
¿Crees que sabes qué es el rastreo? Ese acto tan simple en el que Googlebot, como una araña hiperactiva, recorre internet recogiendo URLs y chequeando tu sitio como si fuera un casero demasiado metiche. Pero, espera un momento. El rastreo no es solo descargar tu página de inicio y dar el día por terminado. No. Es un baile de solicitudes, redireccionamientos y parámetros caóticos, todo para asegurarse de que tu sitio tenga una oportunidad de brillar. Vamos a analizar las peripecias de Googlebot y descubrir por qué tus logs de servidor parecen haber sido atacados por un pulpo con sobredosis de cafeína.
¿Qué es realmente el rastreo (y por qué no es tan simple como parece)?
Vamos a aclararlo: el rastreo es el proceso en el que Googlebot encuentra, revisita y descarga páginas web. Suena fácil, ¿no? Pues no. Es más como tratar de guiar gatos con una nota adhesiva que dice “trae HTML”. Googlebot toma tu URL, envía una solicitud HTTP, y luego enfrenta lo que sea que tu servidor decida arrojarle: errores 404, redirecciones o el temido “el sitio tardó demasiado en responder”.
Y no creas ni por un segundo que se queda solo con el HTML. No, señor. Googlebot no solo está descargando tu bonita página de inicio; también anda buscando cada pequeño recurso que tu página necesita para funcionar: JavaScript, CSS, imágenes, videos, y quién sabe qué más. Cada uno de estos recursos consume un poco de tu presupuesto de rastreo (Crawl Budget), y sí, tienes un presupuesto. Googlebot no tiene un ancho de banda infinito, por si no lo sabías.
Por qué el Crawl Budget no es tu cerdito secreto
Ah, el famoso Crawl Budget (presupuesto de rastreo). Ese límite mágico y misterioso que Google no define claramente pero que definitivamente te hará arrepentirte si lo desperdicias. Cada recurso que Googlebot descarga —desde tu archivo CSS principal hasta ese video que reproduce automáticamente y nadie pidió— cuenta para este presupuesto mítico. ¿Quieres acabarlo tan rápido como un adolescente con una tarjeta de crédito? Aquí te dejo unos consejos:
1. Añade redirecciones innecesarias a cada recurso.
2. Usa parámetros fetched data en todos tus archivos estáticos.
3. Aloja todos tus archivos en el mismo dominio y luego pregúntate por qué tus páginas principales no se rastrean.
Consejo: si tu página tiene una cadena de dependencias más larga que tu lista de deseos navideña, Googlebot necesitará un descanso de café a mitad de camino. Y adivina qué: ese retraso no augura nada bueno para tu ranking en las búsquedas.
Googlebot no quiere tus excusas, solo tus recursos
Imagina a Googlebot como un detective minucioso hurgando en tu código. Su proceso va más o menos así:
1. Descarga el HTML.
2. Envía los datos al Servicio de Renderizado Web (WRS), algo así como el laboratorio CSI del rastreo.
3. Descarga todos los recursos que tu página exige —JavaScript, CSS, imágenes y ese widget que nadie sabe por qué está ahí.
4. Construye la página renderizada.
Si tu robots.txt le dice que se mantenga alejado, se encogerá de hombros y seguirá adelante, pero no sin antes hacer una marca mental de que estás siendo complicado. Recuerda, los recursos críticos para renderizar deben ser accesibles. De lo contrario, Googlebot podría renderizar tu página como un lienzo en blanco, y nadie quiere eso en los resultados de búsqueda.
Tus nuevos mejores amigos son la Search console y los logs de servidor
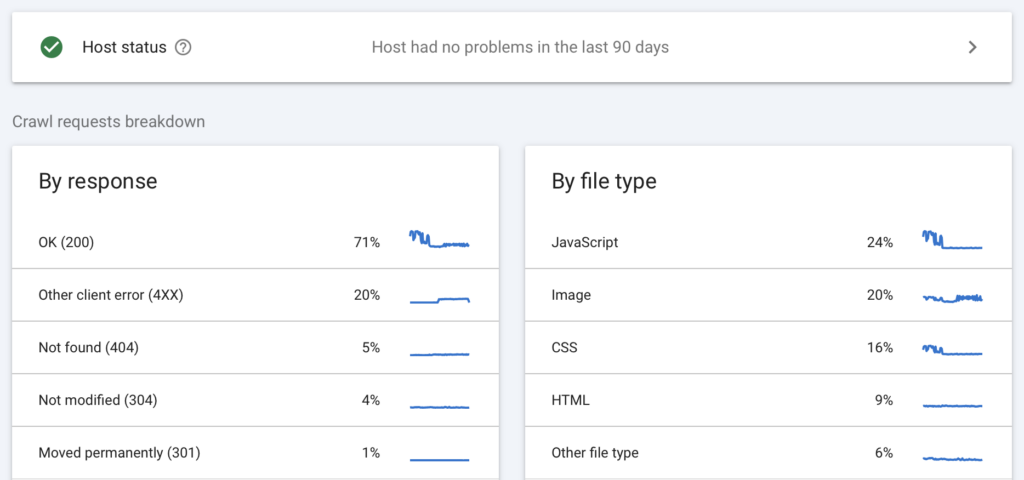
¿Quieres saber qué está haciendo Googlebot? No busques más allá de tus logs de servidor y el reporte de estadísticas de rastreo de Search Console. Esas entradas crípticas son tu ventana al alma del bot. ¿Intentó descargar tu favicon 20 veces la semana pasada? Sí, ahí está. ¿Consumió tu ancho de banda descargando todas tus imágenes dos veces? También está ahí.
Search Console va un paso más allá, dándote un gráfico brillante que desglosa los tipos de recursos que se rastrearon. Piensa en ello como la manera de Google de decir: “Esto es lo que hicimos, y esto es lo que tomamos. De nada”.
Cómo mantener feliz a googlebot (sin perder tu salud mental)
Al final del día, mantener a Googlebot de tu lado no es ciencia cuántica, es sentido común (si, el sentido menos común):
• Usa menos recursos y hazlos más eficientes. Si tu página necesita una docena de scripts para cargar, es hora de replantearte tus prioridades.
• Aloja tus archivos en un CDN o subdominio. Deja que otro se lleve el golpe al presupuesto de rastreo por tus archivos CSS y JavaScript.
• Deja de jugar con parámetros “rompe-caché” a menos que sea absolutamente necesario. Si el contenido no ha cambiado, la URL tampoco debería.
Y, por favor, asegúrate de que tu sitio cargue rápido. Googlebot tiene otros sitios que rastrear y no tiene todo el tiempo del mundo.
Cerrando el ciclo de rastreo
El rastreo no es solo un paseo robótico por tu sitio web. Es un proceso intrincado con reglas, limitaciones y mucho espacio para errores humanos. Entender cómo funciona Googlebot puede ser la diferencia entre un sitio que triunfa en los resultados de búsqueda y uno que se pierde en la oscuridad. Así que cuida tu Crawl Budget como si fuera oro, dale a Googlebot lo que necesita y, tal vez, solo tal vez, te recompensará con ese codiciado lugar en la primera página. O al menos con menos errores 404 en tus logs.


