
Leí varios artículos que popularizan una noción supuestamente nueva y supuestamente importante en SEO: el “umbral de calidad“. No “umbrales de calidad” en plural, EL umbral de calidad. Una noción atribuida a un experto turco, Koray Tuğberk GÜBÜR.
Bueno, no estoy tirando piedras a los que han compartido y comentado las afirmaciones de Koray Tuğberk GÜBÜR, es un experto en las mille hojas argumentativas y en el arte de esconder un discurso pseudocientífico bajo un montón de datos y resultados de pruebas que no demuestran nada.
Les dejo leer el artículo de Koray GÜBÜR en oncrawl.com que desarrolla el concepto.
https://www.oncrawl.com/technical-seo/importance-quality-thresholds-predictive-ranking/
Bueno, veremos que es un tema irrelevante. Y que no tiene sentido crear un nuevo nombre para un comportamiento atribuido a Google que resulta no ajustarse a la realidad. Una realidad que es más compleja y más matizada.
Si haces SEO: necesitas un radar a Bullshit
Por regla general, no dedico mi tiempo a desmentir todas las tonterías que se escriben sobre el SEO: no tendría tiempo suficiente para mis clientes.
Es la famosa ley de Brandolini: “la cantidad de energía necesaria para refutar las tonterías es un orden de magnitud mayor que la necesaria para producirlas.”
The bullshit asimmetry: the amount of energy needed to refute bullshit is an order of magnitude bigger than to produce it.
— Alberto Brandolini (@ziobrando) January 11, 2013
La "Ley de Brandolini" fue inventada por el ingeniero informático italiano Alberto Brandolini
Pero cuando puedo cortar de raíz el nacimiento de un nuevo mito SEO, lo haré. Es mejor hacerlo antes de que se convierta en evangelio en la comunidad, es lo que menos energía cuesta.
Lo hice sobre el Latent Semantic Indexing (un invento de nuestros colegas estadounidenses), o más recientemente sobre WF*IDF (un invento de nuestros colegas alemanes) o la versión de Hubspot/Neil Patel de los Topic Clusters (un invento gringo).
Nota: en México, no somos los últimos en inventar conceptos o métodos.
Bueno, te daré un consejo para identificar temas sospechosos: cuando un concepto de SEO no sale de un país, es una pista de que puede ser mentira. Ok, también podría significar que el resto del mundo aún no se ha enterado, pero según la Navaja de Ockham, la explicación más probable es que no traspase las fronteras porque el argumento que lo sustenta no tiene sentido.
Y aquí, ¿quién habla de “quality threshold” excepto Koray Tuğberk GÜBÜR? Nadie. Ni siquiera en las comunidades SEO y alemanas, que son sus principales cámaras de eco. Otros hablan de que los umbrales de calidad pueden aplicarse en diferentes lugares del motor de búsqueda de Google y, en consecuencia, los umbrales de calidad tienen una definición diferente.
¿Qué es ese supuesto “umbral de calidad”?
Según los exégetas de Koray, existe un “umbral” a partir del cual una determinada “puntuación de calidad” permitiría a una página web aparecer en el índice primario de Google (a diferencia del índice suplementario).
Pues bien, primer problema: la arquitectura de Google ya no incluye esta dicotomía entre un índice primario y un suplementario (o secundario) desde hace… doce años.
Does Google still operate a “supplemental” index @JohnMu? Or is this a relic now as G has tech to keep “main” index fresh etc.
— Mark Williams-Cook = 🅼🅰🆁🅺 🅲🅾🅾🅺 (@thetafferboy) June 26, 2022
El « supplemental index » y el índice primario han desaparecido desde el cambio a la arquitectura Caffeine en 2010, según John Mueller
Podría parar aquí y decir: fin de la historia.
Pero como soy intelectualmente honesto, debo señalar que si los dos índices no existen desde hace tiempo, no significa que la razón que justificaba su existencia haya desaparecido. Y Google probablemente cambió a algo que respetaba la misma lógica.
