
La llegada de Google Lens es aún desconocida para muchos. Sin embargo, su aparición se remonta a 2018. Implementada desde el 04 de octubre de 2017 en Estados Unidos, esta nueva aplicación está demostrando ser una verdadera revolución en la forma de utilizar el motor de búsqueda. Tras los anuncios realizados en Search On el 29 de septiembre de 2022, las imágenes vuelven a estar presentes con Google Lens y la búsqueda multimodal. Escanear el mundo, hacer preguntas de la manera que queramos y donde queramos, se convertirá probablemente en nuestra nueva forma de buscar. ¿Cómo funciona Google Lens? ¿Cómo ha aprendido el motor de búsqueda a “ver” las imágenes? ¿Y qué impacto tendrá esta aplicación en nuestra vida cotidiana? Aquí tienes algunas explicaciones.
¿Qué es Google Lens?
Google Lens es una aplicación, creada originalmente para smartphones y tabletas. Con una simple fotografía de un objeto, lugar, animal o planta, el buscador te da acceso a toda una serie de conocimientos a partir de sus numerosas aplicaciones verticales: Google Maps, Google Image, Knowledge Graph, Google Translate y Google Shopping principalmente.
No existe un Google, sino muchos.
El motor de búsqueda californiano no es sólo un motor de búsqueda de páginas web, sino también de imágenes, noticias, artículos científicos, etc. La lista no es exhaustiva, pero es importante señalar que cada motor vertical requiere la intervención de diferentes algoritmos en segundo plano. Google es un conjunto de servicios, a veces similares y a la vez muy diferentes. Por eso no hay un Google, sino muchos Google… incluyendo Google Lens.
Resultados muy diferentes de los diez enlaces azules
A partir de una simple imagen, Google Lens te proporciona información de los distintos componentes del buscador: Google Images, Google Maps, Google Shopping, Google Books, pero no sólo. Un mecanismo basado en varios algoritmos utilizados en conjunto, Lens realiza operaciones basadas en un proceso de aprendizaje específico, el de “ver” imágenes como los humanos. Y esto es para darnos los mejores resultados posibles.
El aprendizaje, la clasificación y los resultados que muestra Google Lens se basan en métodos con potentes funcionalidades de aprendizaje automático. Entre ellos se encuentran el machine learning (ML) y el Deep Learning (DL), una técnica transversal a los dominios de la IA (Inteligencia Artificial).
La búsqueda de imágenes existe desde hace mucho tiempo. Antes descuidada, ahora vuelve al primer plano con la multibúsqueda. Además de una industrialización masiva del aprendizaje de imágenes, la empresa Alphabet combina el reconocimiento visual, con texto, la búsqueda por voz y local.
Con la búsqueda multimodal, los resultados de Google Lens son actualmente muy diferentes de la tradicional SERP con 10 enlaces azules. De hecho, el gigante californiano ya está mirando al futuro: con Google Lens, el mobile first está dando paso a la AI first, con el objetivo de “hacer la búsqueda más natural y más intuitiva”, según Sundar Pichaï (fuente: Search On 2022).
Google Lens: “La búsqueda, pero diferente”
Creado originalmente para teléfonos y tabletas Android, el uso de Google Lens se extiende ahora a cualquier dispositivo (PC/Mac y iPhone, en particular). Utilizando la cámara de tu smartphone, Lens no sólo detecta un objeto (imagen, texto o algo), un animal o una planta delante del objetivo de la cámara, sino que trata de entenderlo, como lo haría un ser humano.
Basándose en sus interpretaciones, Google Lens muestra resultados y te ofrece la posibilidad de ir más allá mediante la numerisación, la traducción, la búsqueda local o incluso hacer compras (a través de Google Shopping, por ejemplo).
Por lo tanto, cuando Lens se está ejecutando, actualmente te da la posibilidad de :
- Traduce el texto que se encuentra en la imagen;
- Escucha el texto, en todos los idiomas disponibles en Google Translate;
- Busca información a través de Google Search;
- Realiza cálculos matemáticos y resuelve ecuaciones;
- Compra el objeto de la imagen;
- Descubre lugares (pronto disponible en realidad inmersiva y aumentada con “Search with Live View”);
- Lee y analiza un menú ofreciéndote imágenes de los platos de la carta del restaurante.
Nota: todas estas aplicaciones están actualmente disponibles en móvil, excepto la visualización inmersiva y la RA (realidad aumentada) en Google Maps. No se ha dado ninguna fecha oficial tras los anuncios del 29 de septiembre de 2022, excepto para la “Search with Live View”. Está prevista en seis ciudades en los “próximos meses”: Los Ángeles, San Francisco, Nueva York, Londres, Tokio y París.
¿La imagen será una nueva tipología de búsqueda para el futuro?
Lens es una aplicación basada en el uso de numerosos algoritmos. Trabajan juntos para que Google actúe. Así es como la IA y el Deep Learning alimentan los productos de Google.
El objetivo de la aplicación Lens es darte información o ayudarte a definir mejor un contexto sobre tu entorno y todos los objetos de ese entorno fotografiado. De momento, Google Lens sigue siendo una forma de ayudar a más personas a entender mejor el mundo que les rodea. La búsqueda de información ya no se limita a las palabras clave en la barra de búsqueda. Ahora también se hace a través de imágenes.
Google Lens, el futuro de la búsqueda sin palabras clave
Con Google Lens, la forma de buscar está cambiando. No es necesario formular una consulta textual para obtener resultados. Si no sabes cómo expresar lo que ves, si eres analfabeto, ciego o disléxico, Lens puede ayudarte mucho en tu vida diaria.
Mientras investigué para este tema, me llamó la atención un vídeo en el que se explicaba cómo funciona Google Lens y cómo se utiliza. Este es un vídeo de una madre india que no sabe leer ni escribir, pero gracias a la aplicación instalada en su teléfono móvil, entiende mejor el mundo que le rodea.
Es aquí que Google Lens toma, en mi opinión, todo sentido. Permitir a cada uno acceder al arte, a la historia o simplemente para comprender mejor el entorno cotidiano que nos rodea. El uso de Google Lens junto con Google Search o Google Maps ofrece a todos la oportunidad de acceder a nuevos conocimientos.
Busca al instante lo que ves
Algunas consultas son difíciles de describir, de expresar y, por tanto, de encontrar. Ver, es también entender, por eso la búsqueda de Google se reinventa con la aplicación Google Lens: la posibilidad de buscar instantáneamente lo que ves, sin tener que formularlo o escribirlo. El texto que habitualmente se utiliza para formular una búsqueda queda así destronado por la búsqueda visual.
Multisearch, Near me et Scene exploration, las búsquedas del futuro
Utilizado más de 8.000 millones de veces al mes, es decir, casi tres veces más que en 2021 (fuente: conferencia Google I/O del 11 de mayo de 2022), Google Lens ya funciona con el multisearch (búsqueda multiple) en Estados Unidos. La multibúsqueda de Google te ofrece la posibilidad de utilizar tu teléfono para realizar una búsqueda de imágenes, impulsada por Google Lens, y luego añadir una consulta adicional de texto (o de voz).
