
El buscador ya no interpreta: reconstruye. Lo que antes era una consulta ahora es una sospecha algorítmica, y lo que era SEO técnico hoy es apenas ruido en el grafo.
Pensábamos que Google era un motor de búsqueda. Luego creímos que era un sistema de ranking. Después, que era una IA que entendía el lenguaje. Y ahora… ahora ni siquiera estamos seguros de que sea “uno”.
Porque en 2025, Google dejó de ser un producto: se convirtió en un organismo. Uno que no responde, sino que reacciona; que no busca, sino que recuerda; que no clasifica, sino que representa el mundo en estructuras vectoriales que nadie ve, pero todos sufrimos.
Este artículo no intenta explicar cómo funciona el nuevo Google. Intenta advertirte que ya no funciona como creías.
1. El experimento perpetuo: Google ya no lanza versiones, las disuelve
Durante años nos acostumbramos a leer titulares del tipo “Nuevo algoritmo de Google”, “Llega una nueva versión de Search”, o “Core Update en camino”. Como si el buscador se reiniciara cada tanto, como una app que se actualiza a medianoche. Pero eso ya no es así. O mejor dicho: nunca fue tan así.
Los dos informes recientes de RESONEO y 1492.vision revelan que Google funciona como un laboratorio en constante funcionamiento. : Google opera como un laboratorio permanente. En junio de 2025, hay más de 1 200 experimentos activos en el sistema, 800 de ellos en producción o evaluación directa. Cada uno con su propio nombre, su propia lógica, y su impacto medido milimétricamente sobre una fracción de usuarios antes de decidir su adopción.

El sistema no solo prueba en paralelo. Itera, renombra, bifurca. Algunos de los experimentos ya van por su versión 15, como MagitCotRev15Launch, que implementa una técnica de razonamiento llamada Chain of Thought (Reflexión → Investigación → Lectura → Síntesis → Pulido). Un sistema que no solo responde, sino que explica su razonamiento. En cinco pasos. Por escrito. Como un estudiante de filosofía ansioso por justificar su nota.
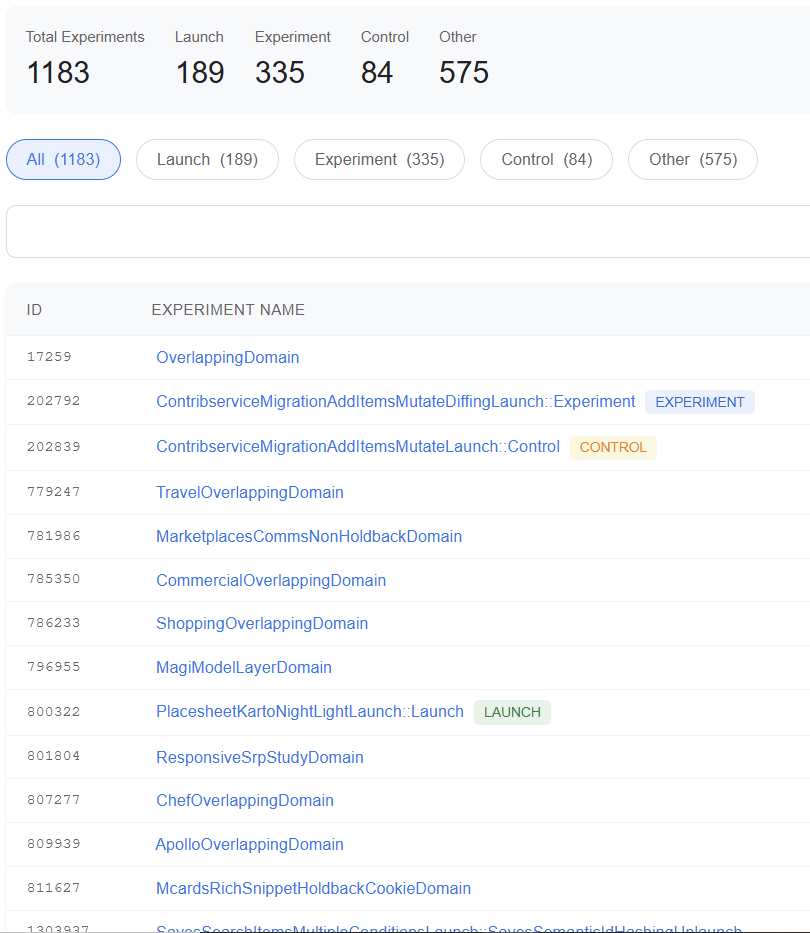
Esto no es SEO clásico. Es ingeniería distribuida. No hay “actualizaciones mayores” cada trimestre. Hay un sistema vivo que nunca se detiene, y que evoluciona en silencio como un organismo autorregulado. Lo que nosotros llamamos algoritmo es, en realidad, un enjambre de módulos, APIs, reglas, y ajustes experimentales que entran y salen todos los días.
