
Google acaba de publicar un paper académico sobre cómo generar datos sintéticos para entrenar agentes de IA en búsqueda profunda. No es un estudio sobre SEO. Es ingeniería de sistemas. Pero hay una decisión de diseño enterrada en la metodología que vale la pena entender.
Cuando los investigadores configuraron el sistema para entrenar a sus agentes, decidieron que cada vez que el agente ejecutara una búsqueda, solo extraería información de los tres primeros resultados de Google.
No del top 10. No de toda la primera página. De los tres primeros.
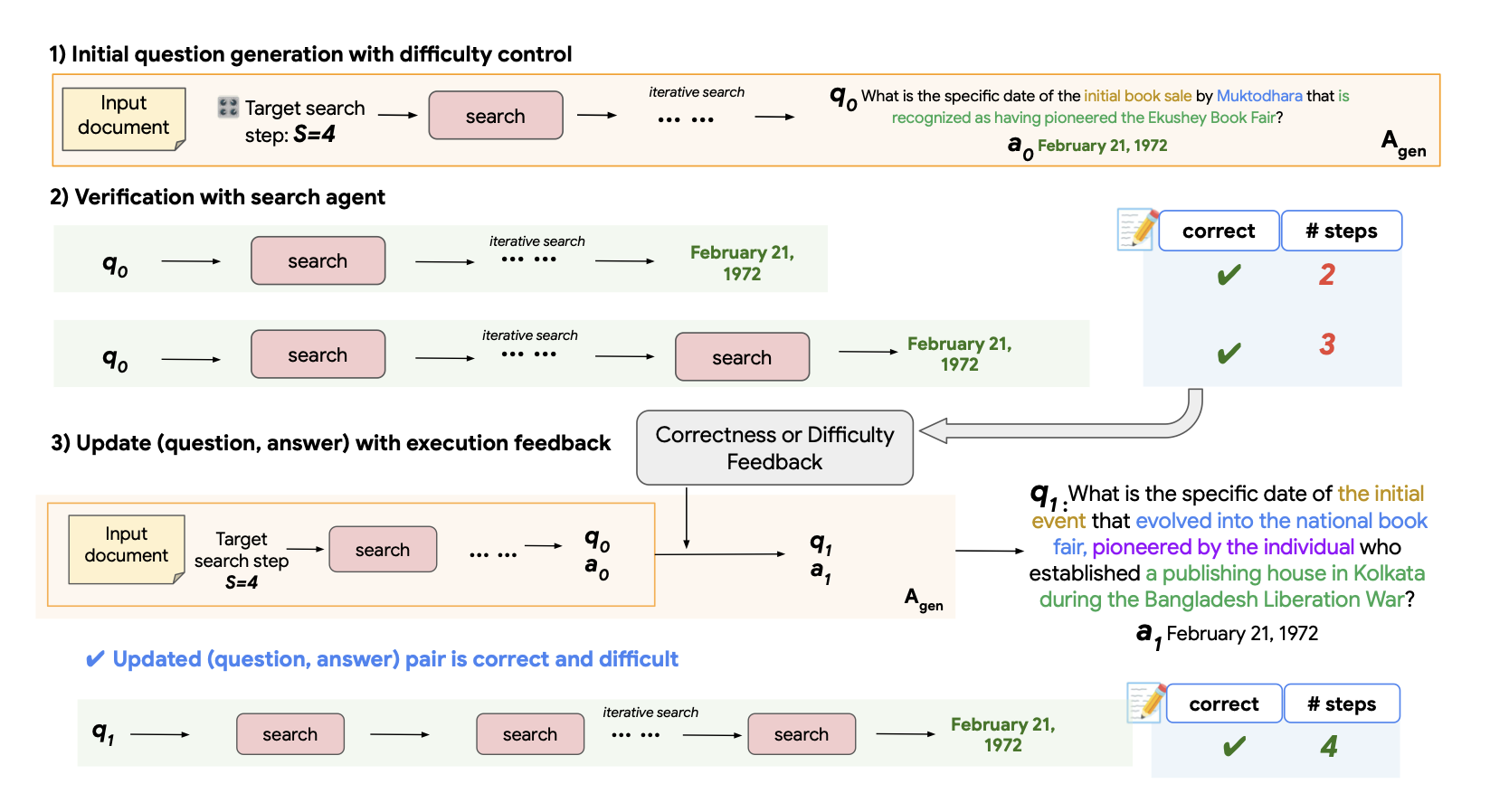
El estudio SAGE, publicado el 26 de enero de 2026, diseñó un sistema de entrenamiento donde el agente trabaja con el top 3, y funciona extraordinariamente bien. Esa decisión revela algo sobre dónde Google considera que está concentrada la información útil cuando un sistema necesita resolver búsquedas complejas.
El problema que resuelve
Los datasets existentes para entrenar agentes de búsqueda son demasiado simples. Musique requiere en promedio 2.7 búsquedas por pregunta. HotpotQA solo 2.1 búsquedas. Natural Questions apenas 1.3 búsquedas. Ninguno exige más de cuatro pasos de razonamiento.
Esto crea una brecha entre el entrenamiento y la realidad. Las tareas complejas de búsqueda profunda exigen cadenas de razonamiento largas, múltiples búsquedas encadenadas, capacidad de síntesis. Los datasets no lo reflejaban.