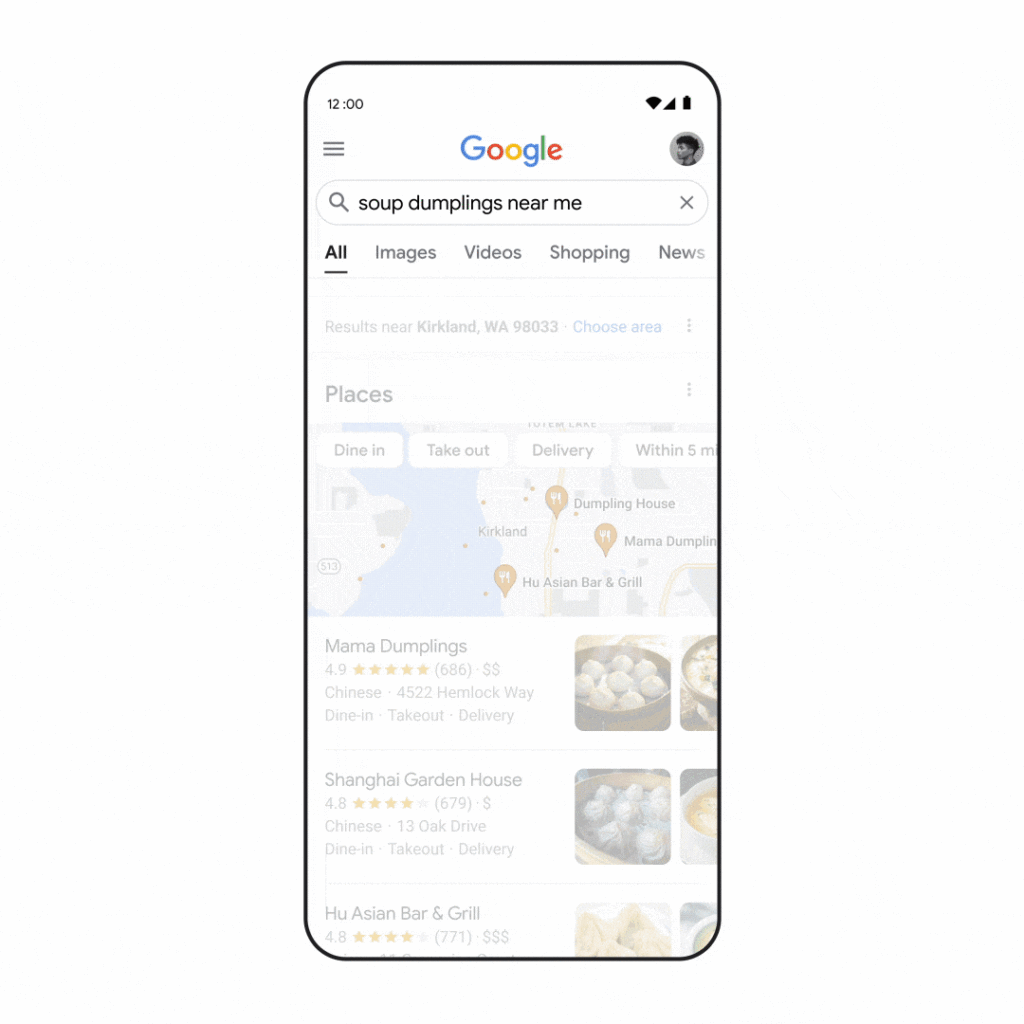
La integración de multisearch near me (“búsqueda múltiple cerca de mi”) está prevista para 2022 (en EEUU). Permitirá obtener información local de una foto directamente desde la aplicación.
Con esta nueva funcionalidad, además de identificar un plato servido en un restaurante, Google Lens te mostrará el restaurante más cercano a tu ubicación geográfica. Esto demuestra la importancia del SEO local, ya en marcha y aún por llegar.
Aunque parezca sencillo, esta futura función se basa en la búsqueda multimodal. Así es como los algoritmos buscan un plato cerca de ti:
- Google identifica las especificidades y sutilezas visuales contenidas en la imagen.
- Tu búsqueda visual está asociada a tu intención (la de comer el plato en un restaurante local).
- Se analizan millones de imágenes y reseñas publicadas en páginas web (por ejemplo, las “Google local guides”).
- Google Lens responde a tu intención y te ofrece resultados sobre restaurantes cercanos.
Otra función que llega a Google Lens: Scene Exploration. Otra forma de búsqueda multimodal que te permite encontrar toda la información, ya no sobre un objeto de una foto, sino sobre toda una escena. Podrás hacer preguntas (intención de búsqueda) y obtener respuestas sobre uno o varios objetos en un contexto más amplio… Ya estamos muy lejos de las palabras clave y los diez enlaces azules. Google Lens ya se perfila como una especie de “super Ctrl + F” del futuro.
¿Cómo Google Lens utiliza las imágenes para responderte?
¿Cómo consigue Google Lens, a partir de una simple imagen o captura de pantalla, proporcionarte toda esta información? Google Lens utiliza Deep Learning (DL) para el reconocimiento de imágenes. Subcategoría del Machine Learning (ML) y transversal de la Inteligencia Artificial (IA), el DL se refiere a un conjunto de técnicas y tecnologías de aprendizaje automático basadas en redes neuronales artificiales. Se denomina específicamente neuronas convolucionales (CNN).
Lens ofrece actualmente identificar plantas, animales y otros objetos a partir de una simple foto. Con la inteligencia artificial (IA), la información obtenida a partir de imágenes, vídeos, audio o texto será capaz de crear conexiones entre temas y conceptos para aportar siempre más pertinencia a la calidad de los resultados.
Redes neuronales, memorización y extracción de características
Al igual que el cerebro humano, la red neuronal reconoce un concepto mostrándole muchos ejemplos variados. Este aprendizaje se consigue mediante la adquisición y la memorización de datos, la extracción y los ajustes de características. Veremos ejemplos un poco más tarde.
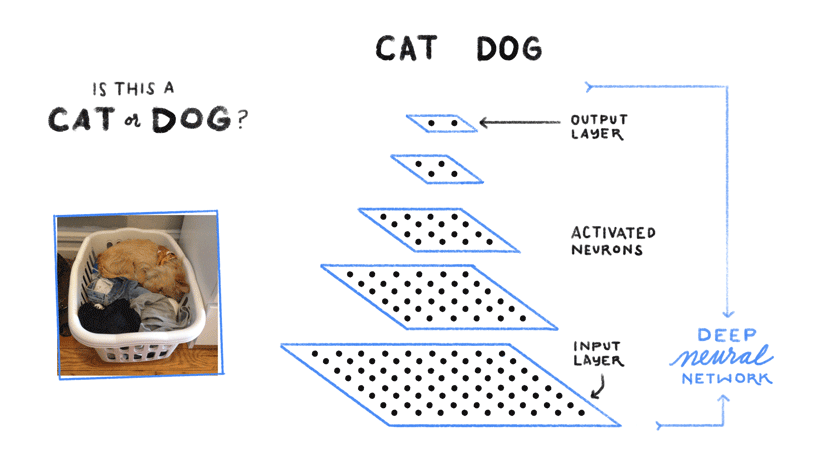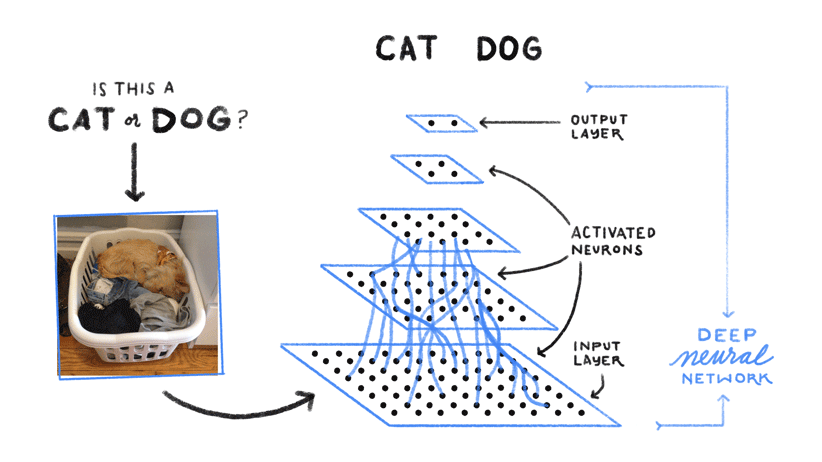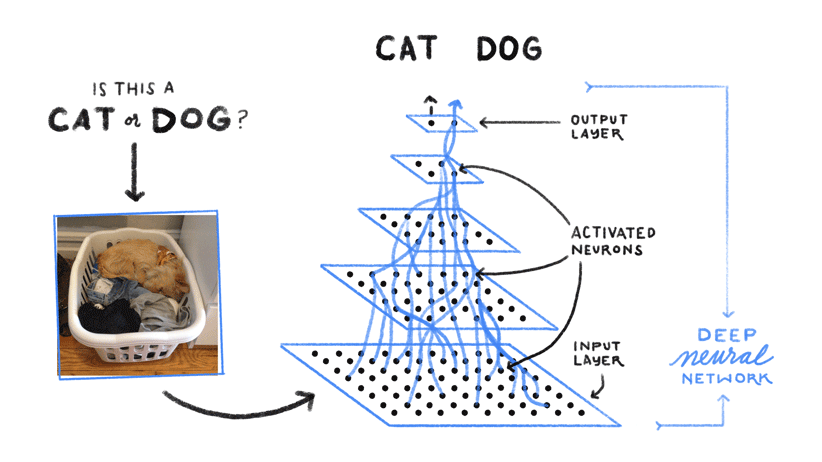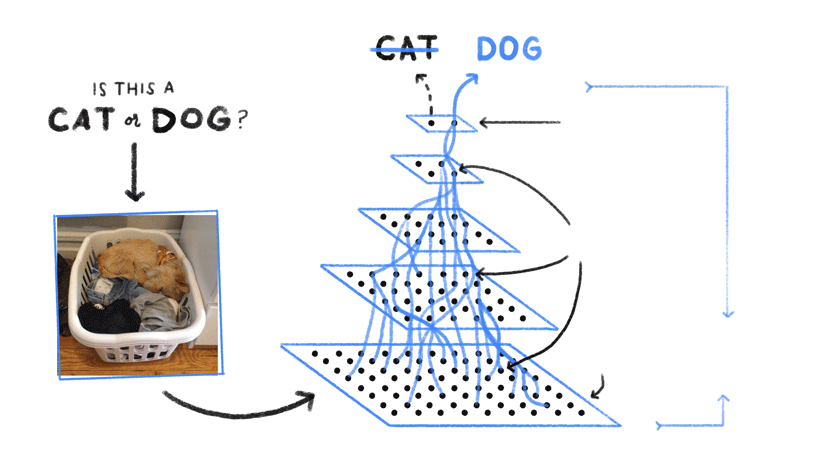
Una nueva forma de codificación de imágenes
Aunque las computadoras han aprendido a etiquetar, clasificar y comprender imágenes como los humanos mediante redes neuronales convolucionales, los algoritmos utilizados para hacer funcionar Google Lens van aún más lejos.