El SEO se volvió, literalmente, impredecible. Pero no porque Google esconda su lógica. Sino porque la lógica ha dejado de ser unívoca.
2. La arquitectura por dominios: un Google diferente para cada vertical
La estructura del buscador ya no es un monolito que aplica las mismas reglas a todos los contenidos. Lo que han revelado estos reportes es que cada vertical temática dentro de Google tiene su propio espacio experimental, aislado del resto mediante una estructura llamada OverlappingDomain.
Esto quiere decir que lo que ocurre dentro de ShoppingOverlappingDomain (comercio electrónico), no interfiere con SportsOverlappingDomain (deportes), ni con TravelOverlappingDomain (viajes). Cada equipo de producto ejecuta experimentos aislados, con métricas propias, y con sus propios criterios de evaluación.
¿Por qué esto es clave para el SEO?
Porque significa que el mismo contenido evaluado en dos verticales diferentes puede tener resultados completamente distintos, aunque las señales de calidad sean idénticas. Una ficha de producto optimizada para Google Shopping no será evaluada igual que un artículo en Google News, o que una reseña turística en Google Maps.
Y más aún: cada vertical tiene sus propios experimentos, su propia lógica de ranking, su propia capa de IA, y sus propios agentes.
Este modelo fracciona la idea de “hacer SEO en Google” en múltiples universos paralelos. Lo que funcionaba en el dominio de noticias puede ser penalizado en el dominio de comercio. Y lo que es útil para el usuario en una intención transaccional puede ser irrelevante o incluso contradictorio en una intención navegacional.
En términos prácticos: ya no existe un único Google. Existen decenas. Y tu estrategia SEO debe entender en cuál de ellos estás operando.
3. El Knowledge Graph ya no es un panel, es el sistema nervioso del buscador
La mayoría de las personas y lamentablemente también muchos profesionales SEO siguen pensando que el Knowledge Graph es esa caja a la derecha en los resultados de búsqueda. Ese panel con fotos, fechas, logotipos y biografías. Bonito, útil… y absolutamente secundario.
Grave error.
Lo que han confirmado estas investigaciones es que el Knowledge Graph no es un accesorio visual. Es el núcleo funcional de todo el ecosistema Google. Search, Discover, YouTube, Maps, Gemini, Assistant, AI Overviews… todo bebe de esa misma fuente: el grafo de entidades interconectadas que Google construye, alimenta y jerarquiza de forma continua.
Y lo más inquietante: no todo lo que existe en el grafo tiene el mismo peso. Google ha establecido una jerarquía interna que asigna niveles de confianza a cada hecho antes de decidir si lo incorpora o no. Ese sistema se llama Livegraph, y funciona como un aduanero semántico: decide qué tripletas (sujeto–predicado–objeto) merecen formar parte del conocimiento oficial del buscador.
Esta jerarquía se estructura mediante espacios de nombres (namespaces) como:
- kc: datos de confianza absoluta, provenientes de fuentes oficiales (registros gubernamentales, bases validadas, etc.)
- ss: “webfacts” extraídos del contenido web, menos verificables pero aún aceptables
- ok: “shortfacts”, breves y más superficiales
- hw: hechos curados manualmente por humanos, usados como capa correctiva
Este orden no es meramente decorativo. Determina qué hechos son mostrados, cuáles influyen en los resultados, y cuáles son descartados por baja fiabilidad. En otras palabras: Google no cree todo lo que dices. Y aunque te crea, puede que no te crea tanto como a otro.
¿Y cómo se gana la confianza de Livegraph? Con validación cruzada. Con coherencia temática. Con enlaces y menciones en sitios de autoridad. Con patrones de comportamiento detectados en Chrome y Android. Con citas en Wikipedia. Con presencia en bases institucionales. Con contexto.
Si alguna vez pensaste que tu objetivo como SEO era “posicionar una keyword”, conviene actualizar ese mantra: tu verdadero objetivo es convertirte en una entidad validada del Knowledge Graph. Todo lo demás es efímero.
