
El contenido duplicado en Internet es un problema tan antiguo como la propia Web. Una facilidad absoluta para copiar (o incluso saquear) contenidos en el espacio web, multiplicada por constelaciones de soluciones técnicas no optimizadas, como los parámetros de seguimiento o los errores humanos, genera miles de millones de páginas duplicadas al lado de las existentes.
Esto hace que sea una de las tareas prioritarias para la gestión de los motores de búsqueda. Y como siempre, lo que Google quiere afecta de forma inevitable al trabajo de los expertos en SEO. En este artículo, repasaremos los diferentes tipos de contenido duplicado, los algoritmos de detección y las particularidades del tratamiento del contenido duplicado por Google, los métodos y las herramientas para identificarlo y, por supuesto, para corregirlo.
¿Qué es el contenido duplicado?
Empecemos por la definición de contenido duplicado y para eso vamos a utilizar la explicación oficial de Google:
Por contenido duplicado se entiende, en general, grandes bloques de contenido, ya sea dentro de un mismo dominio o repartidos en varios dominios, que son idénticos en el mismo idioma o muy similares. En la mayoría de los casos, este contenido no es originalmente engañoso.
A partir de esta definición, podemos elaborar fácilmente algunas tipologías de contenidos duplicados.
Dependiendo de la ubicación del contenido duplicado, podemos tener :
- Duplicaciones internas (la página duplicada está dentro del mismo sitio).
- Duplicaciones externas (la página duplicada está en otro sitio, en otro nombre de dominio).
Según el grado de similitud, se distingue entre
- Duplicaciones completas (“exact duplicate”).
- Duplicaciones parciales (“near duplicate”).
En función de la naturaleza de las duplicaciones:
- Duplicaciones voluntarias y engañosas.
- Duplicaciones involuntarias o accidentales.
A estos tres tipos de duplicidades, se puede añadir un cuarto tipo:
- Duplicaciones técnicas.
- Duplicaciones semánticas (páginas que utilizan diferentes palabras y frases, pero que al final hablan exactamente de lo mismo sin aportar valor).
Según el tipo de duplicación, la gravedad, la reacción y los métodos de corrección no serán los mismos. Esto es lo que veremos más adelante.
¿Cómo Google identifica el contenido duplicado?
En lo que respecta a los motores de búsqueda, la comparación de documentos web para identificar duplicados es siempre una cuestión de compromiso entre la precisión y los recursos de la máquina consumidos.
Muchos de los algoritmos que tenemos a nuestra disposición y que podemos utilizar sin problemas para nuestros proyectos, se revelan rápidamente ineficaces a la escala de la Web cuando se trata de comparar millones, incluso miles de millones de páginas web.
Para identificar si un sitio contiene contenido duplicado, Google utiliza varios niveles, métodos y algoritmos de análisis.
- El nivel básico de análisis consiste en dejar que el Googlebot pase en la página de interés y detectar si contiene un contenido diferente. Este enfoque es tan preciso como costoso en recursos, ya que requiere que Google rastree todas las páginas, muchas de las cuales pueden estar duplicadas y, por tanto, ser innecesarias.
- El otro nivel de análisis encuentra su realización en el concepto del rastreo predictivo. Basándose en el contenido duplicado descubierto en el nivel 1, Google intenta identificar patrones de URL comunes y limitar el rastreo de estas páginas asumiendo que existe una alta probabilidad de que estén duplicadas.
Por ejemplo, si el motor identifica que las versiones imprimibles resultan ser regularmente copias de páginas existentes, puede limitar muchísimo su exploración debido a la falta de valor añadido que aportan estas páginas. Todo esto se basa en los patterns (patrones recurrentes) de las URLs detectadas.
Centrémonos en el primer nivel de análisis que, como puedes imaginar, es mucho más complejo que el formulado en el punto anterior.
Antes de ser indexada, cada página web pasa por una etapa de verificación de duplicación. La lógica de Google es clara: no hay razón para malgastar recursos del motor analizando el contenido de la página si ya se ha publicado antes.
Pero, ¿cómo puede saber el motor si la página está duplicada sin haberla analizada?
Antes de proceder a un análisis en profundidad de la página, los principales motores de búsqueda, incluido Google, realizan una operación de hashing, es decir, codifican el contenido en una secuencia de caracteres (números o números y dígitos).
