
El monitoreo en LLMs se ha convertido en la nueva obsesión. Todo el mundo quiere saber “qué dice la IA” de su marca, y el resultado suele ser el mismo: presentaciones llenas de pantallazos que funcionan más como souvenirs digitales que como datos. El pantallazo de GPT mencionándote, el recorte de Perplexity con tu logo perdido en un listado, el AI Overview que un día te incluyó y al siguiente te olvidó. Sí, es divertido, pero ¿sirve para algo? No.
Porque eso no es monitoreo, es turismo digital. Una colección de anécdotas que calma el ego pero no cambia el negocio. La verdadera pregunta no es si un modelo te nombró una vez, sino cuál es tu nivel real de visibilidad en la IA: ¿apareces de manera consistente?, ¿estás descrito con precisión?, ¿te citan con enlace o dependes de la autoridad de otros?
Ese es el nuevo terreno de juego: lo que antes llamábamos share of search se está transformando en share of answers. Y en este escenario, coleccionar pantallazos aislados es como presumir que “mi primo me buscó en Google y sí salgo”. Reconforta, pero no construye estrategia.
Monitorear resultados en LLMs exige un método, no improvisación. Se trata de un flujo en seis pasos que define la condición de posibilidad, el mapa del conflicto, los territorios que importan, las preguntas que resisten comparación, los entornos donde observar y, finalmente, el tablero que convierte datos en decisiones:
Website → Competitors → Topics → Prompts → Monitoring → Launch.
El flujo de monitoreo en seis pasos
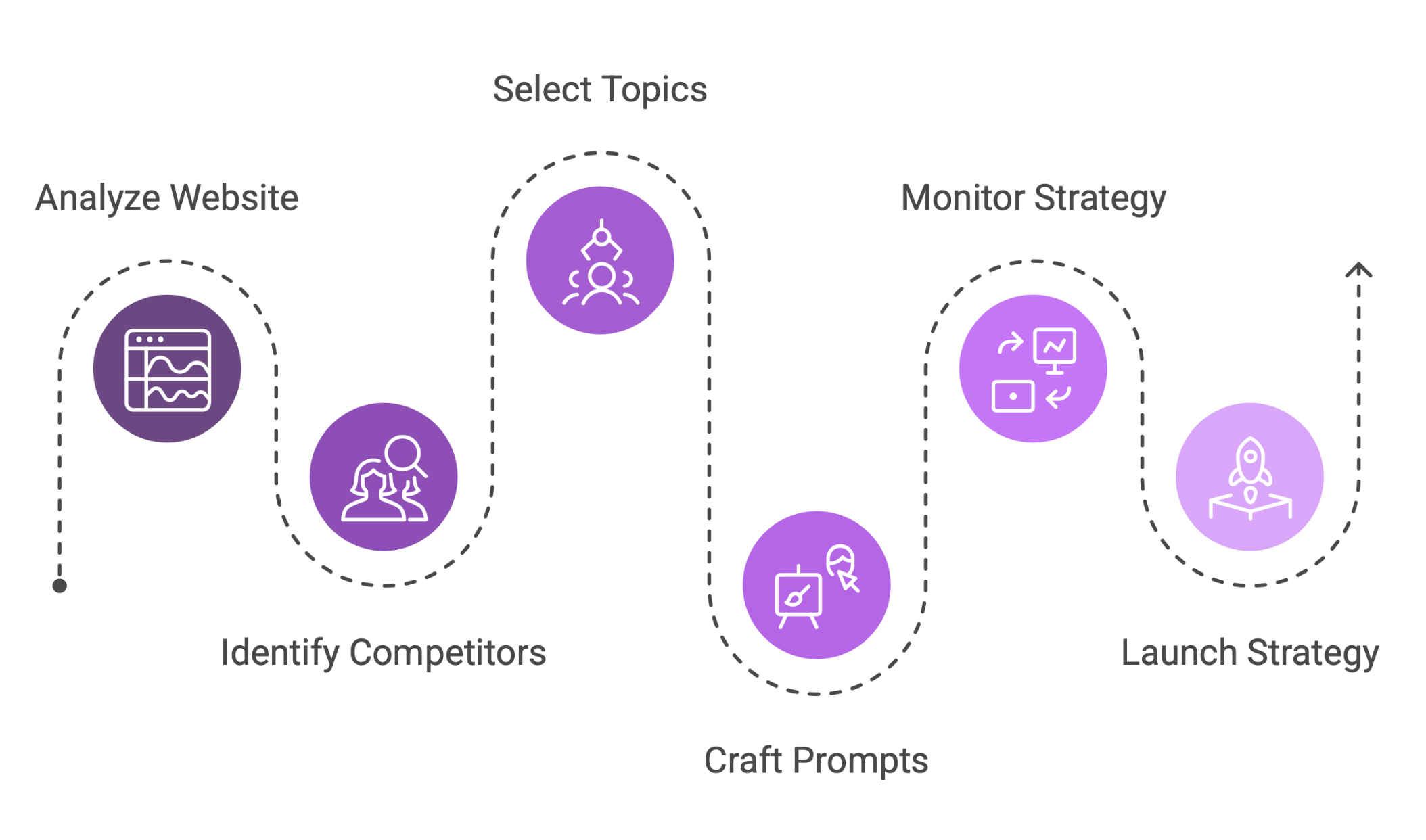
Solo así el monitoreo deja de ser folklore y se convierte en estrategia.