Basados en el embedding, una forma de codificación y aprendizaje de imágenes, los métodos utilizados son cada vez más avanzados: aprendizaje tanto de la invariancia como por similitud. El problema no es codificar los algoritmos, sino entrenar las redes neuronales. Estos métodos también se explicarán más adelante. Dan mejores resultados que los enfoques tradicionales. Por último, ofrecen la posibilidad de reducir la tarea de aprendizaje, entrenar mejor las redes neuronales y “reproducir” mejor los comportamientos humanos a gran escala.
Al combinar la imagen y el texto, los sistemas de Google son capaces de entender que los temas están relacionados. Lens extrapola y te sumerge en otra forma de búsqueda basada por la inteligencia artificial (IA).
El mayor reto reside en la capacidad de diferenciar las representaciones visuales para una computadora, que no es una tarea fácil. Como dijo Sundar Pichai (el big boss de Google) en la conferencia Google I/O el 11 de mayo de 2022: “La tecnología tiene el poder de mejorar la vida de todos. Sólo tienes que crearlo”. Google Lens ahora forma parte de ello.
“La tecnología tiene el poder de mejorar la vida de todos. Sólo tienes que crearlo”
Sundar Pichai
Google Lens es el resultado de un deseo claramente expresado por Prabhakar Raghavan, vicepresidente de Google y responsable de los productos Google Search, Assistant, Geo, Ads, Commerce y Payments: “hacer que la búsqueda sea más natural y más útil que nunca” (fuente: conferencia Google I/O, 11 de mayo de 2022). Google Lens es un intento de responder a este deseo, de dar un nuevo significado e impulso a la forma en que utilizamos Google.
“hacer que la búsqueda sea más natural y más útil que nunca”
Prabhakar Raghavan
Tanto para los usuarios lambda como para los profesionales del marketing digital, esta nueva forma de visualización abre una brecha en el ecosistema tradicional del SEO. El mobile first se está convirtiendo gradualmente en IA first. También deja espacio para los SEO que quieran trabajar de forma más avanzada y sutil en su SEO, ya sea en Google Imágenes, Google Maps, Google Shopping o Google Lens. Ahora tendrán que adaptarse a los nuevos datos impuestos por Alphabet, los de hacer que la búsqueda sea interactiva e inmersiva.
Ahora vamos a ver cómo Lens, a partir de una simple foto, te lleva a muchos mundos diferentes. Extrapolación, entrenamiento de algoritmos y resultados obtenidos. La búsqueda de información es prometida a nuevos horizontes basados en el uso de la imagen a gran escala. La cámara de tu smartphone puede estar a punto de convertirse en tu próximo teclado…
La forma en que utilizamos nuestros teléfonos está cambiando. Como demuestra la aplicación Google Lens, estamos entrando en la era de lo visual y de la búsqueda múltiple. ¿Cómo, a partir de una simple foto, Google Lens encuentra una respuesta a tu búsqueda visual? ¿Cómo te lleva a muchos universos diferentes? ¿Cuáles son los límites de la extrapolación y la relevancia de los resultados obtenidos? ¿Y por qué, a pesar del gran avance de tecnologías como la inteligencia artificial, el SEO dispone probablemente de lindos días para vivir? Explicaciones.
Hasta ahora, vimos como esta cambiando nuestra forma de buscar información con la llegada de una aplicación como Google Lens y vamos a ver más a fondo cómo funciona y las nuevas tecnologías en las que se basa.
Google Lens ofrece nuevas oportunidades de búsqueda
No sólo está cambiando la forma en que utilizamos las cámaras de nuestros smartphones: también está cambiando la tecnología que hay detrás de nuestros dispositivos. A medida que el hardware, el software y la inteligencia artificial siguen avanzando, está claro que Google Lens va mucho más allá de hacer fotos: nuevas formas de buscar información, copiar y traducir textos, buscar imágenes por similitud, explorar escenas o convertir imágenes en texto. El objetivo es siempre “hacer la búsqueda más natural e intuitiva”, según Sundar Pichai (fuente: Search On 2022).
Google Lens: el “Shazam” de las imágenes y del texto
Google Lens nació del deseo de ayudarte a buscar lo que ves y explorar el mundo que te rodea de una forma diferente. ¿Qué puede haber más divertido que encontrar el nombre de una planta desconocida en tu jardín o el nombre de una raza de perro a través del objetivo de tu cámara? ¿Qué puede ser más atractivo que buscar información a partir de una captura de pantalla, navegar por Google Maps gracias a un logotipo o escanear una etiqueta de ropa?
Estos son los pequeños extras que ya te ofrece Google Lens, pero no sólo. Como se mencionó al inicio, el objetivo de la aplicación Google Lens sigue siendo realizar una búsqueda sin palabras clave basada en la imagen. Aún mejor. Esta aplicación abre nuevas posibilidades: hacer que la búsqueda sea interactiva e inmersiva. Lens, junto con la búsqueda múltiple, te da la oportunidad de añadir una consulta adicional de texto (o voz) a tu búsqueda de imágenes (actualmente disponible en EEUU). La aplicación también te permite copiar y pegar texto, para actuar sobre las palabras que veas, en todos los idiomas (presentes en Google Translate).
¿Cómo Google Lens convierte las imágenes en texto?
La aplicación Lens puede discernir un texto y copiarlo para una búsqueda o traducirlo a muchos idiomas, sin tener que escribirlo. Para las personas con limitaciones visual, Lens puede leer el texto en voz alta mediante Google Text-to-Speech (TTS). Esto es impresionante:

Fuente: Google Research
También puedes hacer una foto de una tarjeta de presentación, copiar el texto, añadirla a tus contactos o abrir Google Maps directamente.
OCR: Reconocimiento Óptico de Caracteres
Para que Google Lens aprenda a leer, Alphabet desarrolló un motor de reconocimiento óptico de caracteres (OCR) y lo combinó con nuestra comprensión del lenguaje, ayudados por el Knowledge Graph. Todas estas características son posibles gracias al entrenamiento de los algoritmos en modelos de aprendizaje automático (redes neuronales artificiales, en particular). Éstos aprenden a distinguir las estructuras de los textos del mismo modo que lo haría un humano: análisis de frases y párrafos, bloques y columnas.

Para corregir los errores de lectura y mejorar la comprensión de las palabras, Lens utiliza el contexto de las palabras circundantes. Sin embargo, al igual que ocurre con el ojo humano, sigue siendo difícil para una máquina distinguir entre caracteres similares, como la letra “o” y el cero. Lens emplea sistemas (o modelos de aprendizaje automático) que le permiten discernir los caracteres y la estructura de la imagen. Lens también utiliza el Knowledge Graph. Esto proporciona indicios contextuales e identifica, por ejemplo, los nombres propios.
