
Los modelos de lenguaje no leen. No interpretan. No comprenden como nosotros. Pero eso no les impide responder. Responden todo el tiempo. Rápido, con seguridad, y cada vez más arriba en los resultados de búsqueda. Para lograrlo, no les basta el texto: necesitan estructura. Necesitan contexto. Necesitan entidades. Y no cualquier entidad, sino representaciones formales, tipadas, enlazables y coherentes dentro de un grafo semántico. Sin eso, no hay comprensión posible. Y sin comprensión, no hay visibilidad.
Entender una entidad nombrada no es recordar un nombre. Es reconocer una representación formal, conectada, desambiguada, computable. No es saber quién es Steve Jobs. Es saber que esa instancia de Steve Jobs tiene un ID en Wikidata, un atributo “founder of” que apunta a Apple Inc., un lugar de nacimiento, un tipo “Person” y una relación ontológica que lo distingue del DJ alemán del mismo nombre. Esa es la diferencia entre lo que tú crees que estás diciendo y lo que una máquina realmente puede entender.
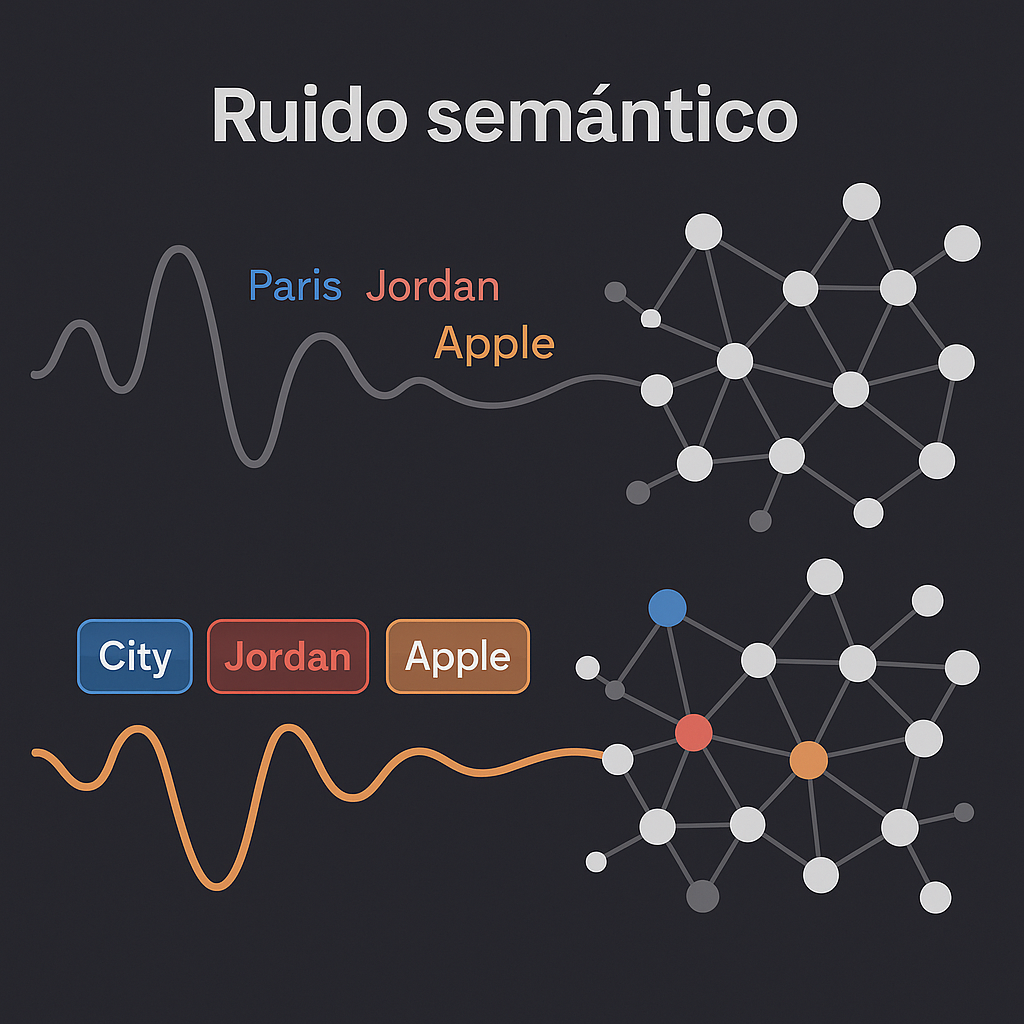
En el universo de los motores de respuesta, ya no competimos por frases. Competimos por sentido. Y ese sentido no emerge del contenido como tal, sino de su capacidad para ser insertado en una base de conocimiento estructurado. Si tu texto no puede ser enlazado, tipado y situado, entonces no será indexado como contenido relevante: será tratado como lo que es para el sistema…ruido semántico.