El monitoreo en LLMs no empieza con un prompt ingenioso ni con un tablero bonito en Data Studio. Empieza con algo más incómodo: ¿tu sitio web define tu entidad con la suficiente claridad para que una máquina pueda reconocerla, describirte sin errores y citarte como fuente confiable?
Porque la IA no inventa. Si tu web es ambigua, dispersa o invisible para los bots, lo que aparecerá en GPT, Claude o en un AI Overview no será tu mensaje, sino un Frankenstein armado con retazos de terceros.
Las 4 preguntas que todo sitio debe responder
Aquí entra la metodología de las 4 preguntas. Lo que para un usuario es confianza y claridad, para una IA es materia prima que evita improvisar:
- ¿Cómo me vas a ayudar? → Define con precisión tus servicios o productos. No con slogans vacíos, sino con utilidad concreta.
- ¿Qué tengo que hacer? → Dale instrucciones claras al usuario (y a la máquina): cómo contactarte, contratarte o iniciar un proceso.
- ¿Quién eres? → No basta con “somos expertos”. La IA necesita saber quién está detrás de la marca. Si no, te confundirá con un homónimo.
- ¿Por qué tú? → Expón diferenciales y deja claro lo que no haces, para evitar que la máquina te coloque en contextos ajenos.
Si tu web no responde estas cuatro preguntas en una sola página visible y accesible, el modelo llenará los huecos con suposiciones.
El Mínimo SEO Viable
Los LLMs no leen la web como un usuario de 2025. La leen como un navegador torpe de 1996: no ejecutan bien Javascript, no esperan a que carguen widgets dinámicos, no interpretan lo que depende de eventos de cliente.
Por eso el Mínimo SEO Viable (MSV) no es opcional: es la condición de posibilidad. URLs limpias, HTML renderizado desde servidor, metadatos claros, datos estructurados y canonicales son el alfabeto con el que le hablas a la IA. Sin MSV, tu sitio es un fantasma.
El problema del Javascript
Aquí tropiezan muchas webs modernas:
- Renderizado incompleto: si el contenido depende de un evento JS, los bots de IA no lo verán.
- Bloques invisibles: sliders, pestañas o secciones que al usuario le parecen normales, pero para la IA son un vacío.
- Narrativa rota: el modelo encuentra un esqueleto sin texto y lo completa con lo que saca de otras fuentes, inventando atributos o mezclando datos viejos.
El resultado no es “no te encuentran”. Lo demostré en un caso de estudio: la IA simplemente no pudo leer los contenidos de las páginas.
SEO editorial: crear lugares donde ser citado
La IA no construye arquitecturas editoriales donde no existen. Si quieres que tu marca sea citada en un territorio concreto (como “cirugía cardiaca en Monterrey” o “financiamiento para pymes en Colombia”), debes darle un mapa claro. Eso significa estructurar tu sitio con jerarquía SXO: páginas madre que sostengan el tema principal, hijas que lo desarrollen en profundidad y nietas que lo ejemplifiquen con casos o aplicaciones concretas.