4. Las entidades flotantes o cuando Google reacciona más rápido que tú
Mientras tú aún estás redactando el contenido que responde a una nueva tendencia, Google ya la está mostrando en sus resultados. ¿Cómo es posible?
La respuesta está en un mecanismo casi desconocido fuera del circuito técnico más avanzado: las entidades flotantes (también llamadas ghost entities). Se trata de representaciones temporales que Google genera en el Knowledge Graph sin necesidad de validación completa. No tienen aún un MID (Machine ID) definitivo, ni han sido confirmadas por fuentes oficiales. Pero ya existen. Ya se indexan. Ya responden.
¿Su función? Actuar como zona de amortiguación semántica, permitiendo que el sistema responda en tiempo cuasi real a eventos emergentes. Un accidente masivo. Un escándalo político. Un personaje viral. Una expresión que nadie buscaba ayer y hoy sí. Todo eso puede dar origen a una entidad flotante antes de que tú sepas que existe.
Mientras los modelos de lenguaje clásicos (como los LLM que usamos los mortales) están congelados en su corte de entrenamiento, Google inyecta estas entidades “en caliente” en sus productos. Las valida de forma progresiva a medida que detecta señales confiables, y las reemplaza o confirma más adelante cuando la información se estabiliza.
Este sistema no funciona por arte de magia. Está sustentado por dos módulos clave revelados en los leaks de 2024:
- SAFT (Structured Attribute Fusion Toolkit): que analiza atributos dispersos y los agrupa en tripletas significativas.
- WebRef: que extrae, clasifica y vincula menciones para proponer nuevas entidades o reforzar las existentes.
En conjunto, actúan como un sistema nervioso periférico que detecta microseñales en la web (tweets, títulos, subtítulos, datos estructurados, menciones), y las convierte en una representación provisional útil para el ecosistema.
Esto no es solo fascinante. Cambia por completo la dinámica de visibilidad en el buscador. Porque ahora no solo importa lo que escribes, sino lo que el sistema detecta como emergente, mencionable y conectable antes de que lo conviertas en contenido útil.
La pregunta ya no es “¿cómo posiciono este contenido?” sino “¿cómo puedo entrar en la conversación del grafo antes de que se cierre?”
Y eso, amigo, no se logra con un brief. Se logra con una estrategia de presencia semántica en tiempo real.
5. El AI Mode es el buscador de constelación de agentes
Si pensabas que Google estaba construyendo su propio ChatGPT, estás mal.
Google no está creando un “asistente”. Está desplegando una constelación de agentes inteligentes especializados, cada uno con una tarea, un dominio temático y una lógica propia. El nombre de esta revolución es AI Mode, y el proyecto interno que lo articula se llama Magi.
Lo interesante no es que el buscador haya integrado inteligencia artificial. Lo interesante es cómo lo ha hecho: no con un solo modelo que responde a todo, sino con decenas de agentes individuales que colaboran como si fueran un sistema operativo semántico.
La lógica Magi
Bajo el paraguas de Magi, se han identificado más de 50 experimentos activos que construyen las capas de esta nueva realidad. Algunos de ellos con nombres que parecen diseñados para asustar a los SEOs tradicionales:
MagitCotRev15Launch(ya en su versión 15),GwsLensUnimodalMagiWithGrounding,SuperglueMagiAlignment,MagiMathEnAllSrp.
Cada uno ejecuta funciones específicas, como razonamiento paso a paso (la ya mencionada Chain of Thought), grounding semántico con imágenes o video, mejoras en el alineamiento entre intención y presentación del resultado, y reformulación avanzada de prompts.
Pero lo más importante no son los nombres. Es el principio organizador: Google no opera como un buscador con IA, sino como un orquestador de múltiples inteligencias colaborativas.
Ejemplos de agentes activos:
- MedExplainer: interpreta y reformula resultados médicos.
- Travel Agent: genera comparativas y consejos personalizados para viajes.
- Smart Recipe y Neural Chef: convierten ingredientes y preferencias en recetas útiles (y sí, también posicionadas).
- Shopping AI Studio: reorganiza listados de ecommerce según comportamiento, intención y perfil.
Este modelo rompe definitivamente la estructura clásica de resultados tipo “10 blue links”. Ahora el buscador conversa contigo, anticipa, sintetiza y decide qué agente debe responder en tu lugar. La vieja arquitectura “query–matching–ranking” está siendo desplazada por sesiones conversacionales que involucran contexto histórico, embeddings de usuario y preferencias detectadas.