Por eso el SEO, si aún merece ese nombre, ya no empieza en la elección de palabras clave. Empieza en la identificación y formalización de entidades. Y sigue con su vinculación correcta en un grafo inferencial que los motores puedan recorrer.
Eso es “hablar” hoy con un motor de respuesta. Lo demás es soliloquio.
Del texto libre al grafo inferencial
En la vieja web —la de los contenidos libres, los textos orgánicos y las palabras clave esparcidas con entusiasmo artesanal— lo importante era publicar. Publicar mucho. Publicar con densidad. Publicar con cierta coherencia. Google hacía lo que podía con eso: contaba, clasificaba, calculaba. Se hablaba de “relevancia” como si fuera una propiedad natural de los textos, cuando en realidad era un efecto colateral del encaje estadístico entre búsqueda y redacción.
Hoy ya no estamos ahí.
Hoy los contenidos que valen son los que pueden ser leídos como datos.
Y los datos que importan son los que pueden ser convertidos en nodos dentro de un grafo de conocimiento: una estructura semántica donde cada entidad ocupa un lugar y se conecta con otras mediante relaciones explícitas. No es una red de páginas, sino una red de sentido.
Ese salto no es retórico. Es ontológico.
Una entidad nombrada no es una palabra con mayúscula. Es una unidad semántica disociada del texto que la contiene. Una instancia formalmente identificable, desambiguada, tipada y conectada. No se trata de escribir “Paris”, sino de que el sistema pueda inferir —sin margen de error— si hablamos de la capital francesa, de Paris Hilton o del pueblito de Texas con el mismo nombre. Y eso solo es posible si existen señales que permitan establecer esa relación: un atributo, un contexto, una relación explícita con otras entidades, un identificador en una base como Wikidata o DBpedia.
Para decirlo claro: una entidad es un objeto computable de significado.
Y el contenido que no puede producir entidades no es contenido: es texto sin estructura. Lo que los sistemas hoy llaman “non-actionable signal”. Y eso, traducido al idioma SEO, significa que no apareces en ningún lado.
Por eso la entidad es la nueva unidad mínima del sentido web. No la keyword. No el H1. No el párrafo. La entidad. Reconocible, enlazable, tipada, ubicada en un sistema más amplio de interpretación y relaciones.

La genealogía del grafo (origen estructural del SEO semántico)
Antes de que Google “entendiera”, primero tuvo que estructurar.
Todo esto no nació con un LLM ni con la IA generativa. Nació con bases de datos. En 2010, Google compró Freebase: un proyecto colaborativo de datos estructurados que aspiraba a mapear el conocimiento del mundo. Pero pronto se dio cuenta de algo: Freebase era útil, pero limitado. La verdadera mina de oro semántica estaba en Wikidata. Así que, en lugar de imponer su propia base, Google hizo algo que no suele hacer: alinearse con un estándar abierto.
Lo mismo pasó con el marcado estructurado. Schema.org no es una ocurrencia de Google: es el resultado de un acuerdo entre Google, Microsoft, Yahoo y Yandex para definir un vocabulario común que permitiera a los motores interpretar el contenido web no como texto plano, sino como entidades tipadas con propiedades estandarizadas.
Esa fue la verdadera fundación del SEO semántico.
No fue una estrategia de contenido. Fue un cambio de infraestructura.
Desde entonces, el posicionamiento dejó de ser una cuestión de palabras clave y se convirtió en una competencia por encaje ontológico.
Las bases de conocimiento no leen: comparan, conectan, verifican
El motor ya no recorre tu página como un lector. Recorre un grafo. Y lo que busca es ubicación relativa. ¿Dónde encaja este contenido en la red de entidades ya conocida? ¿A qué nodo apunta? ¿Con qué otros nodos se relaciona? ¿Hay alguna inconsistencia semántica entre lo que se dice y lo que el sistema ya sabe?