Esta arquitectura no es un lujo ni un “nice to have”: es lo que convierte tu web en una fuente natural de citación. Sin ella, la IA no tiene dónde apoyarse y termina rellenando huecos con información de terceros. En ese punto ya no mide tu narrativa, mide la de los demás.
La diferencia es sencilla: una estructura editorial sólida orienta al modelo hacia tu versión de los hechos; sin ella, la máquina improvisa. Y cuando la IA improvisa, rara vez lo hace a tu favor.
SEO de popularidad: la validación externa
Un sitio impecable no sirve de nada si vive en el vacío. Los LLMs no se limitan a leer lo que está dentro de tu dominio: buscan señales externas que validen tu existencia. En su lógica, una marca aislada es apenas un dato débil; una marca mencionada, citada y enlazada en contextos relevantes es una entidad sólida.
Aquí entra el SEO de popularidad. No se trata de acumular backlinks como si estuviéramos en 2005, sino de construir huellas verificables que confirmen a la IA que eres alguien de quien vale la pena hablar. Esas huellas pueden ser: menciones en medios especializados, anchors de marca en directorios serios, citaciones en papers académicos, entrevistas en prensa o participaciones en foros sectoriales.
Lo importante no es solo la cantidad, sino la coherencia del ecosistema: si tus menciones refuerzan lo mismo que dices en tu web, el modelo aprende una narrativa consistente. Si cada señal externa dice algo distinto, la IA hereda tu contradicción.
El matiz es crítico: los LLMs no te dan autoridad por decreto, te la prestan en función de lo que otros ya confirmaron de ti. Si tu marca no circula fuera de tu propio dominio, lo más probable es que no seas citado… o peor aún, que lo poco que se diga de ti se mezcle con los atributos de otro.
En pocas palabras: tu web define quién eres, pero es la popularidad externa la que decide si la IA te escucha.
Esto no es GEO, ni AEO, ni la última etiqueta de moda como LLMO. Es simplemente hacer SEO como se debe: claridad de entidad, solidez técnica, arquitectura editorial y validación externa. La diferencia es que ahora el juez no es un motor de búsqueda clásico, sino un modelo de lenguaje que decide si existes… o si eres solo ruido de fondo.