Así, cada texto de la página está representado por un conjunto de bloques de construcción denominados shingles – secuencias de un número fijo de palabras, que se obtienen arrastrando una palabra hacia la derecha. Después, los shingles se desmenuzan para constituir un hash de síntesis que refleje el texto.
Por ejemplo, para la frase “Charles Darwin revolucionó la biología con sus teorías de la evolución”, el motor identificará y codificará (hash) 6 shingles de tamaño 6 :
- charles darwin revolucionó la biología
- darwin revolucionó la biología con
- a revolucionó la biología con sus
- revolucionó la biología con sus teorías
- la biología con sus teorías de
- biología con sus teorías de la evolución
Utilizar los shingles como elemento de hash y no las palabras por separado no sólo ahorra mucho espacio de almacenamiento (cada palabra se duplica varias veces), sino que también tiene en cuenta el orden de las palabras.
El hash final es un modo de visualización de la página mucho más compacta también llamado firma o huella digital de la página.
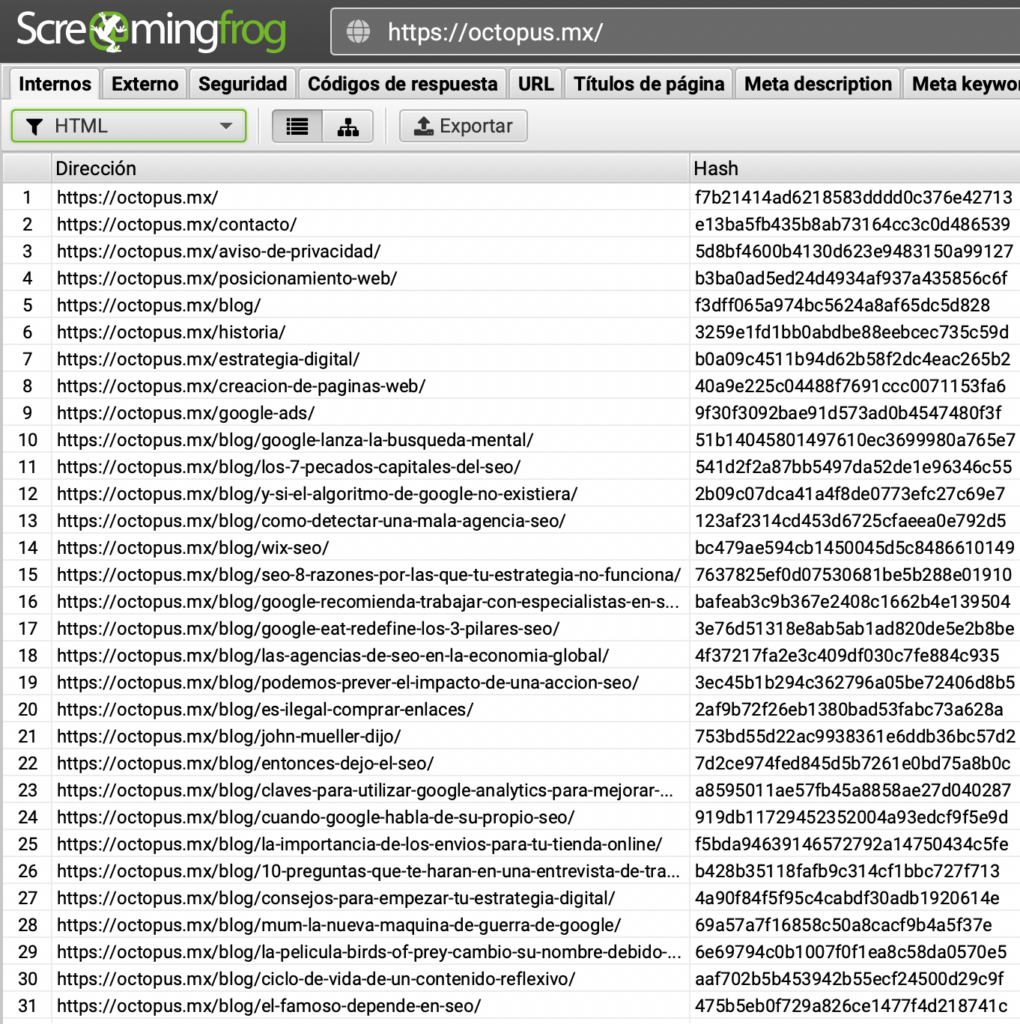
Hashing del contenido de las páginas en Screaming Frog SEO Spider.