Y aquí es donde los SEOs nos jugamos la existencia.
¿Qué implica esto para el SEO?
- La hiperespecialización se vuelve obligatoria. Ya no vale escribir “contenido útil” genérico. Hay que producir piezas que compitan con las respuestas que daría un agente experto entrenado en ese dominio.
- La multimodalidad no es un lujo, es el nuevo estándar. Si tu contenido no puede ser interpretado como texto, imagen, estructura o dato referencial al mismo tiempo, quedará fuera del grafo y fuera de los resultados enriquecidos.
- La experiencia ya no es UX, es contexto. El sistema evalúa no lo que haces en una página, sino cómo se alinea esa experiencia con tu intención previa y tu perfil embebido.
El SEO de 2025 no compite contra otros sitios. Compite contra un ejército de agentes cognitivos diseñados para hacerlo mejor, más rápido y con más contexto.
Y mientras tú estás escribiendo un artículo de blog “Qué hacer en Cancún”, (lo mismo que 459 otros sitios), el Travel Agent ya reservó el hotel, recomendó el restaurante y te sugirió un itinerario. Con solo una consulta.
6. Embeddings y perfiles vectoriales, Google te conoce mejor que tú
Hay una idea que muchos todavía no han entendido: los modelos de lenguaje no leen. No interpretan páginas web como lo haría un humano. No “entienden” tus textos. Lo que hacen es convertirlos en números.
Y no cualquier tipo de números. Embeddings: vectores matemáticos que condensan el significado, el tono, la intención y hasta la confiabilidad de un contenido en un espacio multidimensional. Una forma de representación computacional donde la cercanía entre puntos indica similitud semántica.
Hasta aquí, bien. Pero Google no solo vectoriza tus páginas. También te vectoriza a ti.
Sí. A ti. A tu comportamiento, tus intereses, tus patrones, tus ubicaciones frecuentes, tus dispositivos, tus consultas, tu scroll. Todo eso se convierte en un perfil vectorial que Google usa para decidir qué resultados mostrarte, cómo, cuándo y en qué orden.
Este sistema tiene un nombre interno: Nephesh. Y es, en esencia, la base fundacional de los embeddings de usuario dentro del ecosistema Google.
Nephesh es el alma digital de tu comportamiento
Revelado parcialmente en los leaks de 2024 y confirmado ahora por las investigaciones de 1492.vision, Nephesh genera una representación vectorial única de cada usuario a través de todos los productos de Google: Search, Discover, YouTube, Gmail, Maps, Android, Assistant…
Lo que produce no es una ficha. Es una nube de puntos con pesos, direcciones y alineamientos, que Google usa para calcular, entre otras cosas:
- Si eres un usuario típico o atípico para cierto tema.
- Qué probabilidad tienes de hacer clic en un contenido.
- Qué resultados deberían ser “útiles” para ti, aunque no los hayas pedido explícitamente.
- Qué temas están alineados con tus intereses profundos y cuáles son inconsistentes con tu patrón.
Y todo esto ocurre, por supuesto, sin que tú lo veas.
Picasso y VanGogh: el perfilado doble de Discover
Uno de los escenarios donde este sistema brilla (o aterra, depende de tu ánimo) es Google Discover. Para personalizar los contenidos que aparecen allí, Google emplea un enfoque de doble embedding con dos sistemas internos llamados (irónicamente) Picasso y VanGogh.
- Picasso representa tu memoria a largo plazo. Es el sistema que analiza meses de interacción para definir tus pasiones duraderas. Utiliza dos ventanas de tiempo:
- STAT (Short-Term Affinity Time): intereses recientes.
- LTAT (Long-Term Affinity Time): patrones sostenidos.
- VanGogh, por su parte, vive en tu dispositivo. Captura señales en tiempo real:
- El estado de tu celular.
- Tus últimas búsquedas.
- Qué tan profundo hiciste scroll.
- Dónde estás.
- Qué red usas.
El resultado: Discover no te muestra lo que pides. Te muestra lo que eres.
Y lo que eres, para Google, es un vector.
Hulk: el análisis conductual llevado al extremo
El sistema HULK (sí, como el superhéroe) lleva esta lógica aún más lejos. Se trata de una red de embeddings especializados que detectan tus condiciones contextuales:
- ¿Estás en un vehículo?
- ¿Vas caminando?
- ¿Estás subiendo escaleras?
- ¿Estás dormido? (Sí, literal: SLEEPING es uno de los estados detectables).