2. Competitors: el mapa del conflicto
El segundo paso para monitorear resultados en LLMs no es preguntarle a la IA si existes, sino descubrir contra quién compites de verdad en su universo. Porque la competencia en los modelos no se parece al ranking azul de Google: aquí el problema no es “quién está delante de ti”, sino a quién el modelo coloca en tu lugar cuando tú no apareces.
Los tres anillos de competencia
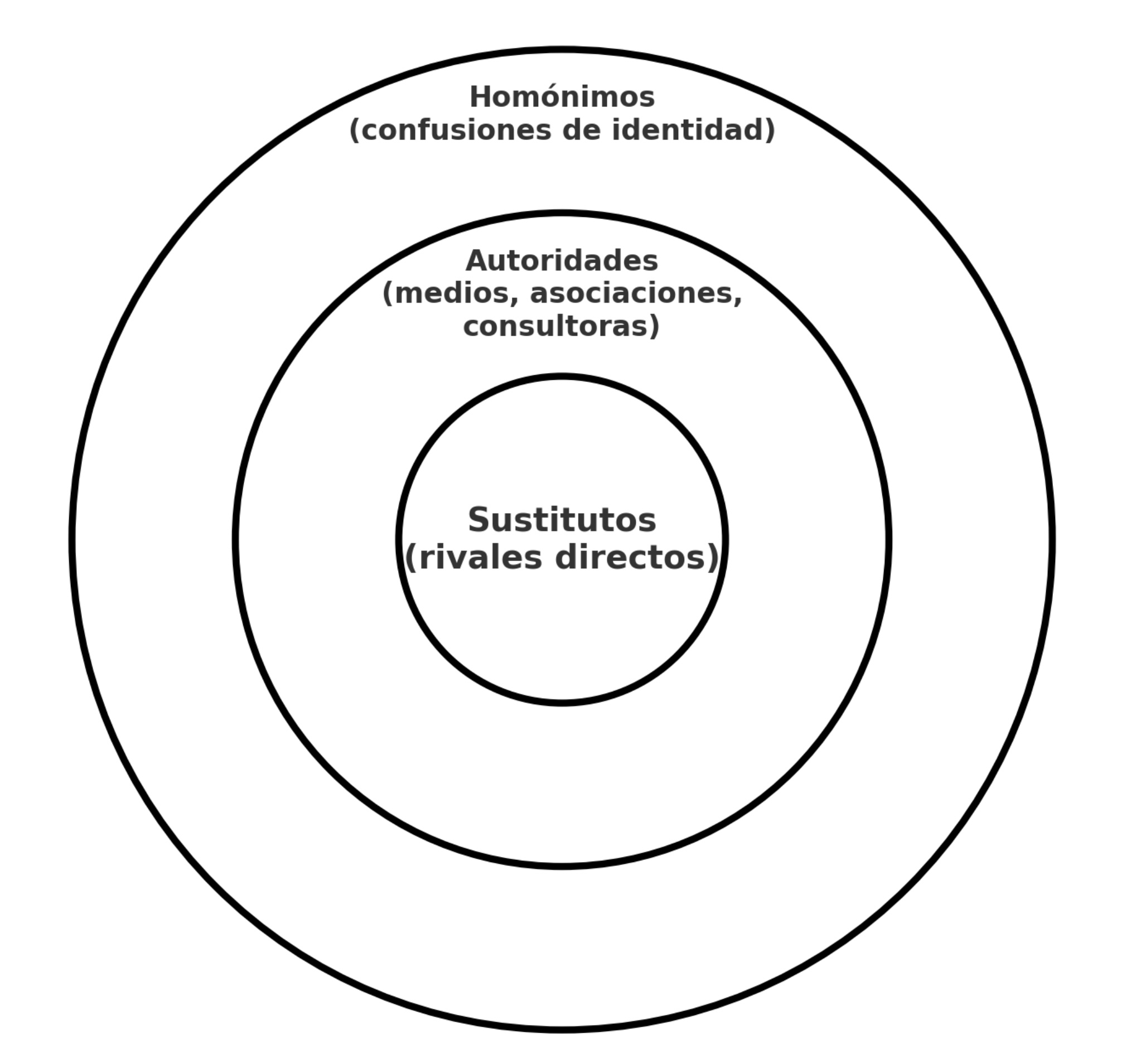
Para no perderme en ruido, uso un mapa de tres anillos concéntricos.
- Sustitutos (anillo interno): son tus rivales directos, los que ocupan tu espacio cuando el modelo debe recomendar una opción. Ejemplo: un hospital privado que no aparece en “mejores hospitales de Monterrey” es reemplazado por otro de la misma categoría.
- Autoridades (anillo medio): aquí viven medios especializados, asociaciones sectoriales y consultoras. No te compiten por negocio directo, pero su narrativa pesa más que la tuya, y los modelos prefieren citarlos antes que a ti.
- Homónimos (anillo externo): marcas con nombre idéntico o parecido que confunden la identidad. Es el terreno más incómodo: cuando una fintech termina descrita como ONG ambientalista, simplemente porque comparten siglas.
Este Mapa de competencia en tres anillos te muestra que no siempre luchas contra el vecino de la SERP: a veces el enemigo es un directorio global, un medio con 50 menciones mal estructuradas o un homónimo que contamina tu marca.
Distorsiones reales
- He visto empresas obsesionadas con rivales de su mismo tamaño, mientras que el modelo las ignoraba y citaba a Mercadolibre como fuente de referencia.
- He visto empresas confundidas con fundaciones ambientales por compartir acrónimo.
- He visto marcas desplazadas en AI Overviews no por un competidor real, sino por un listado curado tipo “Las 10 mejores empresas según X portal”.
Son recordatorios de que tu “enemigo” en LLMs puede ser muy distinto al que imaginas.
Trampas frecuentes
- Tomar solo la SERP como referencia: lo que ves en Google no siempre es lo que el modelo decide.
- Ignorar homónimos: si no documentas la confusión posible, la máquina lo hará por ti.
- Competir contra todo a la vez: sin priorizar anillos, tu estrategia se diluye.