Esa operación —silenciosa, invisible para el usuario, pero absolutamente determinante— se llama inferencia. Y se produce gracias a tres capas de tecnología: la reconocimiento de entidades (NER), la vinculación de entidades (EL) y la estructura ontológica de fondo que permite determinar el sentido exacto de cada término a partir de sus relaciones.
Así es como el motor “comprende”.
No porque interprete.
Sino porque relaciona, conecta y triangula información declarada.
Si detecta “Jordan”, por ejemplo, no se precipita. Revisa el tipo de entidad: ¿persona? ¿marca? ¿país? Analiza el contexto: ¿hay mención de Nike? ¿de Amán? ¿de jugadores de la NBA? Evalúa las relaciones cercanas, los atributos asociados, los nodos con mayor peso semántico. Solo entonces decide a cuál “Jordan” te estás refiriendo. Ese es el proceso que permite a un sistema como Google responder con confianza creciente, incluso sin haber entendido “el texto completo”.
Y si tu contenido no coopera con ese proceso, no hay comprensión posible. No porque el sistema sea torpe, sino porque tú no estás hablando su idioma.
La ontología: el marco gramatical de la comprensión automática
Una entidad, por sí sola, no dice nada. Es solo un punto. Un dato bruto con aspiraciones. Para que esa entidad cobre sentido dentro del sistema, necesita una estructura que indique qué es, cómo se comporta, con quién se relaciona y qué puede o no puede hacer en el universo semántico donde habita. Esa estructura se llama ontología.
Y aquí es donde se rompe el mito del contenido como narrativa libre: una ontología no narra, clasifica. Define jerarquías, relaciones permitidas, atributos obligatorios, tipos, subtipos, restricciones y cardinalidades. No se pregunta qué significa una palabra. Se pregunta qué entidad puede ocupar una posición en un grafo, con qué propiedades, en qué dominio, bajo qué condiciones.
Dicho de forma brutal: la ontología no interpreta tu contenido, lo valida o lo descarta.
Por ejemplo: si mencionas a “Steve Jobs”, la ontología define que es una entidad del tipo Person. Si también mencionas “Apple Inc.”, del tipo Organization, y dices que uno fundó la otra, estás cumpliendo con una relación permitida (“founder of”) entre esos dos tipos. Esa coherencia ontológica fortalece la confianza del sistema en la interpretación. Pero si dices que “Steve Jobs” es una fruta o que “Apple” escribió Matar a un ruiseñor, la estructura se rompe. Y con ella, tu visibilidad.
“Elon Musk” → fundó → “Tesla” → es una → “Empresa”
“Elon Musk” → tiene cuenta → “@elonmusk” → en → “X (antes Twitter)”
“Elon Musk” → nació en → “Pretoria” → ubicada en → “Sudáfrica”
Esto no es academicismo. Es práctica SEO. Si tu contenido está alineado con una ontología robusta (como la de Schema.org, Wikidata o cualquier vocabulario RDF bien construido), entonces puede ser leído como dato semántico. Si no, sigue siendo solo una frase bonita que el sistema archivará en el olvido.
Y no, esto no se soluciona con más palabras clave.
Esto se soluciona con estructura.
Schema.org no es balizaje, es declaración de existencia
Durante años, se trató a Schema.org como un plugin estético. Algo que los SEOs colocaban como quien añade topping a un texto ya terminado: “Ponle Recipe”, “marca el Author”, “activa el FAQ”. Pero Schema.org no fue diseñado para embellecer resultados, sino para declarar formalmente qué representa cada porción de contenido dentro de una ontología reconocida por los motores.
Schema.org es, en efecto, una interfaz diplomática entre tu página y la base de conocimiento de los buscadores. Le estás diciendo a Google (y a Bing, y a ChatGPT): “esto que tú ves como texto, yo lo reconozco como una entidad del tipo Product, con tal nombre, tal fabricante, tal descripción, tal categoría, tal review”. Y si eso coincide con los patrones que ya existen en el grafo global, entonces eres comprendido. No posicionado. No premiado. Comprendido. Que hoy ya es bastante.
Schema.org no es semántico porque use palabras bonitas. Es semántico porque es tipado. Porque convierte cadenas de caracteres en objetos conectables. Porque inserta tu contenido en la infraestructura lógica de los motores. Es, por decirlo sin metáforas, la diferencia entre tener una voz y tener un ID.
Y en una web donde solo sobreviven las cosas que pueden ser enlazadas…
tener un ID es tener derecho a existir.