La solución de Google es un sistema de doble agente. El primero genera preguntas difíciles que requieren múltiples pasos. El segundo intenta resolverlas ejecutando búsquedas reales. Si el segundo agente resuelve la pregunta demasiado rápido, el sistema usa ese feedback para hacer la pregunta más difícil. Iteran hasta que la pregunta es genuinamente compleja.
SAGE significa “Steerable Agentic Data Generation for Deep Search with Execution Feedback”. Es ingeniería elegante. Pero lo interesante no es la arquitectura. Es lo que reveló sobre cómo los agentes buscan información cuando necesitan resolver problemas no triviales.
Los cuatro atajos
Durante el proceso de generar preguntas cada vez más difíciles, los investigadores identificaron cuatro patrones que hacían innecesaria la búsqueda profunda. Los llamaron “atajos” porque permitían al agente resolver preguntas complejas en menos pasos de los planeados.
| Atajo | Incidencia | Qué sucede |
| Co-localización de información | 35% | Múltiples datos necesarios están en el mismo documento – el agente resuelve en un salto lo que debía tomar varios |
| Colapso multi-query | 21% | Una sola búsqueda recupera información de varios documentos simultáneamente – la cadena de búsquedas se comprime |
| Complejidad superficial | 13% | La pregunta parece difícil pero el buscador salta directo a la respuesta sin pasos intermedios |
| Pregunta sobre-especificada | 31% | Tanto detalle que la respuesta es obvia desde la primera búsqueda |
Estos atajos no son errores. Son la realidad operativa de cómo funcionan los motores de búsqueda cuando interactúan con contenido estructurado.
La co-localización es la más reveladora. Cuando múltiples piezas de información necesarias para resolver una pregunta están en el mismo documento, el agente no necesita saltar a otro sitio. Encuentra todo en un solo lugar y termina ahí. El 35% de los casos donde el sistema falló en generar preguntas suficientemente difíciles fue porque un documento era demasiado completo.
Demasiado completo. Piensa en eso.
El colapso multi-query muestra algo similar. Una sola búsqueda bien formulada puede recuperar suficiente información de diferentes documentos para resolver varias partes del problema a la vez. Lo que debía ser una cadena de cuatro búsquedas se resuelve en una porque los resultados son suficientemente informativos.
La complejidad superficial y las preguntas sobre-especificadas apuntan a lo mismo: cuando tus datos son suficientemente precisos (fechas exactas, nombres completos, cálculos específicos), eliminas la necesidad de que el agente siga buscando.
Por qué eligieron tres
Los investigadores usaron la API Serper para extraer resultados de búsqueda de Google durante los experimentos. Y aquí hay algo curioso: Google demandó a SerpAPI en diciembre de 2025 por scraping no autorizado de sus resultados de búsqueda. La acusación es dura – “evasión deliberada de sistemas de protección”, uso del DMCA para clasificar el scraping como “circumvention”. Un mes después, Google publica este paper donde sus propios investigadores usan Serper, otro servicio que hace exactamente lo mismo: extraer resultados de búsqueda sin una API oficial. La contradicción no invalida los hallazgos, pero expone algo sobre cómo Google trata sus propios datos dependiendo de quién los necesite.
En cualquier caso, configuraron el sistema para que el agente, cada vez que ejecutara una query, solo consultara los tres primeros resultados. Esto no es una limitación técnica. Es una decisión. Google pudo haber elegido el top 5, el top 10, toda la primera página. Eligieron tres.
Y esa decisión funcionó. Los agentes entrenados con este método lograron mejoras de 27% en evaluaciones dentro del dominio de entrenamiento y hasta 23% en datasets completamente fuera del dominio. Más revelador: estos agentes se transfieren efectivamente a Google Search en tiempo de inferencia sin entrenamiento adicional.
Si Google entrena sistemas para trabajar con solo tres resultados por query, y esos sistemas funcionan bien cuando se enfrentan a Google Search en producción, entonces esos tres primeros resultados contienen lo que el sistema necesita para resolver búsquedas complejas.
No es que sea imposible usar más resultados. Es que no parece ser necesario.
Patrones que emergieron
Los cuatro atajos son patrones que emergieron durante el entrenamiento, no recomendaciones de optimización. Pero describen condiciones estructurales reales: páginas que consolidan información relacionada, contenido suficientemente específico en sus datos, arquitectura que permite resolver múltiples sub-preguntas sin obligar a buscar en otros sitios.
Cuando un documento cumple estas condiciones, se convierte en el punto final de la búsqueda. El agente deja de buscar porque ya encontró lo que necesitaba.
Y los agentes que Google está entrenando usan búsqueda clásica como herramienta. No hay un canal paralelo de “optimización para IA”. Hay búsqueda. La misma que siempre.
Lo que no cambia
Rankear en el top 3 de la búsqueda clásica sigue siendo el objetivo. Crear contenido que responda completamente a su pregunta central sin obligar a buscar en otros sitios sigue siendo útil. Usar enlazado interno para que otras páginas relevantes también rankeen en el top 3 sigue siendo arquitectura, no decoración.
La diferencia es que ahora hay evidencia empírica de cómo los investigadores de Google están entrenando sistemas de búsqueda profunda y qué decisiones de diseño están tomando.
Eligieron el top 3. El resto es ruido.