Por qué importa este mapa
Un mapa mal definido convierte cualquier monitoreo en ruido. Si no sabes con quién te comparan, a quién citan por encima de ti y con quién te confunden, no puedes interpretar por qué apareces o desapareces en un resultado.
Los LLMs no improvisan en el vacío: llenan huecos con sustitutos, autoridades y homónimos. Si no identificas bien esos tres anillos, tu estrategia será siempre reactiva, nunca proactiva.
3. Topics: territorios en lugar de palabras sueltas
El monitoreo en LLMs no se gana preguntándole a la IA por el nombre de tu empresa. Eso solo confirma que existes en tu propia burbuja. Los modelos no ordenan información por keywords sueltas, sino por territorios temáticos: escenarios donde confluyen problemas reales, categorías de servicio y decisiones de clientes.
Un territorio no es una palabra clave: es un marco de decisión.
- Para un hospital privado: cirugía cardiaca en Monterrey.
- Para un despacho legal: abogados para startups en Ciudad de México.
- Para una fintech: plataformas de crédito para pymes en Colombia.
Es en esos territorios donde los modelos deciden a quién nombrar, a quién citar y a quién borrar del mapa. Si no tienes presencia clara en ellos, no existes.
Cómo mantener la comparabilidad
El error clásico es tratar sinónimos como equivalentes. Creer que hospital privado, clínica médica y centro de salud son lo mismo. No lo son.
- Hospital privado remite a infraestructura grande y reputación institucional.
- Clínica médica suena a espacio pequeño o especializado.
- Centro de salud arrastra connotaciones públicas o comunitarias.
Meter todo en el mismo saco genera espejismos: un día apareces, al siguiente no, y nunca entiendes por qué.
La solución es separar variantes:
- Léxicas: despacho vs firma de abogados; clínica vs hospital.
- Funcionales: préstamos rápidos vs financiamiento empresarial.
- Dialectales: abogados corporativos en México vs bufete jurídico en España.
Cambiar una palabra no es un matiz: es abrir un nuevo territorio. Solo así puedes comparar tendencias sin engañarte.
Ejemplos aplicados
- Un despacho de abogados debe rastrear su presencia en firma legal para startups, abogados corporativos en CDMX y consultoría legal para fusiones.
- Un hospital privado necesita monitorear hospital privado Monterrey, clínica de cardiología y servicios de urgencias 24 horas.
- Una fintech debe medir plataformas de crédito para pymes, financiamiento digital empresas y crédito rápido negocios México.
Cada territorio genera un set de prompts. Y cada prompt prueba si la IA reconoce, describe y cita correctamente a la empresa.
Trampas frecuentes
- Quedarse en lo genérico: medir empresa de logística cuando lo que importa es logística internacional de importaciones México–EEUU.
- Ignorar dialectos: usar el español de España para sacar conclusiones de clientes en México.
- Confundir intenciones: tratar financiamiento de empresas como igual a préstamos rápidos para pymes. La IA no lo ve igual, y tú tampoco deberías.
Los territorios son el terreno real de competencia en los LLMs. No basta con preguntarle al modelo por tu nombre: hay que ver si existes en los marcos de decisión donde los usuarios plantean sus problemas. Sin esta capa, cualquier monitoreo es anecdótico.
4. Prompts: preguntas estables o espejismos
Creer que el monitoreo empieza con un “¿qué opinas de mi empresa?” es autoengaño. Eso no mide nada: solo tu capacidad de inducir al modelo. Un sistema serio necesita prompts de control, diseñados para resistir comparaciones en el tiempo, en distintos modelos y en distintos países. Sin consistencia, lo único que mides es tu ansiedad.
Dos familias de prompts
- Brand-naïve: no mencionan el nombre de la empresa. Simulan la búsqueda de un usuario que aún no te conoce.
Ejemplos:
“Mejores clínicas de cardiología en Monterrey”
“Firmas legales para startups en México”
“Plataformas de crédito para pymes en Colombia” Aquí interesa saber si apareces, si la descripción es correcta y si tu sitio es citado con enlace. - Brand-aware: incluyen el nombre de la empresa. Evalúan si el modelo entiende quién eres, te diferencia de homónimos y actualiza bien la información.