Algoritmos de traducción neuronales
Lens utiliza los algoritmos de traducción automática neuronale (NMT) de Google Translate para interpretar frases completas y ofrecer los resultados más relevantes posibles. Los errores en los resultados pueden deberse a distorsiones del texto, a la calidad de la foto y a los ángulos de la cámara. Recuerda que Google Lens sigue siendo el resultado de muchos algoritmos. Las tecnologías utilizadas ya ofrecen mejoras considerables.
¿Cómo Google Lens encuentra una respuesta a tu búsqueda visual?
Entonces, ¿cómo convierte Lens los píxeles de tu cámara en una respuesta de imagen al objeto que ves, digamos un Shiba Inu? La respuesta, como habrás adivinado, es el aprendizaje automático, el Knowledge graph y la visión por computadora.
Una atención especial a los detalles
Si utilizas Lens, podrás ver pequeños puntos blancos brillando. Cuando busca, presta especial atención a los detalles. Observa las formas, analiza los contornos, las sombras y los colores de las imágenes.
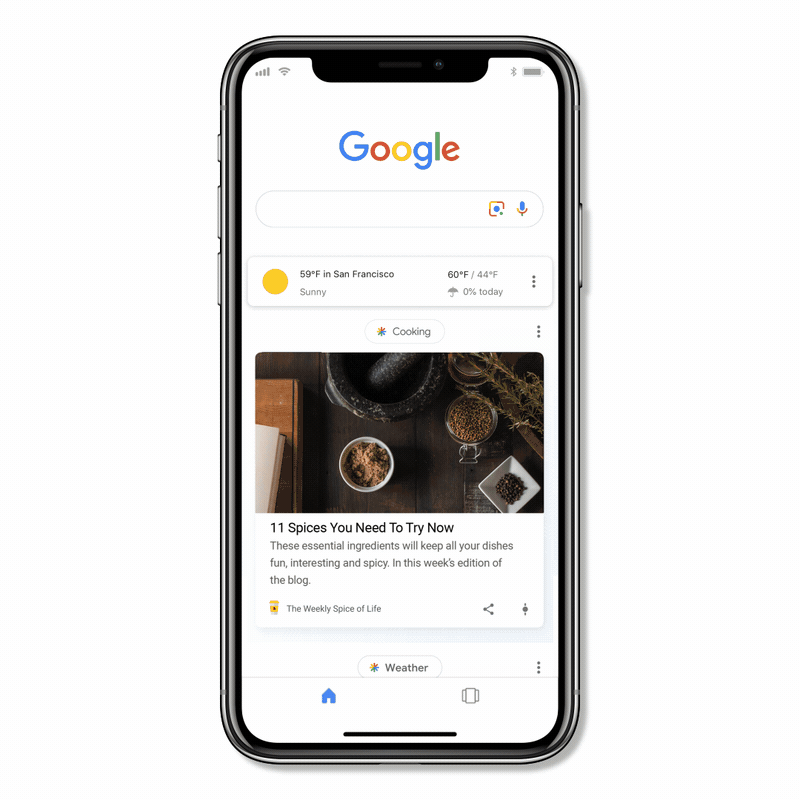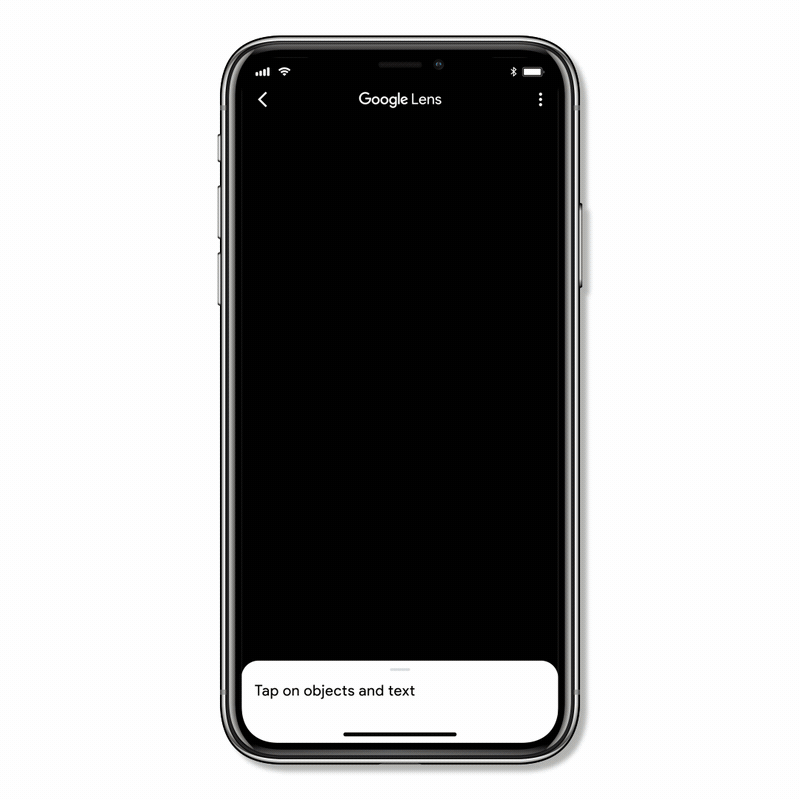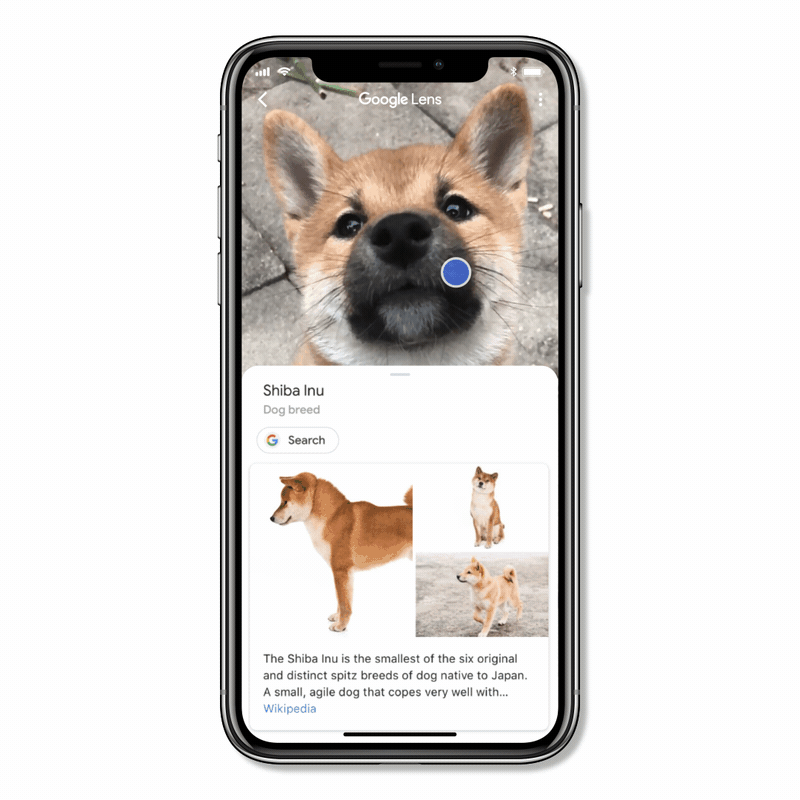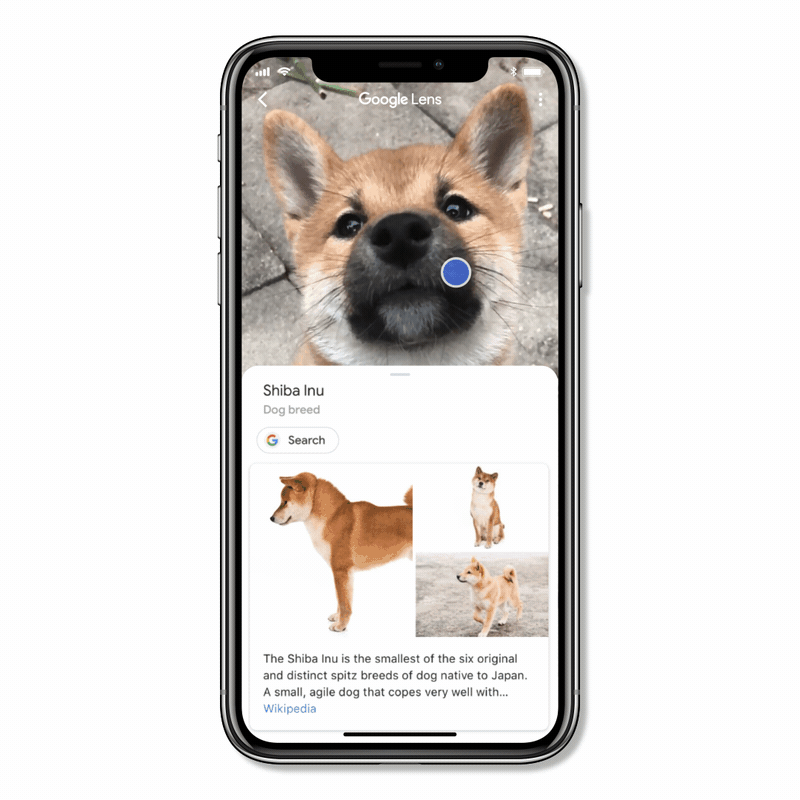
En pocas palabras, Lens compara los objetos de tu foto buscando similitudes y semejanzas en los objetos en cuestión. Pero en lugar de comparar dos imágenes entre sí, Lens compara tu foto con millones de objetos en sus bases de datos. Tras analizar tu imagen, Lens suele generar varios resultados posibles. Los clasifica según su grado de relevancia.