En lugar de comparar textos enteros, la comparación de estas pequeñas cadenas de caracteres ha demostrado ser mucho más ligera en términos de almacenamiento de texto y cálculos de comparación, sin dejar de ser igual de eficiente.
Existen varios algoritmos de hashing, los más conocidos son MinHash y SimHash, que han encontrado su camino en las herramientas de rastreo más populares que estamos acostumbrados a utilizar.
- El algoritmo MinHash. Preciso y eficiente, pero es consumidor en cálculos en muy grandes cantidades. Este algoritmo es utilizado por Google para diversificar y personalizar los resultados en Google News, pero también en Screaming Frog.
- El algoritmo SimHash. Este algoritmo, mucho más rápido, es utilizado por Google para calcular la similitud entre documentos web e identificar duplicados no exactos, así como en el crawler SaaS como OnCrawl.
Cabe destacar que Google rechaza del análisis los elementos transversales, visibles en todo el sitio, como header, los menus, las sidebars o el pie de página (footer), y se centra en el contenido propio de cada página.
Una vez que el motor ha calculado la similitud de las firmas de las páginas, divide los documentos idénticos y similares en clusters según su similitud. Para cada cluster, Google seleccionará un único documento para mostrarlo en sus resultados de búsqueda (“leader page”). Este paso se llama canonización y es similar a la selección natural.
En el podcast Search Off the Record, del 4 de noviembre 2020, Gary Illyes de Google habló sobre el hecho de que en la etapa de canonización, Google utiliza alrededor de 20 señales incluyendo :
- El Pagerank (la popularidad de la página aumenta sus posibilidades de ser seleccionada),
- El Protocolo (HTTPS o HTTP),
- El Sitemap XML (una página es más importante si está presente en el sitemap),
- Una posible redirección (la página redirigida estará muy devaluada),
- La etiqueta rel=canonical (una señal fuerte, ya que el atributo está configurado específicamente por el webmaster para este propósito).
A cada señal se le asigna un peso mediante algoritmos de aprendizaje automático. Si se modifica el contenido de una página, su huella cambia y pasa a otro cluster de documentos similares y compite con los documentos del nuevo cluster.
Ya veremos este paso del clustering en un próximo podcast sobre el tratamiento de imágenes similares por parte de Google, cuando se agrupan todas las imágenes iguales de un iPhone y el motor selecciona una sola para mostrarla en Google Imágenes.
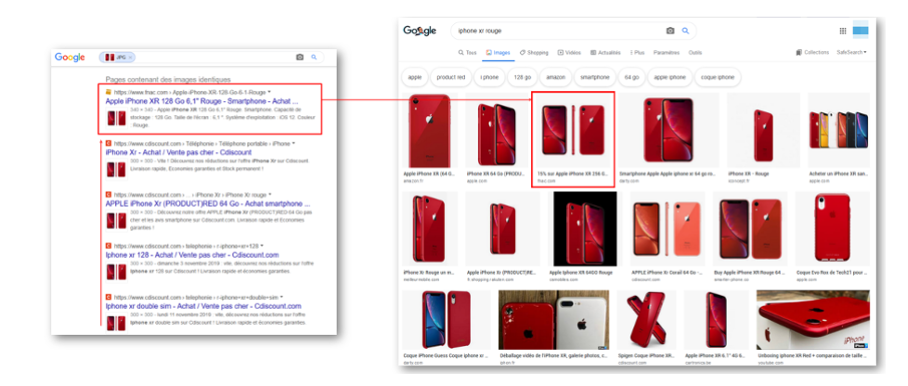
En realidad, un solo documento por cluster no es un dogma. El número de páginas que pueden “salir del clúster” depende en gran medida de la popularidad del tema asociado al cluster. Cuanto más raro es el tema, más documentos pueden posicionarse porque Google está obligado a llenar las primeras páginas de sus resultados de búsqueda.
¿Cómo se produce el contenido duplicado?
Los motivos de la aparición de contenido duplicado son tan diversos como creativos, pero todos ellos pueden dividirse en dos grandes grupos: técnico o editorial.
