados sin explicar las metodologías y los algoritmos.
- El primer principio es tener acceso a una documentación que explique completamente los algoritmos y parámetros del modelo de Machine Learning.
- El segundo principio es poder reproducir uno mismo en un conjunto de datos los resultados para validar la metodología. En ningún caso se copiará el software porque todas las dificultades residen en el rendimiento, la seguridad, la fiabilidad y la industrialización de los modelos de Machine Learning.
- El último principio es que la herramienta debe haber seguido un enfoque científico comunicando su contexto, sus objetivos, los métodos probados y los resultados finales.
El Data SEO es un enfoque científico del SEO que se basa en el análisis de datos y el uso de la ciencia de datos para tomar decisiones. Sea cual sea tu presupuesto, es posible hacer Data Science y la tendencia es hacer cada vez más accesibles los conceptos que utilizan los Data Scientists.
Ahora te toca apropiarte de estos proyectos Data SEO con las herramientas, los perfiles de trabajo y los equipos adecuados, como hemos visto.