Si una imagen no está en su base de datos, Lens tendrá que utilizar otros métodos. Por ejemplo, encontrar una imagen que se parezca a otra, categorizarla y etiquetarla, o encontrar otras imágenes mediante la extracción de características con ayuda de la visión por computadora.
Avances considerables gracias a la IA
Para que la búsqueda con Google Lens funcione con el menor número de errores posible, las computadoras tienen que aprender un gran número de ejemplos, y numerosas veces. Para hacer cada vez menos cambios y reducir la potencia de cálculo, se utilizan nuevos avances de hardware y software, incluyendo la inteligencia artificial:
- Label/Entity Detection distingue el elemento dominante en una imagen.
- El OCR asocia el texto a una foto, así como el idioma utilizado.
- La Safe Search Detection identifica el contenido inapropiado.
- Facial Detection para detectar las caras.
- Logo Detection analiza los logotipos de marcas y productos en las imágenes.
- Landmark Detection asocia la ubicación (paisajes y espacios en todo el mundo) con estructuras diseñadas por el hombre.
Lens utiliza tu ubicación (con tu consentimiento) para generar resultados más precisos. Esto le permite identificar lugares y puntos de referencia con mayor facilidad. Si estás en Moscú, la aplicación entenderá que es más probable que busques información sobre la Catedral de San Basilio que sobre otra estructura de aspecto similar en otro lugar del mundo.

Hacer la máquina “insensible”
La complejidad para los algoritmos de Google Lens sigue siendo reconocer pequeños cambios que son insignificantes para ti, pero confusos para una computadora. Por ejemplo, un sombrero de vaquero en un perro puede sesgar los resultados y crear errores de concordancia visual. Como dice la investigadora y Googler Maya Gupta: “Hacer que la máquina sea insensible a los cambios significativos es un equilibrio que todavía estamos intentando alcanzar” (fuente: Google Machine Learning Q&A).
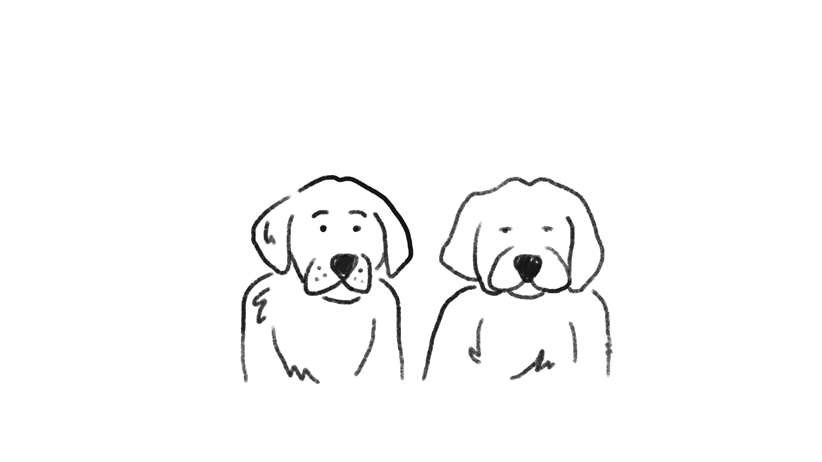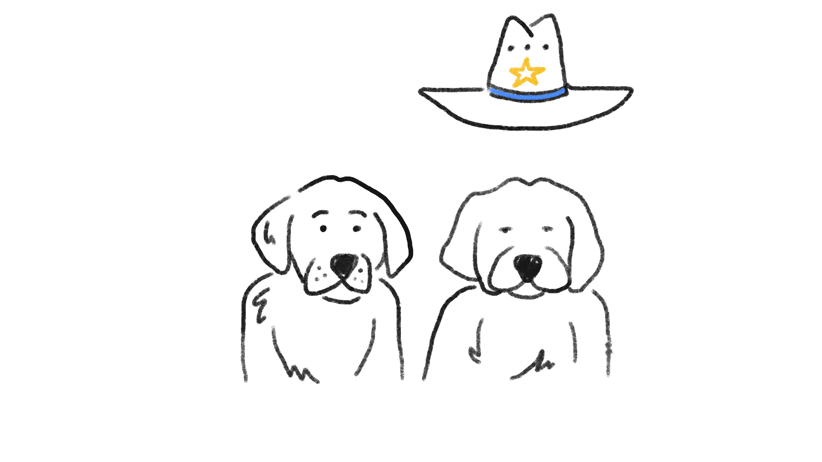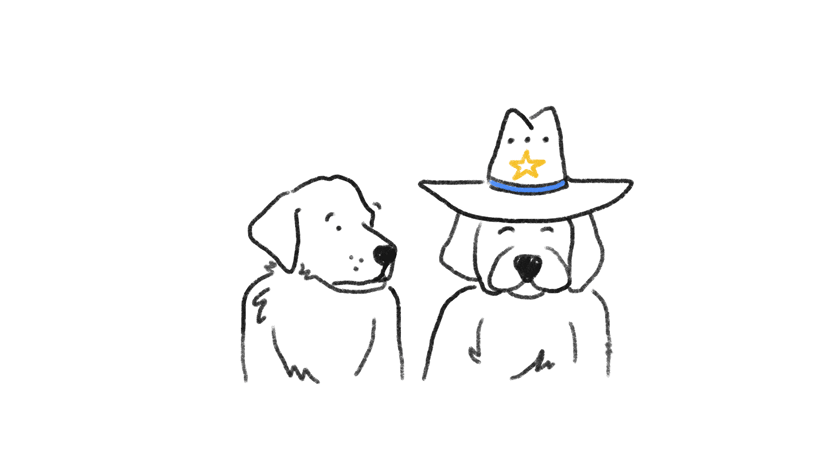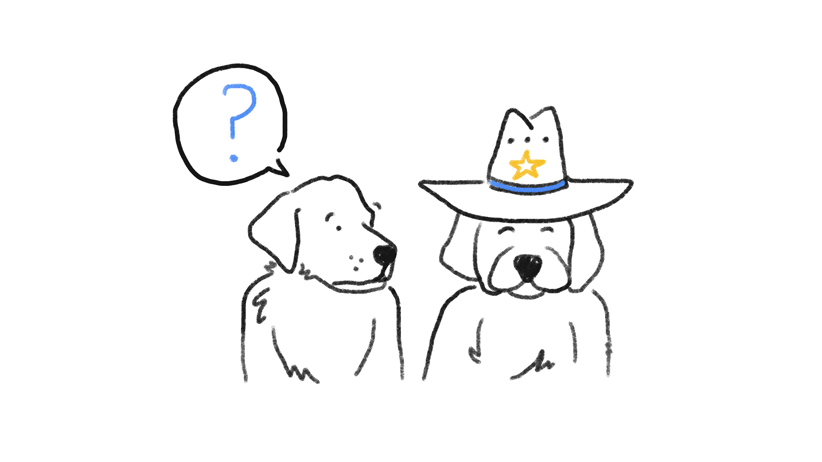
Google Lens y los errores de concordancia visual
Dependiendo de la calidad de la foto, la iluminación y de la presencia de sombras, la relevancia de los resultados mostrados por Lens puede verse comprometida. Esto se debe a que determinados parámetros pueden afectar a las formas, los colores y los contornos, que a su vez afectan a los datos con los que tiene que trabajar Lens.