Defectos técnicos en el CMS
Por ejemplo, el CMS Vbulletin utilizado para crear foros añade por defecto los IDs únicos de la sesión del usuario a las URLs de sus páginas. Así, aparecen tantas variantes de la página como visitantes tenga el foro. Muchos CMS permiten que coexistan en el mismo sitio tanto las URL técnicas como las reescritas. Por ejemplo, /node/* en Drupal, /demandware* en Salesforce, etc.
Parámetros de tracking
Los parámetros de seguimiento como utm, gclid, fbclid, xtor introducidos con un signo de interrogación (?) o un ampersand (&) crean copias de la página a la que se adjuntan.
Estructura de árbol dinámico
Por ejemplo, los sitios de comercio electrónico suelen seguir construyendo las rutas de las URL en función de la trayectoria del usuario, lo que genera diferentes URL para acceder a la misma página: /smartphones/iphone-12-black.html /smartphones/apple/iphone-12-black.html /smartphones/smartphones-negro/iphone-12-negro.html /smartphones/smartphones-tactile/iphone-12-black.html Otro caso: el orden de los elementos que no es fijo: /tenis/mujer/aire-max.html /mujer/tenis/aire-max.html
Versiones alternativas de las páginas
Versión móvil dedicada, AMP, imprimible, PDF – por defecto, debido a la falta de SEO, todos estos tipos de páginas son completos duplicados.
Protocolo, www y slashs (/)
Las páginas disponibles en HTTPS y HTTP, www y sin www, con un slash al final o sin ella también son duplicadas.
Problemas editoriales
Uso de contenidos publicados en otros lugares
Publicación de notas de prensa en su estado original, sin ningún tipo de reprocesamiento. Uso de las descripciones de los productos de los proveedores.
Mostrar el mismo contenido en varias páginas
Mostrar el mismo texto en el footer en todas las páginas del sitio. Los textos sobre las categorías de comercio electrónico se incluyen automáticamente en las páginas paginadas.
Creación de páginas muy similares
Creación de páginas locales por ciudad con la misma descripción de servicios ofrecidos donde el único elemento diferenciador será el nombre de la ciudad.
Distribución de los contenidos en otros sitios
Sindicación en agregadores de noticias Republicando las entradas del blog en todos los sitios.
Plagio y robo de contenido
Uso ilícito de los contenidos por parte de terceros.
¿Cómo identificar el contenido duplicado?
Existen muchos métodos y herramientas, tanto gratuitos como de pago, para identificar el contenido duplicado.
Operadores de búsqueda de Google
Esta es probablemente la solución más sencilla y eficaz, ya que no requiere el uso de herramientas especializadas: se toma una secuencia de 6 a 10 palabras del texto, se encierra entre comillas y se introduce en el cuadro de búsqueda de Google. Si nuestro sitio no está posicionado en el primer lugar, Google no nos considera como una fuente degrada su visibilidad.
Las razones pueden ser muy variadas y deben ser investigadas:
- El texto que se utilizó no era original, sino que se copió de otra fuente.
- Nuestro texto es original, pero ha sido tomado por otro sitio (sin o con mala voluntad).
- Hay problemas con la accesibilidad de nuestra página, lo que hace que Google prefiera elegir una página más estable.
- Nuestro sitio carece de mucha autoridad y es el más fuerte que es seleccionado por Google.