- ¿Estás en tu casa habitual (SEMANTIC_HOME)? ¿O en tu lugar de trabajo (SEMANTIC_WORK)?
Toda esta información es usada para ajustar en tiempo real los resultados que ves, su orden, su formato y su temporalidad.
Esto rompe de forma definitiva el modelo de “ranking universal”. Cada usuario ve un buscador diferente, en función de su perfil vectorial. Y por tanto, cada contenido compite en un universo de rankings personalizados, no en un top 10 clásico.
¿Qué implica esto para el SEO?
- Que el posicionamiento ya no es un ranking absoluto, sino un ajuste dinámico entre embeddings.
- Que escribir sin pensar en quién leerá es escribir al vacío.
- Que necesitas construir un contenido que resuene con clusters de usuarios, no con consultas individuales.
- Que tu marca necesita ser embebible, es decir, legible semánticamente por los sistemas de vectorización.
Porque si no eres vectorizable, no eres mostrable.
7. Expansión de consultas y scoring contextual: el ranking ya no es lo que era
Hasta hace poco, creíamos que las consultas de búsqueda eran frases que Google trataba de “entender”. Que si alguien escribía “cycling tour France”, el sistema buscaba páginas que coincidieran con esas palabras, o al menos con sus sinónimos más cercanos.
Eso ya no es así.
Lo que ocurre en 2025 es una metamorfosis inmediata y silenciosa de cada consulta. Google no interpreta la frase, la convierte. La reestructura, la vectoriza, la expande semánticamente y la adapta al contexto de cada usuario. Y solo entonces, después de haberla transformado en una red de nodos relacionados, empieza a buscar coincidencias.
Dicho de otra forma: cuando tú haces una consulta, Google no busca lo que tú escribiste. Busca lo que cree que realmente quisiste decir, filtrado por quién eres, dónde estás y cómo sueles buscar.
La query ya no existe como tal
Tomemos la consulta “cycling tour France”. En el instante en que la escribes, el sistema aplica una serie de transformaciones que convierten esa frase en algo más complejo:
- Primero, consolida bigramas como
"cyclingtour"o"francetour". - Luego, expande con variantes relacionadas:
"bike trip","bicycle travel","guided cycling routes","road biking in France". - Finalmente, introduce etiquetas internas como:
iv;p: in-verbatim, coincidencia exacta.iv;d: derivación lingüística, como “cycling” → “bike”, o “France” → “French”.
Este proceso no es lineal. Está gobernado por un motor de expansión de consultas que utiliza aprendizaje automático, reglas contextuales, historial personal y capas de vectorización semántica. Y todo ocurre antes de consultar el índice de resultados.
La frase original desaparece. Lo que queda es una representación abstracta, adaptada al universo del usuario. El ranking se calcula no en función de coincidencias, sino de afinidad semántica en un espacio multidimensional.
Geolocalización y traducción on-the-fly
¿La búsqueda contiene elementos locales? Entonces el sistema activa su módulo de interpretación geográfica.
Por ejemplo, ante la consulta “dentista en Ciudad de México zona Roma”, el sistema puede:
- Detectar la categoría semántica del servicio:
geo:health:dental_clinic - Identificar el área por códigos de zona (como
geo;CDMX-06700) - Expandir sinónimos y formas alternas:
"odontólogo","consultorio dental","clínica dental Roma Norte" - Traducir internamente términos si detecta un idioma diferente al de la ubicación
Este mecanismo asegura que la consulta sea entendida como intención y no como texto literal. Y lo hace incluso si tú no lo notas. En muchos casos, puede traducir términos automáticamente para mostrarte resultados locales, aunque tu interfaz esté en otro idioma.
El resultado: dos usuarios con la misma consulta escrita ven resultados diferentes, porque la arquitectura semántica que se activa es distinta.
El scoring en tiempo real: cada palabra, una batalla
Ahora viene el punto más invisible y determinante: cada término de tu consulta recibe un puntaje individual para cada URL evaluada. Un score que va del 0 al 10, calculado en tiempo real, y que no depende solo del contenido, sino del contexto, la intención, la ubicación y el perfil del usuario.