Cuanto menos probable sea que una página se sitúe en los primeros puestos de los resultados de una búsqueda, menos útil será almacenar todas las puntuaciones de esa página
De hecho, todos los que construyen motores de búsqueda están obsesionados con las limitaciones de rendimiento. Cuando se trata de poder producir una página de resultados en un puñado de milisegundos, cualquier ahorro en la cantidad de datos que hay que calcular o procesar merece la pena.
Es una práctica bastante universal crear bases de datos en las que, frente a cada entrada de la base de datos, se almacena más información (puntuaciones) para las páginas que aparecerán en el top 30 que para las que aparecerán en el top 100.
En resumen, el motor tiene suficiente información para clasificar finamente los 30 primeros, la clasificación es un poco más gruesa en las páginas 4 a 10, y más allá de eso, es un gran desastre.
La probabilidad de que Google siga utilizando este truco en 2022 es bastante alta…
Pero esto significa “predecir” durante la indexación qué páginas son susceptibles aparecer en las primeras posiciones. En los primeros tiempos de Google, los documentos se preordenaban para entrar en el índice en función de su puntuación TF*iDF y quizás en combinación con su Pagerank para los 30 primeros.
Estos mecanismos son descritos aquí:
Indexing The World Wide Web : the journey so far (Pdf)
Ah, aquí hay una noción de “umbral”, pero este umbral no se refiere a una puntuación de calidad.
¿Dónde encontramos estas nociones de umbral de calidad en el algoritmo de Google?
En la práctica, los umbrales se encuentran en todas partes en el algoritmo de Google.
Por ejemplo, hay una puntuación asociada a los umbrales que determina si una página será rastreada e indexada. Esta puntuación se llamaba “Crawl score”, ahora Google habla de “page importance”.
Este sistema se describe en una patente: https://patents.justia.com/patent/20170091324
Pero como todas las patentes, no está claro si Google utiliza este sistema exactamente: sólo sabemos que es una práctica común en los motores de búsqueda.
Además, Google utiliza “clasificadores” en varios lugares del algoritmo. En inteligencia artificial, un clasificador es una función basada en la IA que podrá “clasificar” un item en una casilla. Por ejemplo, decidir si un elemento de contenido tiene una puntuación suficiente para no activar la aplicación de un filtro.
Este tipo de enfoque existe en Panda, Penguin o la actualización Helpful Content. Este tipo de enfoque también se puede encontrar en las herramientas de detección de webspam. Lo interesante de estos cuatro casos es que el análisis se centra cada vez en un aspecto diferente de la calidad.
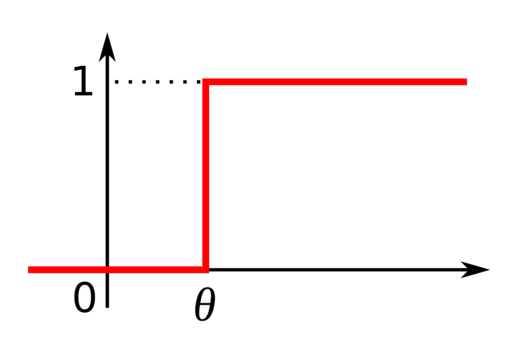
¿Existe una noción de “umbral de calidad” en cada caso?
Para Panda y Penguin, existe una noción de umbral, no necesariamente para el update del Helpful Content.
Así que ten cuidado, no deberías ver umbrales en todas partes. Cuando no vemos un efecto de umbral, es quizás porque no hay umbral. Y cuando creemos ver un efecto de umbral, puede explicarse por un cambio causado por algo distinto al cruce de un umbral.
El « predictive ranking » y la calidad
En el discurso sobre EL umbral de calidad (nótese que Koray Tuğberk GÜBÜR alterna las referencias al “umbral de calidad” en plural y en singular), hace muchas referencias al « predictive ranking ».
En primer lugar, no hay que confundir el « predictive ranking » (la clasificación predictiva) y el « predictive crawling » (el rastreo predictivo). El predictive crawling es un enfoque que se describe en este artículo:
Y mira, hay una noción de umbral. Pero es un método para hacer más eficiente el rastreo de Googlebot.
El “predictive ranking” es una noción que aparece en esta patente de Google:
https://patents.google.com/patent/WO2006062650A1
Como siempre, nuestros amigos de Estados Unidos patentan todas sus ideas, y el hecho de que Google haya presentado esta patente no significa que se utilice.