Al asociar el texto entre comillas con el operador “site:”, podemos identificar las duplicaciones internas:

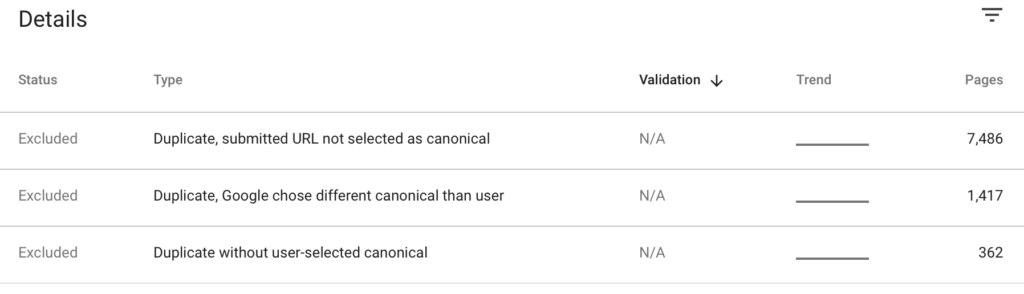
Google Search Console
El informe de cobertura de Search Console de las últimas actualizaciones muestra los detalles de las páginas duplicadas, incluidos los posibles errores en el uso del atributo rel=canonical:
Screaming Frog SEO Spider
Por defecto, la herramienta de rastreo Screaming Frog SEO busca duplicados absolutos, lo que a menudo está lejos de ser preciso, ya que el más mínimo cambio en la página, en el menú por ejemplo, hace que no se marque como duplicado. Otra particularidad: para detectar duplicados exactos Screaming Frog analizará no las palabras, sino todo el código fuente HTML de las páginas. Por lo tanto, es muy sensible a los cambios en las etiquetas HTML, atributos, clases o divs, incluso si el contenido real permanece inalterado.
Para que la herramienta pueda detectar duplicados parciales (con el algoritmo MinHash), es necesario activar esta opción en: Configuración > Contenido > Duplicados.
Screaming Frog permite especificar la zona de contenido para ignorar el mega menú por ejemplo (Contenido > Área) y el límite en el que la página se considerará un duplicado. A diferencia de la búsqueda de duplicados exactos, esta vez la herramienta comparará el contenido textual sin prestar atención a como está puesto en la página.
Una sugerencia, los valores de similitud no son visibles por defecto y requieren el lanzamiento del análisis de rastreo (Analysís de rastreo > Empezar).
Copyscape
Lanzado en 2004, Copyscape es un servicio de detección de plagio en línea que comprueba si aparecen contenidos de texto similares en otros lugares de la web.
A diferencia de la comprobación de los resultados de Google, Copyscape no nos dirá si está reconocido como fuente o no. Sin embargo, los proveedores de contenidos de pago lo utilizan ampliamente para detectar casos de uso ilegal, incluso si el contenido ha sido reescrito. Copyscape permite configurar alertas para ser notificado de nuevos usos del contenido.
Siteliner
Si tenemos un sitio pequeño y queremos comprobar rápidamente si hay duplicación interna, Siteliner desarrollado por el equipo de Copyscape puede ser útil. En la versión gratuita, podemos analizar hasta 250 páginas. La herramienta busca tanto los duplicados exactos como los parciales, pero también tiene en cuenta los elementos transversales del sitio.
Killduplicate
Killduplicate permite vigilar el plagio o el robo de contenido. Directamente desde la interfaz, puedes actuar ante los casos de uso no autorizado de tus contenidos poniéndote en contacto con el propietario del sitio o presentando una reclamación DMCA ante Google.
¿Cómo evitar o corregir el contenido duplicado?
Cuando se trata de prevenir o corregir cualquier tipo de problema en SEO, siempre es prudente tratar de corregir la causa raíz del problema en lugar de ocultar los síntomas. Y el contenido duplicado no es una excepción.
Por ejemplo:
- Para prevenir el problema del contenido duplicado debido a los parámetros de seguimiento, hay que considerar la posibilidad de introducirlos con un hash o gato (#) en lugar de un signo de interrogación o un ampersand (&). Las URL con # no son rastreadas por el robot de Google y no se crean copias de las páginas.
- Para evitar el problema de las URL dinámicas, hay que establecer una estructura de URL reescrita con un orden fijo. No es casualidad que los mayores actores del comercio electrónico establezcan URLs planas para sus páginas de productos que no contienen nombres de categorías.
En caso de que esto no sea posible (demasiado costoso, demasiado tiempo, CMS obsoleto, etc.), diferentes soluciones técnicas pueden corregir o reducir un posible impacto negativo de los casos de duplicación.
Para eso tenemos:
- Redirecciones 301 – una solución radical, pero muy eficaz para los casos en los que no es necesario mantener juntas la página original y la duplicada.
- Atributo rel canonical – una solución de apoyo que se puede utilizar en los casos en que el usuario necesita poder acceder tanto a la página de origen como a la página duplicada, por ejemplo una página AMP o una página con la variante de un producto.
Al sindicar contenidos en otros sitios, éstos suelen sugerir que se establezca el atributo rel canonical (por ejemplo Yahoo News! y Medium lo permiten).