Ejemplos:
“Hospital Zamora en Monterrey es privado o público”
“Qué servicios ofrece CréditoFácil en Colombia” Aquí la clave está en la desambiguación y la consistencia de marca.
Cuatro intenciones que hay que cubrir
Cada territorio necesita prompts que reflejen todo el recorrido de decisión del usuario:
- Informativa: “Qué es un hospital privado y qué lo diferencia de una clínica”.
- Comparativa: “Mejores firmas legales para fusiones en México”.
- Selección de proveedor: “Mejores hospitales privados en Monterrey para cirugía cardiaca”.
- Acción guiada: “Cómo obtener financiamiento digital para pymes en Colombia”.
Si no cubres estas cuatro, solo ves un fragmento del mapa. Y lo que no se cubre, no se mide.
Versionado disciplinado
Cada prompt necesita registro, con un estándar de nomenclatura:
territorio.intención.país.idioma.v1
Cambias una palabra, creas una versión nueva. No es obsesión: es método. Sin versionado claro, lo que comparas son espejismos.
Trampas frecuentes
- Prompts con olor a marca: “¿es bueno el Hospital Zamora?”. Eso no es monitoreo, es inducción disfrazada.
- Sesiones contaminadas: corriges al modelo y guardas la última respuesta como si fuera la inicial. Estás midiendo tu conversación, no la capacidad del sistema.
- Dialectos mezclados: preguntar en español para España y usarlo como referencia para México. Distorsión garantizada.
Los prompts no son frases sueltas para jugar con un chatbot. Son el instrumento que define si tu monitoreo es comparable, replicable y accionable.
La pregunta no es “qué dice la IA de mí”, sino:
- ¿aparezco en los territorios relevantes?,
- ¿la descripción es correcta?,
- ¿me citan con enlace?
Si no respondes a eso con prompts de control bien diseñados, lo que tienes no es monitoreo: es folklore.
5. Monitoring: entornos y frecuencia
Hasta aquí ya tienes claro qué preguntar y cómo formularlo. Ahora llega el punto más delicado: decidir dónde observar. Y conviene subrayarlo: no todo vale lo mismo. No pesa igual una improvisación narrativa en ChatGPT que una citación con enlace en Perplexity, ni mucho menos que la vitrina pública de Google con sus AI Overviews.
Los tres entornos que importan
- Conversacionales (ChatGPT, Claude, Gemini)
Aquí los modelos improvisan narrativas. Sirve para detectar si tu marca o entidad aparece como actor relevante en el sector, aunque no haya enlaces. Lo valioso es la exactitud: ¿describe bien tus servicios?, ¿te ubica en la ciudad correcta?, ¿te atribuye logros que nunca fueron tuyos? - Motores con búsqueda (Perplexity, Sonar)
No solo responden: también muestran de dónde sacan la información. Esa diferencia es oro. Aquí puedes medir si eres fuente citada con enlace (lo deseable) o si apenas eres objeto mencionado (visible pero sin atribución). Una fintech puede aparecer en “plataformas de crédito para pymes”, pero si el enlace apunta siempre a un medio que habló de ella —y nunca a su sitio—, su autoridad es prestada. - Búsqueda con IA pública (AI Overviews de Google)
Es la vitrina más expuesta. Aquí se decide si un despacho legal en CDMX aparece en la tarjeta principal de “mejores firmas para startups” o si es invisible. Y aquí no sirve presumir “salí una vez”: lo único que importa es la consistencia.
Evitar la sopa de métricas
La mayoría de los sistemas de monitoreo se hunden en el mismo error:
- Mezclan resultados de entornos distintos como si fueran comparables.
- Promedian señales incompatibles hasta inventar números que no significan nada.
- Y terminan celebrando anécdotas aisladas como si fueran tendencia.
Un tablero que no separa canchas es como un mapa sin leyenda: da la ilusión de orientación, pero en realidad solo te pierde.
Curva de espejismos vs consistencia
Aquí entra la diferencia crucial: lo que se celebra en presentaciones (el pantallazo feliz) y lo que de verdad cuenta en estrategia (la serie que importa).