Aunque nos gusta pensar que nuestras computadoras “piensan” y “entienden” como nosotros, en realidad no es así como funcionan. Simplemente son excepcionalmente buenos recordando cosas que han aprendido y haciendo cálculos muy, muy rápidamente.
Para comprender estos “errores” de correspondencia visual, parece necesario entender que, para que una computadora, aprenda una imagen, la reconozca al derecho, al revés, de día o de noche en un entorno inusual, sólo es posible mediante un aprendizaje específico.

Esto se debe a que a las computadoras les cuesta más captar la información que a nosotros. Donde nosotros vemos formas y objetos, la máquina “ve” una secuencia de números. Los algoritmos y las tecnologías permiten ahora a los motores de búsqueda trabajar al mismo tiempo sobre las imágenes, su contenido descriptivo y los textos. Esto se llama modalidad cruzada.
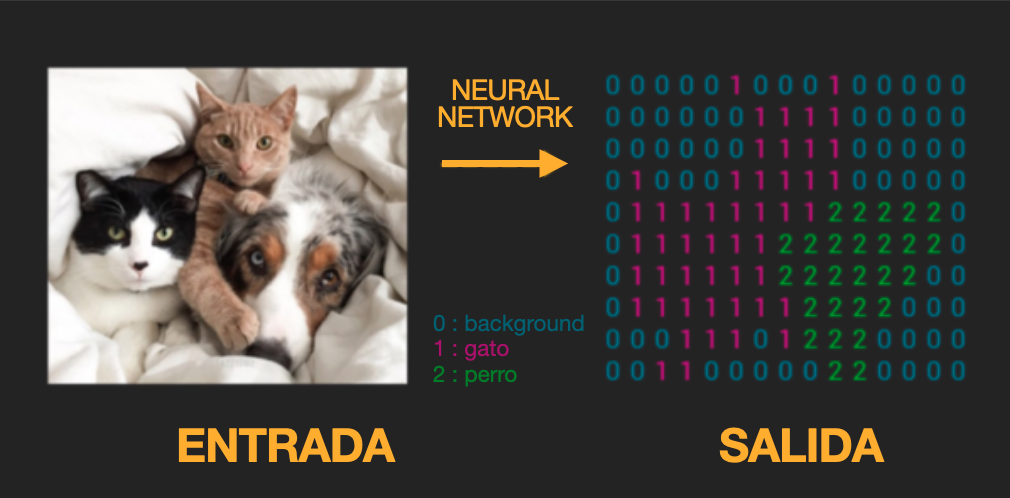
Ganar en relevancia con la integración de imágenes
Las integraciones de imágenes (o image embeddings) dan a las computadoras la capacidad de extraer información importante de una imagen y comparar fácilmente los datos que contiene. Integra los datos en un formato comprensible para los algoritmos de aprendizaje automático.
Ocupan poco espacio en memoria, pueden ser redimensionadas y lo hacen sin pérdida de información. Para analizar las imágenes, las computadoras tienen que transformarlas en una representación más adecuada. La inserción de imágenes es una representación vectorial de una imagen, que permite utilizar imágenes similares con un perfil vectorial parecido.
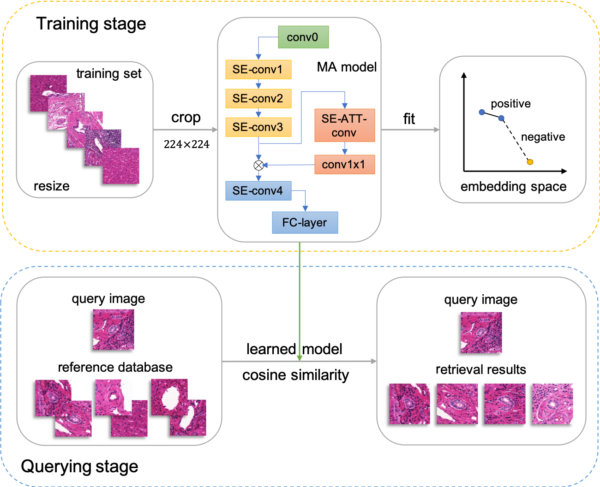
Esta técnica de extracción se utiliza para muchas tareas, como la clasificación. Al recuperar la información, se hace posible:
- Recupera una imagen a partir de sus características (buscar un gato a partir de fotos de sus orejas, su tamaño o el color de su pelo);
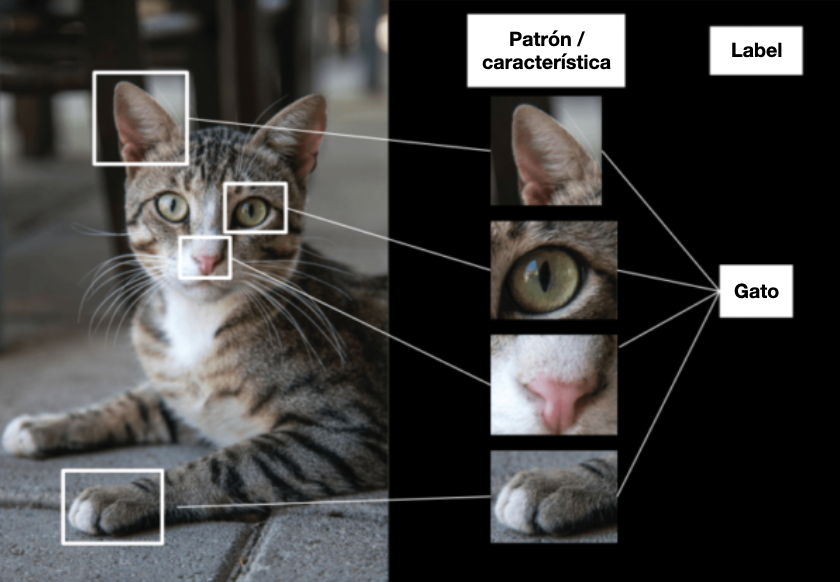
- Realizar búsquedas de imágenes por similitud.
- Formar grupos de objetos similares y agrupar información semánticamente similar, en varios idiomas (fuente: Image search using multilingual text : a cross-modal learning approach between image and text).
Esta tecnología desempeña un papel central en muchas aplicaciones, incluida Google Lens. También se utiliza en la recomendación de productos, la identificación facial o en el ámbito médico.
Ésta es una de las razones por las que las integraciones de imágenes se utilizan en la visión por computadora. Son muy fáciles de reutilizar una vez generadas.
Reconocimiento de imágenes a gran escala
El objetivo de Alphabet es ir más lejos y más rápido para construir un único modelo universal de integración de imágenes capaz de representar objetos en múltiples ámbitos.
El reconocimiento y el aprendizaje de objetos en entornos realistas presenta una variabilidad considerable para Google Lens.