– La directiva “noindex, nofollow” es la solución definitiva para desindexar el contenido duplicado no deseado.
¿Google penaliza a los sitios por contenido duplicado?
La posición de Google sobre la penalización del contenido duplicado es similar a la de cualquier otro tipo de acción en el sitio. Los contenidos duplicados, que a menudo se crean de forma involuntaria y representan aproximadamente un tercio de todas las páginas en Internet, no son sancionables en sí mismos.
Al mismo tiempo, como en el caso de los enlaces fraudulentos o el cloaking, cualquier forma intencionada de engañar a los usuarios o de manipular los resultados de búsqueda es sancionable:
“En consecuencia, la clasificación del sitio puede verse afectada, o el sitio puede ser eliminado permanentemente del índice de Google, en cuyo caso dejará de aparecer en los resultados de búsqueda”
(Fuente: Google).
Los últimos estudios de los resultados de búsqueda de Google lo confirman.
La propagación de las “Preguntas relacionadas” en las SERP de Google ha dado nacimiento a un movimiento hasta ahora inédito de creación de sitios compuestos enteramente por preguntas y respuestas recolectadas automáticamente. Estos sitios, que no producen ningún tipo de contenido, republican enormes cantidades de respuestas ya hechas desde otros sitios web.
Ejemplo 1 :
- lisbdnet.com – lanzado a finales de 2021, en marzo de 2022 superó los 9 millones de visitas orgánicas (Semrush).
- el 25 de abril de 2022 la visibilidad del sitio se derrumba.
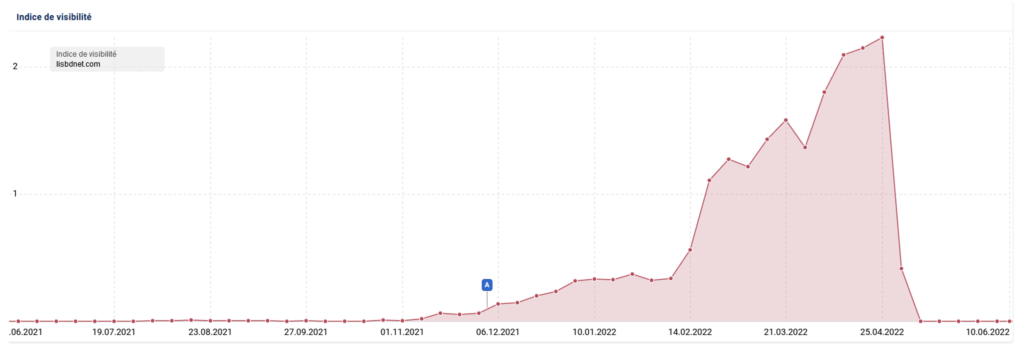
Indice de visibilidad de Lisbdnet.com (fuente: Sistrix)
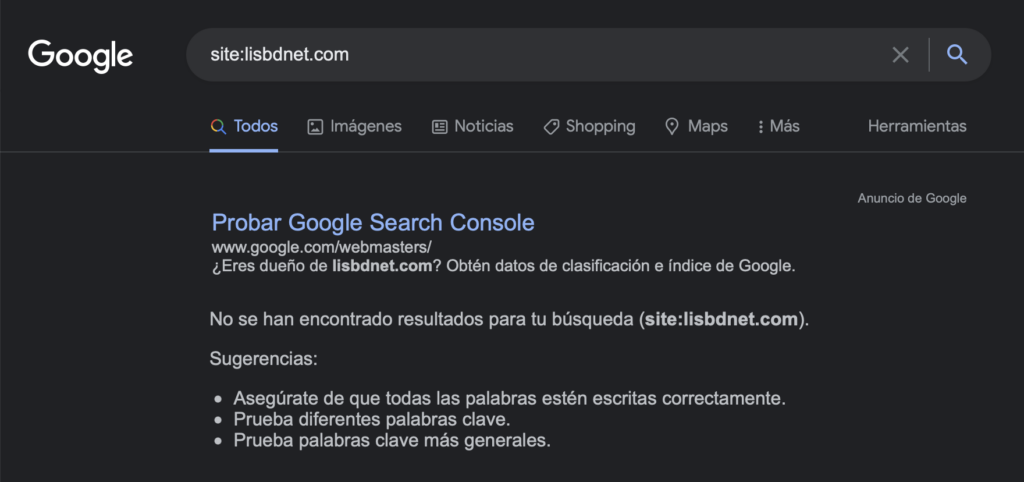
En el momento de grabar el podcast, todo el sitio está desindexado.