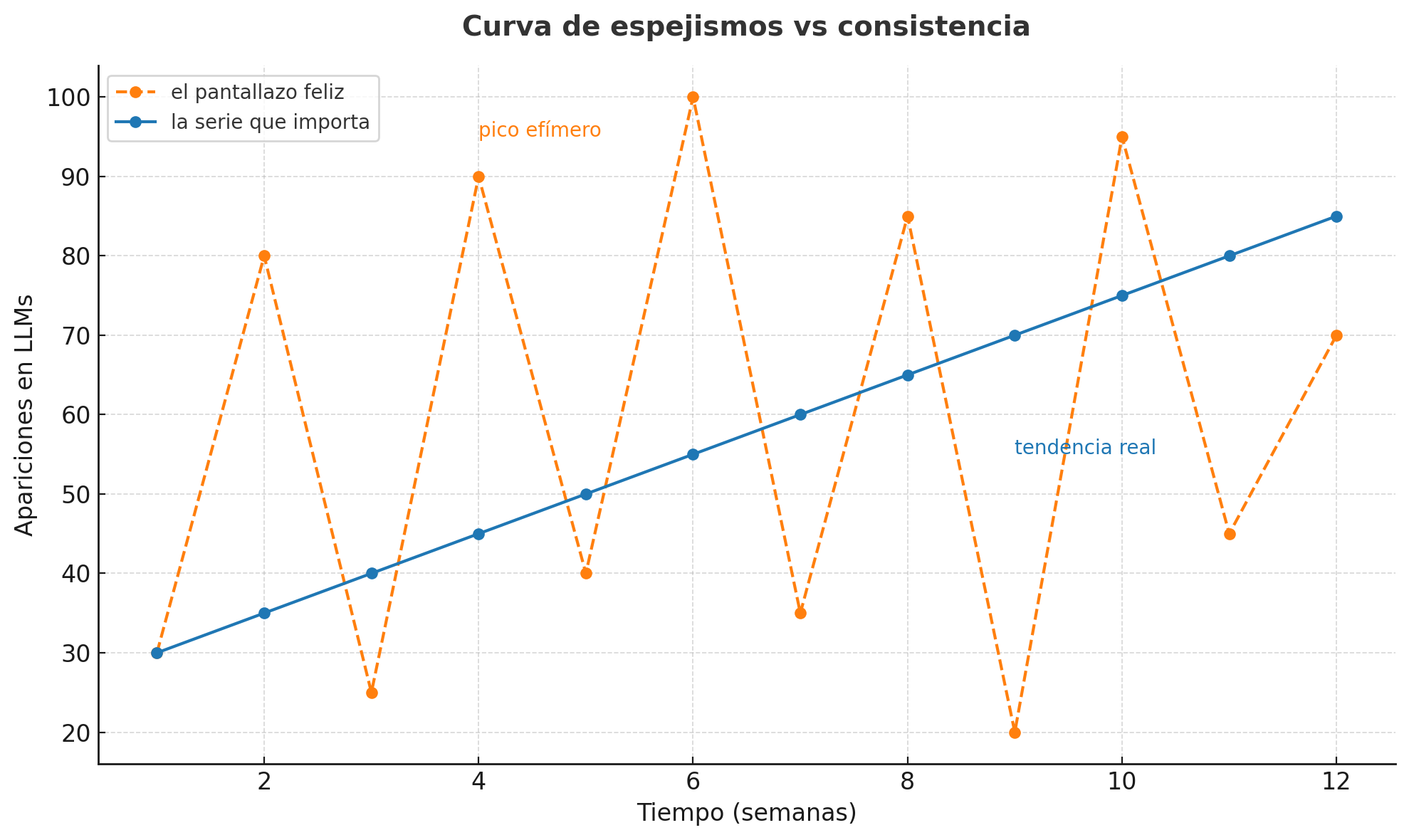
En naranja, los picos efímeros: “mira, salí en AI Overview esta semana”.
En azul, la tendencia real: la serie temporal que obliga a decidir.
La gráfica lo muestra sin anestesia: la volatilidad entretiene, pero la consistencia manda.
Trampas frecuentes
- Celebrar un golpe de suerte: “hoy sí aparezco en AI Overview”. ¿Y mañana? Lo que cuenta no es la anécdota, sino la serie.