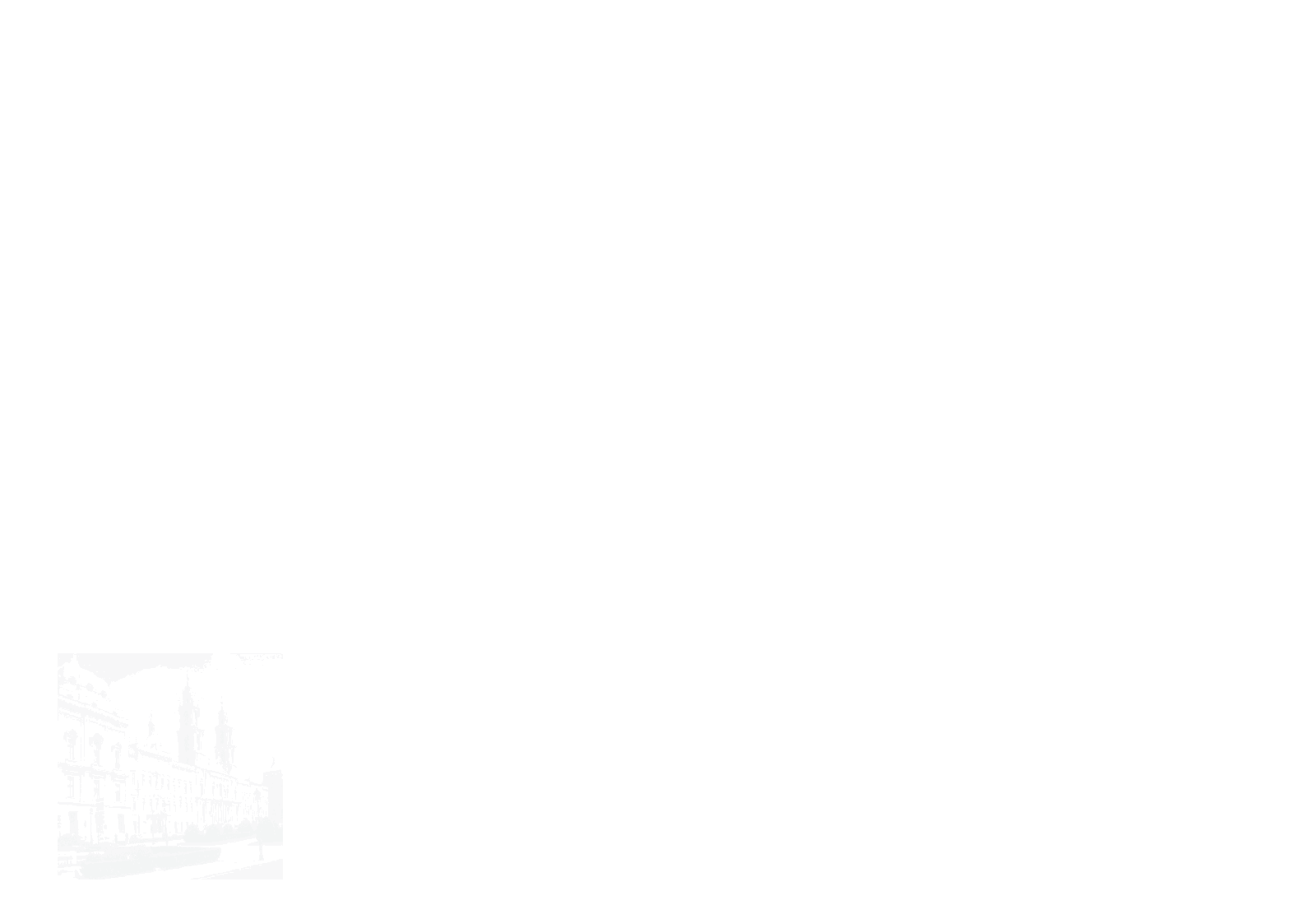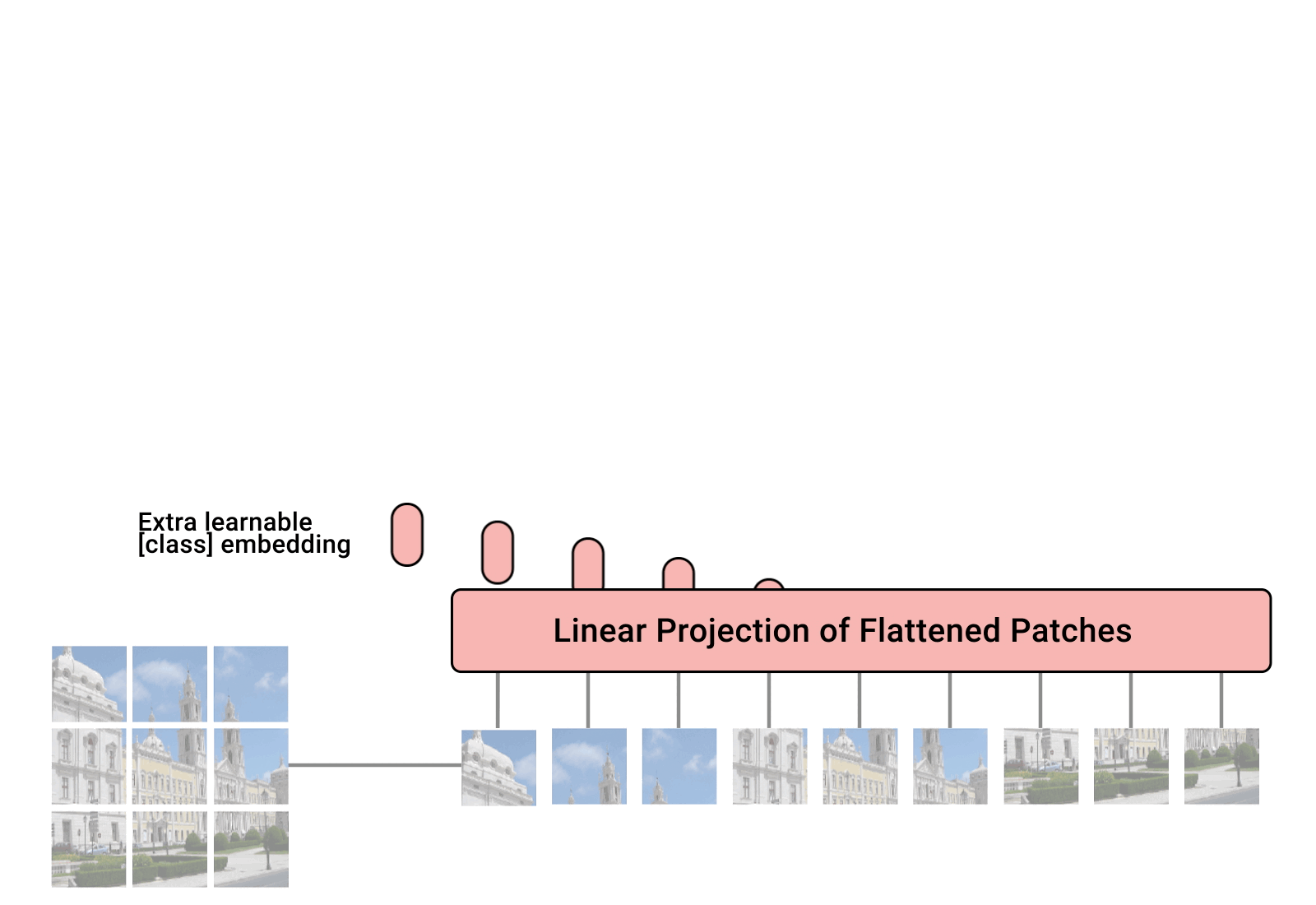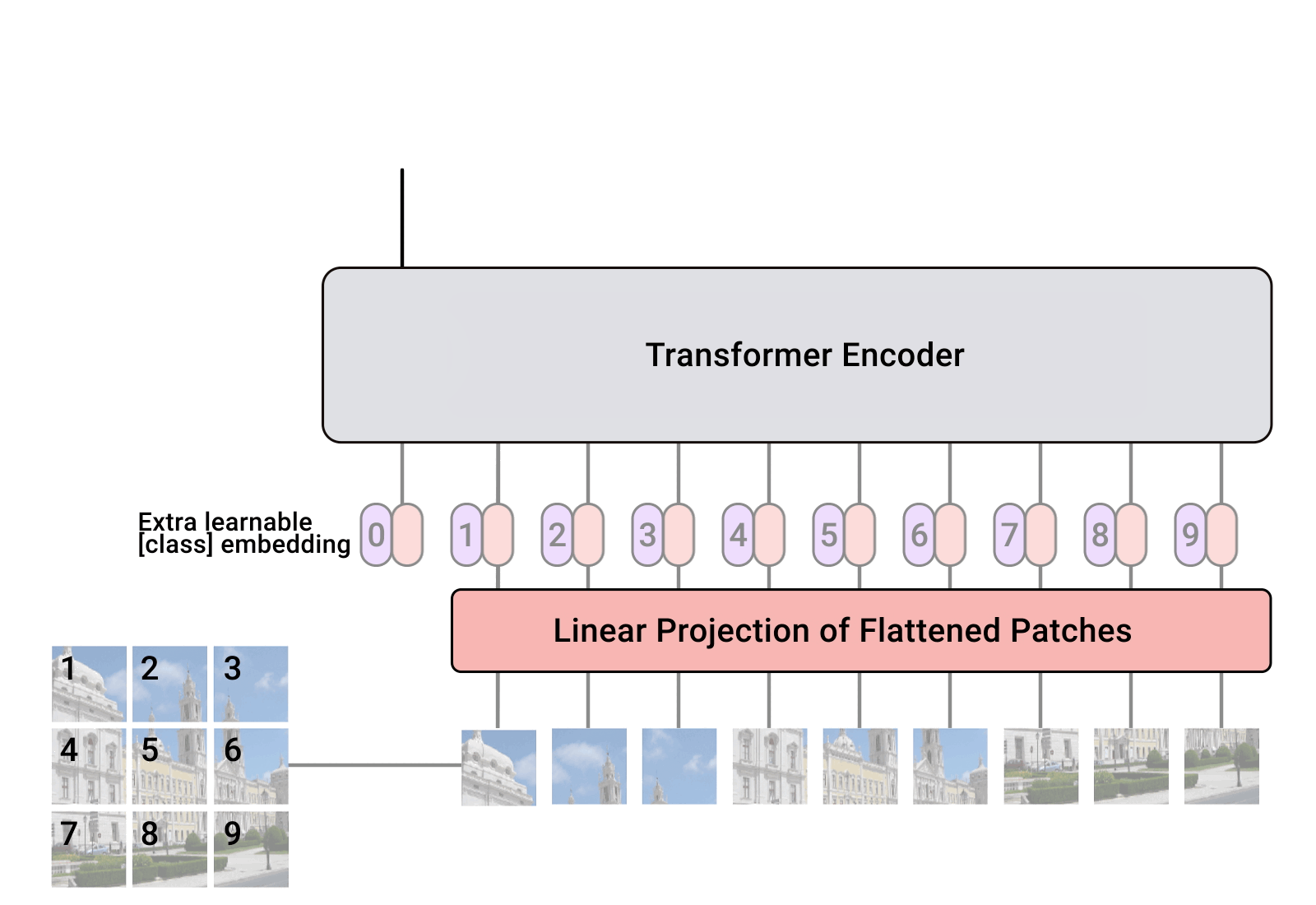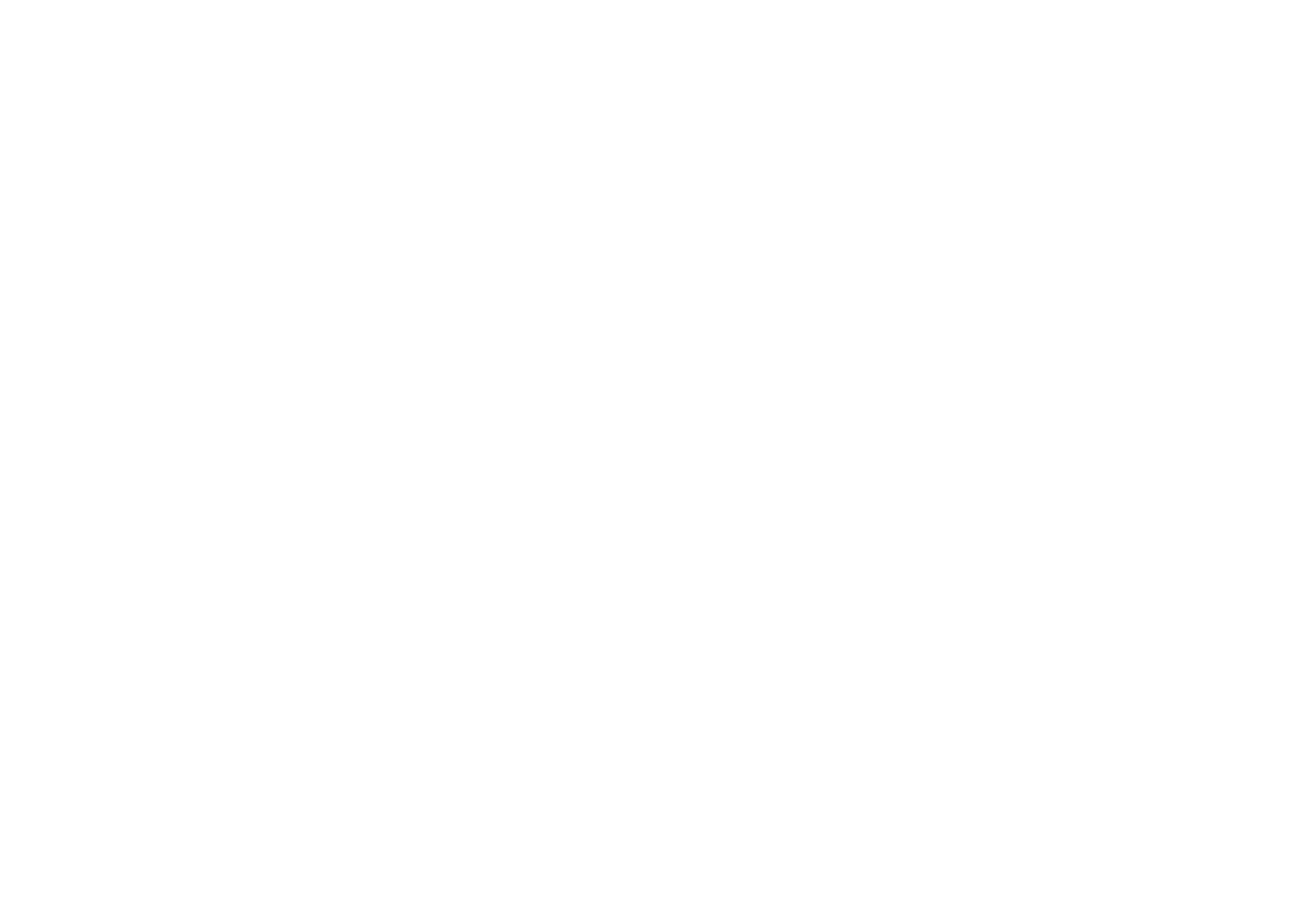
Para aprender a reconocer las imágenes que le proporcionas, es necesario utilizar conjuntos de entrenamiento mucho más grandes y rápidos, que requieren menos tiempo de entrenamiento. Utilizando estos enfoques, ahora es posible entrenar una red neuronal de forma casi autónoma, permitiéndole deducir las características de una imagen específica sin tener que construir un gran conjunto de datos ni proporcionarle etiquetas asignadas con precisión.
¿Y el SEO en todo eso?
¿Cómo afectaría la búsqueda múltiple de Google Lens en SEO? Los algoritmos de Google evolucionan de forma constante, así que esto no es una revelación. Sin embargo, la aplicación Google Lens y el multisearch modifica la forma en que buscamos información: utilizando texto e imágenes al mismo tiempo. Google Lens aún está en pañales, pero esta aplicación promete muchas mejoras con la búsqueda multimodal y la IA.
Es probable que Google integre cada vez más la búsqueda visual con sus otros productos, como Google Maps y Google Shopping. La única incógnita es el comportamiento de los internautas y en los móviles. ¿Les conquistará la búsqueda visual? ¿O se aferrarán a sus hábitos y a los diez enlaces azules que aparecen en Google Search y fracasará la búsqueda visual, como la búsqueda por voz, por falta de interés de sus usuarios?