- Red de sitios similares con faq-ans.com a la cabeza (1,5 millones de visitas orgánicas al mes).
- El 23 de mayo de 2022, todos los sitios de la red fueron desindexados en Google.
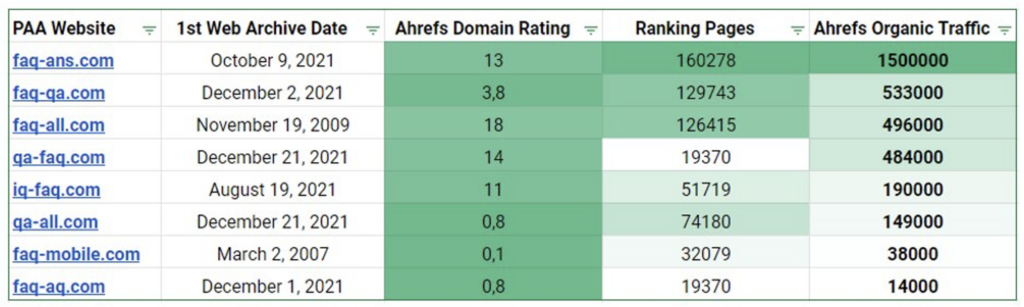
Estimación del tráfico orgánico de los sitios de la red a partir del 11 de mayo de 2022.
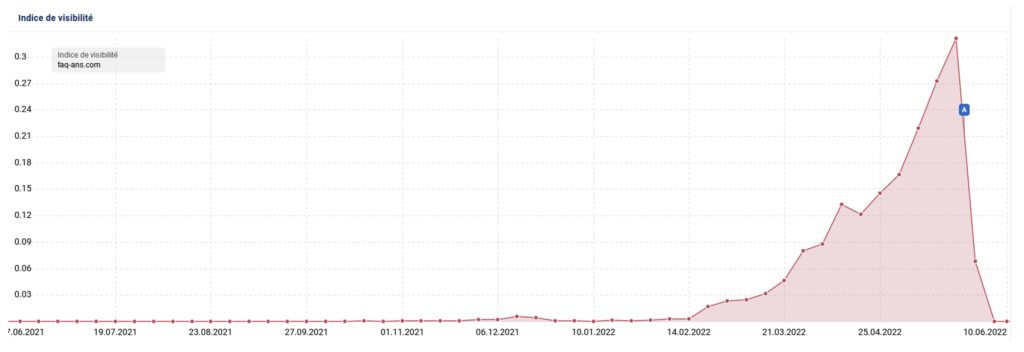
Curva de visibilidad de Faq-ans.com (fuente: Sistrix)
No sabemos exactamente qué tipo de sanciones se aplicaron, si manuales o algorítmicas. Sin embargo, lo que está claro y es cierto es que fueron penalizados por desplegar deliberadamente contenido duplicado e intentar manipular el algoritmo.
Conclusión
El contenido duplicado es uno de los temas más importantes al que históricamente se enfrenta cualquier consultor SEO y los de motores de búsqueda. Dado que la web crece exponencialmente cada año, el problema no hace más que aumentar.
Desde el punto de vista de los motores de búsqueda, los contenidos duplicados no aportan valor, desperdician muchos recursos en detrimento del rastreo de las páginas realmente útiles y ocupan espacio de almacenamiento, enorme a escala de la web.
Para los propietarios de sitios web y los SEO, también hay mucho en juego: el contenido duplicado desvía Googlebot de las páginas prioritarias, perturba la pertinencia de los resultados al conseguir que los duplicados se posicionen, diluye la valiosa popularidad de la que podrían haberse beneficiado las páginas importantes.
Es fundamental entender cómo Google identifica y trata el contenido duplicado, incluyendo los algoritmos de hashing, shingling y clustering. Y por supuesto, hay que tomar en cuenta las posibles penalizaciones que puede imponer Google por el mal uso del contenido duplicado.