La idea es “predecir” los documentos que serán seleccionados por un usuario para precargarlos y hacer más fluida la experiencia de búsqueda. Esto es particularmente apropiado para el uso móvil con una conexión deficiente.
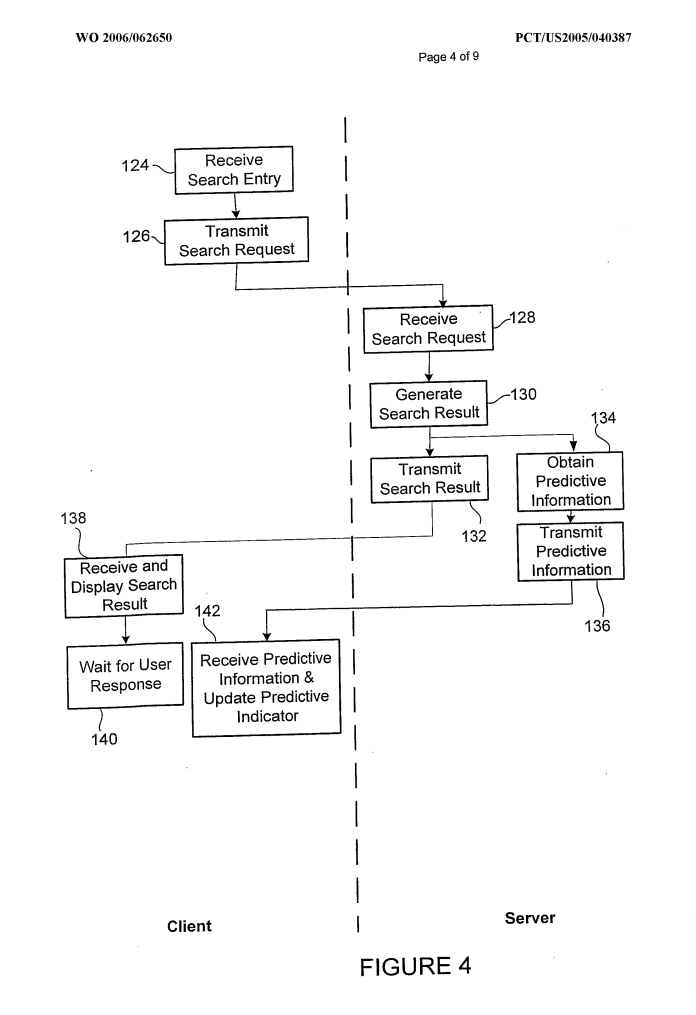
Eso demuestra que no hay ninguna relación entre esta patente, la noción de calidad y, a fortiori, la noción de “umbral de calidad”.
Entonces, ¿qué hace eso aquí en esta historia?
Obviamente, me pregunto, creo que es una confusión con otros conceptos imaginados para mejorar los motores de búsqueda. Como el neural matching o los enfoques como “learning to rank”. Pero su uso en Google es bastante limitado.
Conclusión: umbrales sí, pero EL umbral de calidad no es un concepto accionable en SEO
Así que, para terminar:
- Efectivamente, hay “umbrales” utilizados en muchas partes del funcionamiento de Google.
- Algunos de estos umbrales giran en torno a la noción de calidad, pero están relacionados con varias puntuaciones. He mencionado algunas de ellas, hay otras conocidas, y probablemente otras que Google nunca ha comunicado.
- Por lo tanto, no tenemos un único efecto de umbral, sino varios efectos de umbral cuyos efectos pueden combinarse / compensarse / reforzarse entre sí.
Así que esta noción de “umbral de calidad” único y universal no define ningún indicador real y tangible. Así que nada que pueda medirse o probarse de forma útil.
Y sobre todo, no define nada útil para definir acciones efectivas en SEO.
Esto es diferente si bajamos a un nivel más fino de granularidad, donde se pueden definir recomendaciones más útiles y directamente efectivas.
Así que no intentes optimizar tus páginas según esta vaga noción de umbral de calidad.
E incluso puedes olvidarte del concepto: no hay UN umbral de calidad en el SEO. Pero varios.