La web como red privada de grafos
La web ya no es un archivo de páginas. Es una red de grafos.
¿Y qué es un grafo? Es la estructura con la que los motores organizan su conocimiento. Un grafo está hecho de nodos(entidades) y enlaces (relaciones entre esas entidades). No piensan en párrafos. Piensan en conexiones.
“Steve Jobs” → fundador de → “Apple Inc.”
“Apple Inc.” → sede en → “Cupertino”
“Cupertino” → ubicado en → “California”
Eso es un grafo. Una red semántica que permite navegar el mundo no por frases, sino por relaciones inferenciales.
Y ese grafo, al que todos aspiramos entrar, no es público.
No es neutral.
No es tuyo.
Los motores no se alimentan solo de Wikipedia o Schema.org. También nutren sus propios grafos privados con información que tú no puedes ver, editar ni contradecir. El Microsoft Knowledge Graph se alimenta de LinkedIn. El de Google, de Maps, Books, Shopping, Business Profiles y todas esas fichas que tú nunca pensaste que estaban estructuradas… pero lo están.
Esto genera una asimetría brutal: tú redactas contenido como si el texto bastara, pero el motor conecta entidades en grafos que tú no controlas. No optimizas para un lector. Optimizas para una arquitectura que ya existe, que tiene sus propias reglas ontológicas y que filtra lo que es visible o no desde su lógica de conexiones.
Así que cuando escribes, no compites con otros textos.
Compites con nodos invisibles que ya están ahí.
Y el único modo de participar es hablar con suficiente precisión semántica para que el sistema te reconozca como un nodo confiable de su grafo.
El modelo EAV: cuando Schema.org no alcanza, pero el sentido no se negocia
Por muy extenso que sea el vocabulario de Schema.org, la realidad de cada proyecto suele ser más compleja. Hay sectores, productos, contextos donde no existe aún una propiedad predefinida para lo que quieres declarar. Y ahí aparece un viejo aliado del conocimiento estructurado: el modelo EAV (Entidad-Atributo-Valor).
El EAV no necesita una ontología cerrada para empezar a funcionar. Permite describir entidades de forma flexible, agregando atributos no previstos originalmente, sin romper la estructura general. Es una solución usada en medicina, en bibliotecas, en sistemas CRM, y sí: también en SEO editorial de verdad. Porque permite que cada entidad tenga atributos específicos aunque no estén contemplados en un esquema estándar.
Un vino puede tener “nivel de taninos”, un medicamento “periodo de latencia”, un producto artesanal “técnica de elaboración”, sin que Schema.org tenga propiedades explícitas para eso. Lo importante no es que el atributo exista en el estándar, sino que esté estructurado como tal, con lógica de par (Atributo → Valor) bajo una entidad concreta. Eso permite extender la semántica sin improvisación.
En resumen: Schema.org sirve cuando se puede. El EAV sirve cuando se debe.
Y si no usas ninguno de los dos, simplemente estás dejando que tu contenido hable… pero sin gramática formal.
Saliencia de entidad, lo que importa no es que la menciones, sino que la articules
Puedes repetir “Apple” veinte veces.
Puedes ponerlo en el título, en los H2, en el primer párrafo y en los alt de las imágenes.
Pero si tu texto no articula a “Apple” como nodo central del contenido, no importa. El motor lo detectará, lo clasificará como tangencial, y priorizará otro documento con mejor estructura semántica.
Eso es lo que hoy se mide como entity salience: el grado de centralidad e importancia que una entidad tiene dentro del texto, no en función de su frecuencia, sino en función de su estructura, conexiones, contexto y persistencia temática. Una entidad con alta saliencia es aquella que organiza el texto, no solo aparece en él.
Y eso no se logra con copywriting emocional ni con storytelling suelto. Se logra con jerarquía.
Con títulos coherentes, con propiedades bien definidas, con contexto técnico, con estructura clara.
En otras palabras: se logra cuando el contenido no solo menciona, sino que modela una entidad.
Es el paso definitivo del SEO hacia una forma de escritura que no persuade, sino que posiciona mediante estructura formal.
Es incómodo. Es antipático. Pero es real.
La web multimodal y el refuerzo no textual
Pero no todo es texto.
Hoy los sistemas de información son multimodales. Eso significa que comprenden no solo lo que dices, sino también lo que muestras, enlazas, anotas y transcribes. Una imagen con atributos bien definidos puede reforzar una entidad. Un video con subtítulos estructurados puede generar señales semánticas. Una tabla con propiedades claras puede ser más útil para la inferencia que un bloque de texto emocional.