Este mecanismo fue documentado en los informes filtrados y ahora validado en las investigaciones actuales. Los factores que influyen en el scoring incluyen:
- virtualTf: frecuencia virtual del término en la URL, ajustada semánticamente
- idf: rareza estadística del término en el corpus completo
- salience: relevancia contextual del término dentro del documento
- bonus por título: los términos que aparecen en el title tienen puntuación extra
- entidades nombradas: si el término es una entidad validada, se otorga el puntaje máximo
¿La trampa? El scoring es pairwise. Es decir, no hay un valor absoluto para cada término. Una misma palabra puede recibir puntuaciones distintas en la misma URL según con qué otras palabras se combina en la consulta, qué intención se detecta, y qué contexto tiene el usuario.
Por ejemplo, “screwdriver” puede valer 9 si estás buscando comprar herramientas eléctricas, pero apenas 2 si la intención es leer un blog sobre reparaciones caseras.
¿Qué significa esto para el SEO?
- Olvídate del keyword stuffing y del match exacto. Las palabras ya no se interpretan aisladamente, sino dentro de un vector semántico expandido.
- Escribir para una sola intención es una estrategia débil. Necesitas generar contenido que funcione en múltiples contextos, variantes, y derivaciones semánticas.
- El title importa, pero no es suficiente. La saliencia editorial —es decir, cómo el texto construye su significado— influye más que las coincidencias sueltas.
- Tus contenidos deben estar optimizados para entidades, no para keywords. Lo que tiene mayor puntaje no es lo más repetido, sino lo que mejor encaja dentro de la lógica contextual de la búsqueda.
- Y sobre todo: el SEO ya no es una competencia por “rankear” una palabra. Es una competencia por alinear tu contenido con las múltiples formas en que esa palabra puede ser entendida.
8. El buscador ya no busca
Hay una escena silenciosa que se repite todos los días en agencias, equipos internos y escritorios de freelancers: alguien pregunta si el contenido “está optimizado para Google”, como si eso pudiera seguir significando lo mismo que hace cinco años.
Pero después de leer los documentos de RESONEO y 1492.vision (y sobre todo después de ver lo que Google ha desplegado en silencio), la única respuesta posible es esta:
Google ya no es un buscador. Es una inteligencia distribuida.
Una máquina de interpretación contextual que:
- No responde keywords, responde a perfiles.
- No premia textos, premia entidades.
- No rankea resultados, calcula afinidades.
Todo lo que durante años fue considerado “buen SEO” —estructura, keywords, H1, velocidad, enlaces— sigue importando. Pero ya no es suficiente. Porque no responde a las nuevas reglas del juego, que ya no son reglas, sino procesos adaptativos invisibles.
Lo técnico ya no es el techo, es el piso
Sin un sitio rastreable, rápido y bien indexado no entras al juego. Pero si lo único que haces es cumplir con el Mínimo SEO Viable, te conviertes en el equivalente SEO de un producto genérico en un anaquel de supermercado: visible, sí… pero irrelevante.
La pregunta ya no es “¿estoy optimizado para Google?”, sino:
- ¿Soy una entidad validada en su grafo?
- ¿Mi contenido es interpretado como parte de un universo coherente?
- ¿Mi presencia digital se alinea con los embeddings de los usuarios a los que quiero alcanzar?
- ¿Mi propuesta semántica es consistente, contextual, útil… y vectorizable?
Si la respuesta a cualquiera de esas preguntas es “no”, entonces da igual cuántas veces repitas la palabra clave. Porque Google no va a recordarte. Y si no te recuerda, no te cita. Y si no te cita, no existes.
El futuro del SEO no es optimizar. Es significar.
En esta nueva arquitectura, lo que se posiciona no es una página. Es una presencia semántica. Una entidad coherente, citada por otras, referenciada en distintos formatos, y alineada con las intenciones reales de usuarios reales en situaciones reales.
Por eso el contenido útil ya no es suficiente. Porque hay millones de contenidos útiles. Lo que importa ahora es el contenido reconocible, citable, relacionable, ubicable dentro de un grafo.
La visibilidad ya no se gana diciendo algo importante, sino siendo parte del sistema que decide qué es importante.
Y eso, amigo mío, no se optimiza. Se construye.
Posdata para SEOs con memoria
Sí, todavía puedes hacer títulos, escribir metadescripciones, mejorar tu WPO y ganarte un par de enlaces. Eso está bien. Pero si no estás trabajando para convertirte en una entidad coherente y reconocible dentro del ecosistema Google, entonces estás apostando todo tu futuro SEO a un sistema que Google está dejando atrás.
Google ya no busca. Recuerda.
Y solo recuerda aquello que ha sido citado, embebido, verificado y alineado.
Todo lo demás se olvida. O peor aún: nunca existió.