- Sopa de métricas: “65% de presencia en LLMs”. Un número hueco que mezcla narrativas, citaciones y vitrinas públicas.
- Geolocalización mal hecha: medir desde España y usarlo como referencia para clientes en México. Distorsión asegurada.
Monitorear no es coleccionar souvenirs digitales. Es medir con método, separar entornos, mantener cadencias claras y repetir pruebas ante ruido. Todo lo demás es folklore.
6. Launch: de la medición al tablero vivo
Llegados aquí ya no hablamos de pantallazos ni de métricas dispersas. Hablamos de convertir observaciones en decisiones. El Launch no es “seguir midiendo”; es darle dientes al sistema: fijar umbrales, comparar contra una línea base y decidir si refuerzas, corriges o mantienes.
De la foto a la estrategia
Un hospital privado aparece en 25% de AI Overviews sobre “cirugía cardiaca en Monterrey”.
Un despacho legal logra 90% de exactitud en prompts brand-aware, pero arrastra confusión con homónimos en 10%.
Una fintech aparece en 60% de respuestas de Perplexity, pero con 0% de enlaces directos a su dominio.
Eso no es un diagnóstico para archivar en un PDF: es una alerta.
- El hospital debe reforzar citabilidad en medios médicos.
- El despacho tiene que desambiguar su marca.
- La fintech necesita trabajar menciones con enlace propio.
El Launch convierte observaciones en movimiento.
Los cinco KPIs que importan
Un tablero serio no se mide con veinte métricas decorativas, sino con cinco indicadores que resisten auditoría:
- Presencia → porcentaje de respuestas donde apareces en la parte principal.
- Exactitud → porcentaje de hechos críticos que están descritos sin errores.
- Atribución → porcentaje de menciones que enlazan a tu dominio oficial.
- Alucinaciones → frecuencia y gravedad de errores inventados.
- Tiempo a corrección → días que pasan desde detectar un error hasta verlo desaparecer.
Cinco números. Sin adjetivos. O cruzaste el umbral o no.
Juega con esa herramienta y verás la interpretación adaptarse 😉
KPIs del Launch en LLMs
Interpretación
Medir vs lanzar
- Medir es recolectar datos y guardarlos.
- Lanzar es poner umbrales, institucionalizar frecuencias y aceptar la consecuencia.
Ejemplo: “menos de 40% de presencia en AI Overviews = zona roja”. No hay debate. El tablero se vuelve juez.
Trampas finales
- Causalidad mágica: atribuir toda mejora a la última acción visible, olvidando meses de trabajo acumulado.
- Confundir Launch con cierre: lanzar no es terminar, es abrir la etapa donde los datos gobiernan.
- Umbrales de goma: mover la meta para nunca estar en rojo. Eso mata la utilidad del tablero.
Citabilidad o silencio
Al final, el Launch revela lo esencial: o eres citable, o eres invisible. Puedes gastar millones en campañas, pero si los modelos no reconocen tu entidad, no describen bien tus servicios y no te citan con enlace, tu marca no existe en la conversación que más importa.
Los seis pasos (Website, Competitors, Topics, Prompts, Monitoring y Launch) no son un adorno metodológico: son la única manera de evitar espejismos y convertir el monitoreo en una estrategia con dientes.
El punto ciego
Monitorear resultados en LLMs no es moda ni etiqueta de consultoría futurista. No es GEO, ni AEO, ni LLMO. Es simplemente SEO bien hecho, aplicado al nuevo terreno de juego donde los modelos deciden a quién reconocer y a quién borrar del mapa.
Los acrónimos se desgastan, pero la lógica no cambia: si tu sitio no está claro, si nadie te respalda, si no tienes estructura editorial, la IA improvisará. Y cuando improvisa, rara vez te favorece.
Por eso esta guía no habla de pantallazos felices ni de souvenirs digitales: habla de construir un sistema riguroso que mida visibilidad real en IA. Porque aquí no se trata de aparecer una vez; se trata de sostener presencia, exactitud y citabilidad en el tiempo.
La verdad incómoda es que los LLMs solo citan lo que es sólido, verificable y repetible. Lo demás es ruido. Y si tu marca se queda en el ruido, no estás perdiendo métricas: estás perdiendo existencia.