Actualmente, parece difícil optimizar un sitio para la IA o para la búsqueda multimodal… Los resultados de Google Lens proceden, de momento, de otros productos de la empresa Alphabet como la búsqueda Google, Google Maps o Google Shopping. Parece legítimo pensar que los resultados mostrados dependen de los algoritmos de clasificación de estos productos. Por eso, seguir indexando y optimizando las imágenes es más que necesario. Insertar imágenes, crear contenidos pertinentes y accesibles para todos, sigue siendo una práctica sensata e incluso vanguardista.
Conclusión
Todos los SEO lo dicen: prioriza los pilares del SEO, técnico, contenido y popularidad. El SEO de imágenes, la accesibilidad digital, la optimización para móviles, las etiquetas clásicas (Title y Hn), por no hablar de la estrategia de contenidos, son cada vez más importantes en las estrategias SEO. Google sigue diciendo: crea contenido útil, pertinente y de alta calidad. Como lo demuestra la actualización de Google Helpful Content de agosto de 2022, las recomendaciones de Google son claras: privilegia los contenidos centrado en el humano y evita escribir para los motores de búsqueda.
En el futuro, la búsqueda múltiple puede requerir nuevas acciones de SEO. Google Lens formará parte, sin duda, de nuestro uso futuro. Sigue siendo necesario mantener la cautela y volver a poner al ser humano en primer plano, a pesar del uso preponderante de la IA, nos guste o no. Si escribes y optimizas contenido de calidad, que los humanos entiendan la relevancia de tu información, los algoritmos basados en IA y los motores de búsqueda también lo entenderán.