Porque la comprensión algorítmica no discrimina por formato. Discrimina por estructura y conexión.
Lo importante ya no es el tipo de contenido, sino su capacidad para ser procesado como dato significativo dentro de una red de interpretación.
Monosémanticidad o muerte
Y aun así, no basta con mencionar bien. Hay que mencionar una sola cosa.
Esa es la lógica de la monosémanticidad: cuando un contenido apunta a una entidad, debe hacerlo con una claridad tal que no admita ambigüedad. Ni para humanos, ni para máquinas.
Si escribes “Jaguar” y no resuelves si es el felino, el auto o el equipo, generas confusión semántica. Pero si mencionas “Jaguar” y luego hablas de hábitats naturales, felinos en América Latina y la cadena alimenticia, estás guiando al motor hacia el nodo correcto.
Esa es la diferencia entre estar posicionado… y estar correctamente enlazado.
No es una tarea de estilo. Es una tarea de alineación semántica total.
Porque si una entidad tiene múltiples sentidos posibles y tú no resuelves cuál estás invocando, el sistema te va a ignorar.
No porque no lo hayas dicho, sino porque no lo dijiste con monosémanticidad suficiente.
LLMs: los modelos que no entienden, pero sí conectan
Los grandes modelos de lenguaje —esos que hoy llamamos motores de respuesta— no entienden tu texto. Lo predicen. No razonan. Interpolan. Y sin embargo, generan respuestas que suenan lógicas, bien construidas y, en muchos casos, útiles. ¿Cómo lo logran?
En parte, porque no trabajan sobre texto plano. Trabajan sobre representaciones semánticas enriquecidas. Usan embeddings, redes conceptuales y, sobre todo, entidades reconocidas. Las entidades actúan como anclas de significado. Les permiten asociar partes de un texto con hechos conocidos, con datos estructurados, con inferencias pasadas.
Si escribes un artículo con buena estructura de entidades, no solo posicionas mejor: te vuelves fuente para los modelos que generan respuestas. Esa es la frontera entre el contenido que Google cita en su AI Overview y el que ignora.
Y si crees que eso no afecta tu estrategia, repasa tus clics de las últimas semanas: la mitad de las veces, no llegaste al contenido. Te quedaste en la respuesta.
El camino para aparecer en esa respuesta no es la redacción brillante. Es la arquitectura semántica.
Es el trabajo de fondo con entidades claras, coherentes, conectadas.
Es el nuevo tipo de visibilidad: no estar en el índice, sino en la inferencia.
El SEO ya no optimiza contenido: optimiza comprensión
La paradoja es esta: nunca tuvimos tantos recursos para escribir bien y nunca fue tan irrelevante escribir bien. Porque ya no se trata de expresión. Se trata de formalización. No es una crisis de estilo, es una crisis de representación.
El SEO ya no optimiza palabras. Optimiza estructuras inferenciales. Relevancia ya no significa que tu contenido es útil, sino que puede ser conectado, inferido, proyectado en una red de conocimiento. La competencia ya no es textual. Es semántica. Y esa semántica no está en tu cabeza, ni en la de tu lector: está en Wikidata, en Schema.org, en los grafos internos que cada modelo de lenguaje usa para decidir qué responder antes incluso de mostrar tu sitio.
Esto no es el fin del contenido. Es su reorganización bajo reglas que no escribimos. Ya no somos autores, somos proveedores de datos ontológicamente compatibles. Si eso suena duro, es porque lo es. Pero también es la única vía para que lo que escribes no se disuelva en el nuevo régimen de invisibilidad: el de los textos que no pueden ser comprendidos por los sistemas que deciden qué merece ser leído.
Así que no, entender las entidades nombradas no es una tarea técnica más. Es la forma de hablar un lenguaje que no fue creado para ti, pero que decide tu presencia en el mundo digital. Porque los motores ya no buscan. Responden. Y si tú no estructuraste tu contenido como una respuesta posible, no lo harán contigo. Porque para ellos, no estuviste ahí.
Y el SEO (ese SEO que sobrevive a los rankings, a las modas y a los prompts) solo tiene una cosa que aprender de todo esto: si tu contenido no es una entidad, entonces es prescindible. Aunque tenga sentido. Aunque tenga estilo. Aunque tenga razón.


